
Executing COBOL programs
Introduction
In this Assignment, you’ll write a few small COBOL programs that will get you familiar with COBOL language. You'll also explore ways in which COBOL programs are compiled and executed directly on z/OS system. Not that ISPF editor is not how you'd normally write the code, IBM Rational Developer is a tool that's used for that. Still, in this course, we'll run COBOL programs via a batch job. You can treat it as a time-travel, this is how it was done in the old days. To get familiar with COBOL basics I strongly recommend: - "Murarch's Mainframe COBOL" book. - "Teach Yourself COBOL In 21 Days" book. - http://www.csis.ul.ie/cobol/course/ - http://www.mainframestechhelp.com/tutorials/cobol/ - And of course: “Enterprise COBOL for z/OS: Language Reference”. You can use exercises presented here as a supplement to the materials mentioned above or you can take the shortcut and focus only on the exercises clarifying the details along the way.
Tasks
![]() 1. Write a program that displays “Hello World!” string.
- Compile and run the program via a batch job.
- Compile the program and then run it under TSO.
1. Write a program that displays “Hello World!” string.
- Compile and run the program via a batch job.
- Compile the program and then run it under TSO.
![]() 2. Write a program that defines two variables A and B and multiplies them:
- The result should be saved in variable C and then displayed.
- A and B should be able to store numbers 0.00 – 999.99 while C: 0.000 – 99999.999.
- Accept both variables via SYSIN.
2. Write a program that defines two variables A and B and multiplies them:
- The result should be saved in variable C and then displayed.
- A and B should be able to store numbers 0.00 – 999.99 while C: 0.000 – 99999.999.
- Accept both variables via SYSIN.
![]() 3. Run the program written in Task#2 via:
- JCL EXEC statement.
- CLIST.
- REXX.
3. Run the program written in Task#2 via:
- JCL EXEC statement.
- CLIST.
- REXX.
![]() 4. Write a program with following paragraphs:
- OPT-SELECT – It accepts user input from SYSIN and on its basis executes a specific paragraph.
- If the input is 1 "OPTION-1" paragraph is executed, if 2 "OPTION-2" paragraph is executed, 0 should end the program. If any other input is given program should execute "INPUT-ERROR" paragraph and end.
- All paragraphs should only display a message about an executed paragraph.
- Use IF statement for condition testing.
4. Write a program with following paragraphs:
- OPT-SELECT – It accepts user input from SYSIN and on its basis executes a specific paragraph.
- If the input is 1 "OPTION-1" paragraph is executed, if 2 "OPTION-2" paragraph is executed, 0 should end the program. If any other input is given program should execute "INPUT-ERROR" paragraph and end.
- All paragraphs should only display a message about an executed paragraph.
- Use IF statement for condition testing.
![]() 5. Write a program that accepts data passed via parameter, for example, JCL PARM keyword:
- If the parameter was passed it displays "Success" and the value of the parameter.
- If no parameter was passed the program displays "Failure" and ends.
5. Write a program that accepts data passed via parameter, for example, JCL PARM keyword:
- If the parameter was passed it displays "Success" and the value of the parameter.
- If no parameter was passed the program displays "Failure" and ends.
![]() 6. Modify program from Task#4. This time pass the option via parameter, not SYSIN and use EVALUATE statement instead of IF.
6. Modify program from Task#4. This time pass the option via parameter, not SYSIN and use EVALUATE statement instead of IF.
![]() 7. Write a program with an interactive user menu, here is the program structure:
- Main panel - three options (Display a number, Display a word, End the program).
- Sub-menu for numbers - four options (Display 1234, Display 321, Return to the main menu, End the program).
- Sub-menu for words - four options (Display "COBOL", Display "RULES", Return to the main menu, End the program).
- If user selects a non-existing item the menu should be repeated.
- Test the program using SYSIN in JCL code, then execute it interactively under TSO.
7. Write a program with an interactive user menu, here is the program structure:
- Main panel - three options (Display a number, Display a word, End the program).
- Sub-menu for numbers - four options (Display 1234, Display 321, Return to the main menu, End the program).
- Sub-menu for words - four options (Display "COBOL", Display "RULES", Return to the main menu, End the program).
- If user selects a non-existing item the menu should be repeated.
- Test the program using SYSIN in JCL code, then execute it interactively under TSO.
![]() 8. Run the program written in Task#7 in following ways. Apply appropriate modifications if needed.
- With batch job passing input data via SYSIN DD statement.
- With batch job passing input data via PARMDD keyword.
- Under your TSO user session passing input data via the parameter.
- Under your TSO user session passing input data interactively via SYSIN.
- As above but using commands saved in CLIST.
- With REXX script passing input data with SYSIN.
- With REXX script passing input data interactively.
- With batch job passing input data via WTORs.
8. Run the program written in Task#7 in following ways. Apply appropriate modifications if needed.
- With batch job passing input data via SYSIN DD statement.
- With batch job passing input data via PARMDD keyword.
- Under your TSO user session passing input data via the parameter.
- Under your TSO user session passing input data interactively via SYSIN.
- As above but using commands saved in CLIST.
- With REXX script passing input data with SYSIN.
- With REXX script passing input data interactively.
- With batch job passing input data via WTORs.
Hint 1
Read about IGYWC, IGYWCL and IGYWCLG JCL procedures in “Enterprise COBOL for z/OS: Programming Guide”. To execute the program via TSO you'll need to use CALL command. Check “TSO/E: Command Reference”.
Hint 3
"Executing Utilities without JCL" assignment in "Utilities" tab will be helpful here.
Hint 5
To pass data via parameter you'll need to use LINKAGE SECTION in DATA DIVISION. Also, check USING keyword for PROCEDURE DIVISION.
Hint 7
To run a program interactively you'll need to allocate SYSIN to your TSO user session and then run the program.
Hint 8
To issue WTORs from COBOL programs you should take a look at the description of ACCEPT function. It's present in "Enterprise COBOL for z/OS: Language Reference".
Solution 1
JCL for running COBOL program:
//RUNCOBOL EXEC IGYWCG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. TEMPLATE. DATA DIVISION. PROCEDURE DIVISION. DISPLAY "Hello World!". STOP RUN.
There are a few JCL procedures always shipped with COBOL compiler, for example, “Enterprise COBOL for z/OS”. They can be used for compiling, linking and running COBOL programs. Their names start with “IGYW*” prefix. The suffix of IGYW* procedures is made out of a combination of three letters: - C – Compile - L – Link - G – Go So to execute our program we need to use either IGYWCG (Compile & Go) or IGYWCLG (Compile, Link & Go). The above program doesn't include any other modules or class definitions, therefore link step is optional. Also, notice column numbers where particular statement start. COBOL statements are partially recognized on the basis of columns at which they start: - 1-6 - Enumeration. It can be left blank. - 7 - Indicator. It's used for indicating special lines, for example, comments or continuations. - 8-11 - Area A. In this are Divisions, Sections, and Paragraphs should start. There are also few other items that use this area. - 12-72 - Area B. This is where the actual program instructions are coded. To execute it via TSO we need compiled the program, to do that we can use IGYWCL procedure:
//RUNCOBOL EXEC IGYWCL //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP101) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP101. DATA DIVISION. PROCEDURE DIVISION. DISPLAY "Hello World!". STOP RUN.
You can also use this code with IGYWCLG procedure, this way you'll run the program and save it's compiled version at the same time. Now you can run the program with TSO command: CALL 'JSADEK.MY.COBOL.LINKLIB(MP101)' ASIS ASIS means that the parameters passed to the program won't be translated to uppercase. In this example, it doesn't matter but when a program accepts any parameters it's a good habit to always use ASIS keyword.
Solution 2
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP102) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP102. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC 9(3)V99. 01 B PIC 9(3)V99. 01 C PIC 9(5)V999. PROCEDURE DIVISION. DISPLAY "Specify first number:". ACCEPT A DISPLAY "Specify second number:". ACCEPT B COMPUTE C = A * B. DISPLAY C. STOP RUN. //GO.SYSIN DD * 3 5
As you can see values passed to the program via ACCEPT instruction must be included in "GO.SYSIN" DD statement. In the above example, result from the program is equal to 50000000. Why? - First problem: COBOL language is very column oriented. Variables A and B have three digits so three characters are taken from the input "3 " and "5 ". COBOL interprets blanks as zeros, in result, our inputs are recognized as 300 and 500. - Second problem: Numeric variables are computed correctly but displayed without the decimal point so instead of 50000.000 we see 50000000. - Third problem: The result should be 150000, but it is 50000. C variable can store only 5 digits (before the decimal point). In such situation, COBOL truncates characters. - Fourth problem: The decimal point is not part of the numeric data and won't be accepted via SYSIN, so if you want to pass to the program 4.93 you'd have to pass it as 004930. To get the proper results we need to specify A & B as 003 & 005, then we'll get 00015000. If any of this seems confusing to you, well, welcome to COBOL. So we have two main problems that need to be addressed here: - The way in which result is displayed. - Possible overflows. If a numeric value is truncated it's usually better to end program in error than to work on incorrect data. Following version addresses those problems:
IDENTIFICATION DIVISION. PROGRAM-ID. MP102. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC 9(3)V99. 01 B PIC 9(3)V99. 01 C PIC 9(5)V999. 01 C-EDITED PIC Z(4)9.999. 01 C-OVERFLOW PIC X. PROCEDURE DIVISION. DISPLAY "Specify first number:". ACCEPT A DISPLAY "Specify second number:". ACCEPT B COMPUTE C = A * B ON SIZE ERROR MOVE "Y" TO C-OVERFLOW. IF C-OVERFLOW = "Y" DISPLAY "Overflow while computing (-A-B-C-): (" A "-" B "-" C "-)" STOP RUN. MOVE C TO C-EDITED. DISPLAY C. DISPLAY C-EDITED. STOP RUN.
As you can see we have two additional variables C-EDITED and C-OVERFLOW. The first one is used for displaying C with the decimal point and without leading zeros. The second one indicates if any computation error appeared during COMPUTE operation. Overflow is one of the errors you can check with ON SIZE ERROR instruction. Also, when you use ON SIZE ERROR the result of the operation is not saved in C if it fails. We need both C and C-EDITED variables because formatted numerics are actually different data type "NUMERIC-EDITED" and cannot be used by COMPUTE function. For example instruction: "COMPUTE C = 2 * C-EDITED." Ends with the following error: "IGYPA3074-S "C-EDITED (NUMERIC-EDITED)" was not numeric, but was a sender in an arithmetic expression. The statement was discarded."
Solution 3
JCL code:
//JOBLIB DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB //STEP01 EXEC PGM=MP102 //SYSIN DD * 300 050 //SYSOUT DD DSN=&SYSUID..COBOL.MPOUT102,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),RECFM=VB,BLKSIZE=27998,LRECL=124
If you skip SYSOUT DD stement the output will be written to the spool under SYSOUT name. CLIST:
PROC 0 CONTROL ASIS ALLOC DD(SYSIN) NEW DELETE LRECL(80) RECFM(F,B) BLKSIZE(8000) REUSE OPENFILE SYSIN OUTPUT SET SYSIN = &STR(300) PUTFILE SYSIN SET SYSIN = &STR(050) PUTFILE SYSIN CLOSFILE SYSIN CALL 'JSADEK.MY.COBOL.LINKLIB(MP102)' FREE FI(SYSIN) EXIT
REXX:
/* REXX */ ADDRESS TSO "ALLOC DD(SYSIN) NEW DELETE LRECL(80) RECFM(F,B) BLKSIZE(8000) REUSE" INPUT.1 = "300" INPUT.2 = "050" INPUT.0 = 2 "EXECIO * DISKW SYSIN (STEM INPUT. FINIS" "CALL 'JSADEK.MY.COBOL.LINKLIB(MP102)'" "FREE FI(SYSIN)" EXIT
Solution 4
There are basically two ways in which you can write such program, here is the first one. Note that you shouldn't use this version, the second technique presents how COBOL is normally coded. This one is here to point out behavior of execution flow in COBOL.
IDENTIFICATION DIVISION. PROGRAM-ID. MP104. DATA DIVISION. WORKING-STORAGE SECTION. 01 OPTION PIC 9(3). PROCEDURE DIVISION. OPT-SELECT. DISPLAY "Please select option..." ACCEPT OPTION. DISPLAY "Selected option: " OPTION. IF OPTION = 1 PERFORM OPTION-1 ELSE IF OPTION = 2 PERFORM OPTION-2 ELSE IF OPTION = 0 PERFORM END-PROGRAM ELSE PERFORM INPUT-ERROR. DISPLAY "after loop...". PERFORM CONTINUE-PROGRAM. OPTION-1. DISPLAY "Option 1 was selected". OPTION-2. DISPLAY "Option 2 was selected". END-PROGRAM. DISPLAY "Bye". STOP RUN. INPUT-ERROR. DISPLAY "Input processing error". STOP RUN. CONTINUE-PROGRAM. DISPLAY "Some further processing". STOP RUN.
Notice the execution flow of this program: - IF statement tests the condition and executes appropriate paragraph. - After the paragraph is executed, the program flow goes back to the place after IF statement. - Because of that, we need to add additional paragraph CONTINUE program and go to it straight after the IF. This way we skip paragraphs related to IF statement and can continue with the rest of the program. Without "PERFORM CONTINUE-PROGRAM." instruction we would get:
Please select option... Selected option: 001 Option 1 was selected after loop... Option 1 was selected Option 2 was selected Bye
So OPTION-1 was executed by the IF statement and program continued after the IF statement executing again OPTION-1 and other paragraphs until "STOP RUN." instruction was encountered in "END-PROGRAM" paragraph. The second, correct version:
IDENTIFICATION DIVISION. PROGRAM-ID. MP104. DATA DIVISION. WORKING-STORAGE SECTION. 01 OPTION PIC 9(3). PROCEDURE DIVISION. OPT-SELECT. DISPLAY "Please select option..." ACCEPT OPTION. DISPLAY "Selected option: " OPTION. IF OPTION = 1 PERFORM OPTION-1 ELSE IF OPTION = 2 PERFORM OPTION-2 ELSE IF OPTION = 0 PERFORM END-PROGRAM ELSE PERFORM INPUT-ERROR. DISPLAY "Some further processing". STOP RUN. OPTION-1. DISPLAY "Option 1 was selected". OPTION-2. DISPLAY "Option 2 was selected". END-PROGRAM. DISPLAY "Bye". STOP RUN. INPUT-ERROR. DISPLAY "Input processing error". STOP RUN.
Now Paragraphs executed from inside IF statement are clearly separated from the rest of the program by STOP RUN instruction. It's also worth mentioning that you can see here simplified IF statement. Following code presents full version of the same code, it seems messier but shows better the logic of IF statement:
IF OPTION = 1 PERFORM OPTION-1 ELSE IF OPTION = 2 PERFORM OPTION-2 ELSE IF OPTION = 0 PERFORM END-PROGRAM ELSE PERFORM INPUT-ERROR END-IF END-IF END-IF.
It's a good habit to always use this syntax, you'll avoid some problems with IF logic this way.
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP105. DATA DIVISION. LINKAGE SECTION. 01 PARMDATA. 05 PARML PIC 9(4) USAGE COMP. 05 PARMD PIC X(255). PROCEDURE DIVISION USING PARMDATA. IF PARML > 0 DISPLAY "Success" DISPLAY "Parm lenght: " PARML DISPLAY "Parm = " PARMD ELSE DISPLAY "Failure" STOP RUN. DISPLAY "Some further processing...". STOP RUN.
Passing parameters to the program require two things: - A variable definition in LINKAGE SECTION. - Referencing those variables via USING keyword in the PROCEDURE DIVISION. Now you can execute the program with use of JCL:
//JOBLIB DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB //STEP01 EXEC PGM=MP105,PARM='My beautiful code'
Or TSO command: "CALL 'JSADEK.MY.COBOL.LINKLIB(MP105)' 'My beautiful code'". Notice that in case of CALL command argument was translated to the upper-case string. ASIS keyword fixed the problem: "CALL 'JSADEK.MY.COBOL.LINKLIB(MP105)' 'My beautiful code' ASIS" Important: Name of the parameter doesn't matter. The parameter is a variable-length record. That's why we could define "PIC 9(4) USAGE COMP" variable that stores its length. As you may remember from JCL Assignments the first four bytes of data sets with record organization V store the length of the particular record. It's the same thing here, except the RDF here has two not four bytes.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP106. DATA DIVISION. LINKAGE SECTION. 01 PARM. 05 OPTIONL PIC 9(4) USAGE COMP. 05 OPTION PIC 9(3). PROCEDURE DIVISION USING PARM. OPT-SELECT. DISPLAY "Selected option: >" OPTION "<". EVALUATE OPTION WHEN 1 PERFORM OPTION-1 WHEN 2 PERFORM OPTION-2 WHEN 0 PERFORM END-PROGRAM WHEN OTHER PERFORM INPUT-ERROR END-EVALUATE. DISPLAY "after loop...". PERFORM CONTINUE-PROGRAM. OPTION-1. DISPLAY "Option 1 was selected". OPTION-2. DISPLAY "Option 2 was selected". END-PROGRAM. DISPLAY "Bye". STOP RUN. INPUT-ERROR. DISPLAY "Input processing error". STOP RUN. CONTINUE-PROGRAM. DISPLAY "Some further processing". STOP RUN.
Parameters passed to the program this way also have to be formatted accordingly to the PICTURE definition, for example: "CALL 'JSADEK.MY.COBOL.LINKLIB(MP106)' '001'"
Solution 7
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP107. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC 9 VALUE 9. 01 K1 PIC 9(4). 01 K2 PIC 9(4). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM VARYING K1 FROM 1 BY 1 UNTIL A = 0 PERFORM DISPLAY-MAIN-MENU IF A = 1 PERFORM VARYING K2 FROM 1 BY 1 UNTIL A = 0 OR A = 9 PERFORM DISPLAY-NUM-MENU IF A = 1 DISPLAY 1234 END-IF IF A = 2 DISPLAY 321 END-IF END-PERFORM END-IF IF A = 2 PERFORM VARYING K2 FROM 1 BY 1 UNTIL A = 0 OR A = 9 PERFORM DISPLAY-WORD-MENU IF A = 1 DISPLAY "COBOL" END-IF IF A = 2 DISPLAY "RULES" END-IF END-PERFORM END-IF END-PERFORM. END-PROGRAM. STOP RUN. DISPLAY-MAIN-MENU. MOVE 9 TO A. DISPLAY "Select:" DISPLAY "- 1 - Display a number.". DISPLAY "- 2 - Display a word.". DISPLAY "- 0 - End the program.". ACCEPT A. DISPLAY-NUM-MENU. MOVE 9 TO A. DISPLAY "Select:" DISPLAY "- 1 - Display 1234.". DISPLAY "- 2 - Display 321.". DISPLAY "- 9 - Go back to main menu.". DISPLAY "- 0 - End the program.". ACCEPT A. DISPLAY-WORD-MENU. MOVE 9 TO A. DISPLAY "Select:" DISPLAY "- 1 - Display COBOL.". DISPLAY "- 2 - Display RULES.". DISPLAY "- 9 - Go back to main menu.". DISPLAY "- 0 - End the program.". ACCEPT A.
The easiest way to realize a program like that is with PERFORM loops. It's worth mentioning here, that not initialized numerics are recognized as zeros so this program contains a minor bug, it will end if a user enters 0 and also if no input is given. A simple experiment proves it:
A IS NOT INITIALIZED A = >>> <<< A RECOGNIZED AS 0 A RECOGNIZED AS LOW-VALUE A IS INITIALIZED A = >>>0<<< A RECOGNIZED AS 0
The tricky thing about this program is executing in under TSO. To do so you need to allocate SYSIN to your TSO session and then execute the program, here are TSO commands to do so: "ALLOC DA(*) FI(SYSIN)" "CALL 'JSADEK.MY.COBOL.LINKLIB(MP107)'" "FREE FI(SYSIN)"
Solution 8
- With batch job passing input data via SYSIN DD statement. This is the simplest way, you already did it many times:
//JOBLIB DD DISP=SHR,DSN=JSADEK.MY.COBOL.LINKLIB //RUNCOBOL EXEC PGM=MP108 //SYSOUT DD SYSOUT=* //SYSIN DD * 1 2 1 2 9 2 2 1 9 0
- With batch job passing input data via PARM keyword.
//JOBLIB DD DISP=SHR,DSN=JSADEK.MY.COBOL.LINKLIB //RUNCOBOL EXEC PGM=MP108V2,PARM='1212922190' //SYSOUT DD SYSOUT=*
Code modification:
... WORKING-STORAGE SECTION. 01 A PIC 9 VALUE 9. 01 K1 PIC 9(4). 01 K2 PIC 9(4). 01 PARM-K PIC 9(2) VALUE 1. LINKAGE SECTION. 01 PARM. 05 PARML PIC 9(4) COMP. 05 PARMD PIC 9 OCCURS 1 TO 999 TIMES DEPENDING ON PARML. PROCEDURE DIVISION USING PARM. ... * ACCEPT A in menu paragraphs replaced with: MOVE PARMD(PARM-K) TO A. COMPUTE PARM-K = PARM-K + 1.
- Under your TSO user session passing input data via parameter. CALL 'JSADEK.MY.COBOL.LINKLIB(MP108V2)' '1212922190' - Under your TSO user session passing input data interactively via SYSIN. "ALLOC DA(*) FI(SYSIN)" "CALL 'JSADEK.MY.COBOL.LINKLIB(MP108)'" "FREE FI(SYSIN)" This way of executing COBOL program is shown here to make this assignment more complete. In reality, this way is never used on z/OS. The only case when it may be useful is for creating small interactive programs that simplify or automatize some of your daily activities. In this case, it's best to execute such programs via CLIST as shown below. - As above but using commands saved in CLIST.
PROC 0 CONTROL ASIS ALLOC DA(*) FI(SYSIN) CALL 'JSADEK.MY.COBOL.LINKLIB(MP108)' FREE FI(SYSIN) EXIT
- With REXX script passing input data with SYSIN.
/* REXX */ ADDRESS TSO "ALLOC DD(SYSIN) NEW DELETE LRECL(80) RECFM(F,B) BLKSIZE(8000) REUSE" INPUT.1 = 1 INPUT.2 = 2 INPUT.3 = 1 INPUT.4 = 2 INPUT.5 = 9 INPUT.6 = 2 INPUT.7 = 2 INPUT.8 = 1 INPUT.9 = 9 INPUT.10 = 0 INPUT.0 = 10 "EXECIO * DISKW SYSIN (STEM INPUT. FINIS" "CALL 'JSADEK.MY.COBOL.LINKLIB(MP108)'" "FREE FI(SYSIN)" EXIT
- With REXX script passing input data interactively.
/* REXX */ ADDRESS TSO "ALLOC DA(*) FI(SYSIN)" "CALL 'JSADEK.MY.COBOL.LINKLIB(MP108)'" "FREE FI(SYSIN)" EXIT
- With batch job passing input data via WTORs. The only code modification needed is the replacement of "ACCEPT A." with "ACCEPT A FROM CONSOLE.". Now instead of reading SYSIN program sends a WTOR. Operator response is saved into A variable. In this example, it doesn't make much sense but the ability to use WTORs in your programs may become handy in the future. Now you know how to execute and pass data to COBOL program in all kinds of ways. Of course, most often you'll use data sets which will be discussed later, sometimes parameters or SYSIN, rarely WTORs and even less often SYSIN allocated to your TSO user session. Still, as a COBOL programmer, you need to know all those methods and use the most appropriate one for your task.
PERFORM & GO TO statements
Introduction
PERFORM statement is probably the first COBOL statement you should get familiar with. There is no instruction that works like PERFORM in other programming languages. It has many versions, the most basic of them executes a chosen paragraph but PERFORM also serves as an equivalent to "for" and "while" loops known from other languages. In this Assignment you'll get familiar with most important variations of this instruction and compare it with GO TO statement.
Tasks
![]() 1. Write a program with three paragraphs:
- Use LINES JOB parameter to prevent the program from producing too large output.
- In each paragraph include DISPLAY function so you know which were executed.
- Use PERFORM statement from the second paragraph to execute 1st and then the 3rd paragraph.
- Use GO TO statement in the first paragraph to execute 3rd and then the 1st paragraph.
- Use GO TO statement in the second paragraph to execute 1st and then the 3rd paragraph.
- Compare the results.
1. Write a program with three paragraphs:
- Use LINES JOB parameter to prevent the program from producing too large output.
- In each paragraph include DISPLAY function so you know which were executed.
- Use PERFORM statement from the second paragraph to execute 1st and then the 3rd paragraph.
- Use GO TO statement in the first paragraph to execute 3rd and then the 1st paragraph.
- Use GO TO statement in the second paragraph to execute 1st and then the 3rd paragraph.
- Compare the results.
![]() 2. Write a program with 5 paragraphs:
- The first one is the main program logic.
- The next three paragraph ask the user for the partial information about him: full name, age & favourite colour respectively.
- The last paragraph check which data (name/age/colour) was specified and displays it.
- Use a single PERFORM statement to execute paragraphs 2-4, then 2-3.
2. Write a program with 5 paragraphs:
- The first one is the main program logic.
- The next three paragraph ask the user for the partial information about him: full name, age & favourite colour respectively.
- The last paragraph check which data (name/age/colour) was specified and displays it.
- Use a single PERFORM statement to execute paragraphs 2-4, then 2-3.
![]() 3. Modify program from Task#2. This time accept and display data about 4 people.
3. Modify program from Task#2. This time accept and display data about 4 people.
![]() 4. Write a program that calculates factorial of a number:
- Consider overflows.
- Create five versions of this program, each version should use a different type of loop: PERFORM VARYING, PERFORM VARYING with TEST AFTER, PERFORM TIMES, PERFORM UNTIL and PERFORM with GO TO.
4. Write a program that calculates factorial of a number:
- Consider overflows.
- Create five versions of this program, each version should use a different type of loop: PERFORM VARYING, PERFORM VARYING with TEST AFTER, PERFORM TIMES, PERFORM UNTIL and PERFORM with GO TO.
![]() 5. Write a program that displays a line of text "This is N iteration" where N is the number of the loop iteration. Define iterator as PIC 9. Run the program in three conditions:
- 0 iterations
- 3 iterations
- 9 iterations
5. Write a program that displays a line of text "This is N iteration" where N is the number of the loop iteration. Define iterator as PIC 9. Run the program in three conditions:
- 0 iterations
- 3 iterations
- 9 iterations
Solution 1
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP201. ENVIRONMENT DIVISION. DATA DIVISION. PROCEDURE DIVISION. PARAGRAPH-1. DISPLAY "PARAGRAPH 1 EXECUTED". PARAGRAPH-2. DISPLAY "PARAGRAPH 2 EXECUTED". PERFORM PARAGRAPH-1. PERFORM PARAGRAPH-3. PARAGRAPH-3. DISPLAY "PARAGRAPH 3 EXECUTED". PROGRAM-END. DISPLAY "PROGRAM ENDS". STOP RUN.
As you can see PERFORM statement executes paragraphs in form of procedures, in other words, execution flow goes to the paragraph specified by the PERFORM statement and after it ends it goes back to the line after the PERFORM. GO TO statement is different, it alters execution flow of the program. In the below example program goes straight to the 3rd paragraph and never goes back:
... PARAGRAPH-1. DISPLAY "PARAGRAPH 1 EXECUTED". GO TO PARAGRAPH-3. GO TO PARAGRAPH-1. ...
Below example presents one of the risks of using GO TO statement:
... PARAGRAPH-2. DISPLAY "PARAGRAPH 2 EXECUTED". GO TO PARAGRAPH-1. GO TO PARAGRAPH-3. ...
Now the program will execute paragraph 1 & 2 infinitely. That's why we needed LINES keyword in the job. Basically, you should never use GO TO statement in your programs, it can create problems as the one above, it makes the program harder to analyze and overall it's a sign of a bad design, there is no case in which GO TO is the best solution. Having said that, you must know how it behaves in case you'll see it in some old source code.
Solution 2
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP202. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 FULL-NAME PIC X(60). 01 AGE PIC 9(3). 01 FAV-COLOUR PIC X(20). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-FULL-NAME THROUGH ACCEPT-FAV-COLOUR. PERFORM DISPLAY-DATA. STOP RUN. ACCEPT-FULL-NAME. DISPLAY "Give me your name". ACCEPT FULL-NAME. ACCEPT-AGE. DISPLAY "Give me your age". ACCEPT AGE. ACCEPT-FAV-COLOUR. DISPLAY "What's your favorite colour?" ACCEPT FAV-COLOUR. DISPLAY-DATA. IF FULL-NAME NOT = LOW-VALUES DISPLAY "Hi " FULL-NAME. IF AGE NOT = LOW-VALUES DISPLAY "You're " AGE "? Sooooo old.". IF FAV-COLOUR NOT = LOW-VALUES DISPLAY FAV-COLOUR "... really, so charming...".
The above program demonstrates how you can use PERFORM statement to execute many subsequent paragraphs.
Solution 3
COBOL code:
... MAIN-LOGIC. PERFORM ACCEPT-FULL-NAME THROUGH DISPLAY-DATA 4 TIMES. STOP RUN. ...
Solution 4
PERFORM VARYING version:
IDENTIFICATION DIVISION. PROGRAM-ID. MP204. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC 9(2) VALUE 0. 01 K PIC 9(2). 01 RESULT PIC 9(18). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM CALCULATE-FACTORIAL THROUGH DISPLAY-RESULT 20 TIMES. STOP RUN. CALCULATE-FACTORIAL. MOVE 1 TO RESULT. COMPUTE A = A + 1. PERFORM VARYING K FROM 1 BY 1 UNTIL K > A COMPUTE RESULT = RESULT * K ON SIZE ERROR PERFORM OVERFLOW-ERROR END-COMPUTE END-PERFORM. DISPLAY-RESULT. DISPLAY "Factorial of " A " is " RESULT. OVERFLOW-ERROR. DISPLAY "Overflow on number " K. STOP RUN.
PERFORM VARYING with TEST AFTER version:
... CALCULATE-FACTORIAL. MOVE 1 TO RESULT. COMPUTE A = A + 1. PERFORM TEST AFTER VARYING K FROM 1 BY 1 UNTIL K = A COMPUTE RESULT = RESULT * K ON SIZE ERROR PERFORM OVERFLOW-ERROR END-COMPUTE END-PERFORM. ...
With TEST AFTER loop tests the condition at the end of the loop. With it, you can be sure that the loop will be executed at least once. In this example, we must change '>' operator to '=' otherwise the loop will be executed 11 times instead of 10. PERFORM TIMES version:
... CALCULATE-FACTORIAL. MOVE 1 TO RESULT. COMPUTE A = A + 1. MOVE 0 TO K. PERFORM A TIMES COMPUTE K = K + 1 COMPUTE RESULT = RESULT * K ON SIZE ERROR PERFORM OVERFLOW-ERROR END-COMPUTE END-PERFORM. ...
PERFORM UNTIL version:
... CALCULATE-FACTORIAL. MOVE 1 TO RESULT. COMPUTE A = A + 1. MOVE 0 TO K. PERFORM UNTIL K > A COMPUTE K = K + 1 COMPUTE RESULT = RESULT * K ON SIZE ERROR PERFORM OVERFLOW-ERROR END-COMPUTE END-PERFORM. ...
GO TO version:
IDENTIFICATION DIVISION. PROGRAM-ID. MP204. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC 9(2) VALUE 0. 01 K PIC 9(2). 01 RESULT PIC 9(18). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM CALCULATE-FACTORIAL THROUGH DISPLAY-RESULT 20 TIMES. STOP RUN. CALCULATE-FACTORIAL. MOVE 1 TO RESULT. COMPUTE A = A + 1. MOVE 0 TO K. PERFORM ITERATION. DISPLAY-RESULT. DISPLAY "Factorial of " A " is " RESULT. ITERATION. COMPUTE K = K + 1. COMPUTE RESULT = RESULT * K ON SIZE ERROR PERFORM OVERFLOW-ERROR. IF K < A GO TO ITERATION. OVERFLOW-ERROR. DISPLAY "Overflow on number " K. STOP RUN.
Of course GO TO version should be never used, it is presented here for completion.
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP205. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 N PIC 99. 01 K PIC 9. PROCEDURE DIVISION. MAIN-LOGIC. ACCEPT N. DISPLAY "I will display " N " lines.". PERFORM VARYING K FROM 1 BY 1 UNTIL K > N DISPLAY "This is " K " iteration." END-PERFORM. STOP RUN.
This small program demonstrates one of the errors that can appear while using loops. The problem appears if you specify number 9 or higher. After the 9th iteration K should be incremented to 10, tested against N and since it is higher the loop ends. But our iterator K has "PIC 9" definition, the moment it is incremented to 10 the left digit is truncated and K=0.
Structures and tables
Introduction
One of the main strengths of COBOL language is the efficiency and ease it processes tabular data. You can easily define a structure that represents a record in a file and then process it as a whole or focus on specific fields. In this Assignment, you'll learn how to use structures and how to organize variables in tables.
Tasks
![]() 1. Write a program that accepts four values via SYSIN: Race, Name, Age, Owner. Those variables should be part of a structure called Dog. Display each of those variables and their size, then display the entire Dog record, also with its size.
1. Write a program that accepts four values via SYSIN: Race, Name, Age, Owner. Those variables should be part of a structure called Dog. Display each of those variables and their size, then display the entire Dog record, also with its size.
![]() 2. Create a program that accepts three values as a parameter: Name, Age and Gender and displays them.
- This time display length of the data in those variables, not their size.
2. Create a program that accepts three values as a parameter: Name, Age and Gender and displays them.
- This time display length of the data in those variables, not their size.
![]() 3. Write a program that sorts 5 given numbers:
- Use one single dimensional table.
- Sort numbers manually using loops.
3. Write a program that sorts 5 given numbers:
- Use one single dimensional table.
- Sort numbers manually using loops.
![]() 4. Modify the program from Task#3:
- This time sort words instead of numbers.
- Declare the table dynamically so the first variable passed via SYSIN defines how many words can be stored in it.
4. Modify the program from Task#3:
- This time sort words instead of numbers.
- Declare the table dynamically so the first variable passed via SYSIN defines how many words can be stored in it.
![]() 5. Write a program that calculates and displays multiplication table. The size of the table should be specified as a parameter.
5. Write a program that calculates and displays multiplication table. The size of the table should be specified as a parameter.
![]() 6. Write a program that accepts data about car model in form of a structure, here is the list of fields that needs to be accepted along with sample data.
- Brand (Audi)
- Model (A4)
- Model generation (B5, B6, B7, B8, B9)
- Production years for generation (1995-2001, 2000-2006, 2004-2009, 2007-2015, 2015-now)
- Version (For B9 generation: Avant, Limousine, S4 Avant, S4 Limousine, Allroad Quattro, RS4 Avant)
- Engine version
- Top speed
- Acceleration (0-100 km/h)
- HP (Horse Power)
- Other engine related parameters (car weight, petrol consumption etc. stored a table with 'name', 'unit' and 'value' fields)
- Model parameters stored as a table (height, width etc.)
- Equipment versions
- Car equipment in table with four columns (name, description)
- List of version in which particular equipment item is included.
Don't code the logic for accepting this data via SYSIN, simply assign it by MOVE statement and display it.
6. Write a program that accepts data about car model in form of a structure, here is the list of fields that needs to be accepted along with sample data.
- Brand (Audi)
- Model (A4)
- Model generation (B5, B6, B7, B8, B9)
- Production years for generation (1995-2001, 2000-2006, 2004-2009, 2007-2015, 2015-now)
- Version (For B9 generation: Avant, Limousine, S4 Avant, S4 Limousine, Allroad Quattro, RS4 Avant)
- Engine version
- Top speed
- Acceleration (0-100 km/h)
- HP (Horse Power)
- Other engine related parameters (car weight, petrol consumption etc. stored a table with 'name', 'unit' and 'value' fields)
- Model parameters stored as a table (height, width etc.)
- Equipment versions
- Car equipment in table with four columns (name, description)
- List of version in which particular equipment item is included.
Don't code the logic for accepting this data via SYSIN, simply assign it by MOVE statement and display it.
![]() 7. Define a structure that represents a message:
- Inside the message define: constants (FILLER), alphanumeric, numeric, numeric-edited and COMP data types.
- Assign values to all variables.
- Display the entire message.
- Display numeric-comp field.
- Move some long string directly to the structure.
- Display the entire message.
- Display numeric fields.
7. Define a structure that represents a message:
- Inside the message define: constants (FILLER), alphanumeric, numeric, numeric-edited and COMP data types.
- Assign values to all variables.
- Display the entire message.
- Display numeric-comp field.
- Move some long string directly to the structure.
- Display the entire message.
- Display numeric fields.
![]() 8. Write a program that reverses given table.
- Define a table that will store an undefined number of one-digit numerics.
- Ask a user to specify the number of items that will be saved in the table.
- Accept given inputs and display the entire table.
- Reverse the table so the first item is moved to the last position, the last one to the first and so one.
- Display reversed table.
8. Write a program that reverses given table.
- Define a table that will store an undefined number of one-digit numerics.
- Ask a user to specify the number of items that will be saved in the table.
- Accept given inputs and display the entire table.
- Reverse the table so the first item is moved to the last position, the last one to the first and so one.
- Display reversed table.
![]() 9. Write a program that processes computers owned by employees in a fictional company:
- Define a structure where a single item represents one computer.
- The structure should have following fields: computer id, owner name, owner e-mail address, purchase date, and transfer date (date in which computer was given to current employee).
- Define the structure in an indexed table that can store up to 1000 employees.
- Populate the table with data.
- Display all records in a loop twice, using a normal variable (subscript) and then with the use of the index. What's the difference?
9. Write a program that processes computers owned by employees in a fictional company:
- Define a structure where a single item represents one computer.
- The structure should have following fields: computer id, owner name, owner e-mail address, purchase date, and transfer date (date in which computer was given to current employee).
- Define the structure in an indexed table that can store up to 1000 employees.
- Populate the table with data.
- Display all records in a loop twice, using a normal variable (subscript) and then with the use of the index. What's the difference?
![]() 10. Modify program from task Task#9. Instead of displaying records perform a serial and binary search of a chosen record.
10. Modify program from task Task#9. Instead of displaying records perform a serial and binary search of a chosen record.
![]() 11. Write a program that accepts from SYSIN a number of words and then displays them:
- The number of records should be passed in the first SYSIN record.
- Allocate an array using OCCURS/TIMES/DEPENDING clause.
- The array should store maximum 10 elements. Each element should have 10 bytes.
- As an input pass 7 words.
- Display the entire table as a string. For example, "DISPLAY WORD-TAB". Next, move '5' to the variable that stores the number of elements in the array and display the table again.
- At last, display the table addressing all bytes. For example, "DISPLAY WORD-TAB(1 : 100)".
11. Write a program that accepts from SYSIN a number of words and then displays them:
- The number of records should be passed in the first SYSIN record.
- Allocate an array using OCCURS/TIMES/DEPENDING clause.
- The array should store maximum 10 elements. Each element should have 10 bytes.
- As an input pass 7 words.
- Display the entire table as a string. For example, "DISPLAY WORD-TAB". Next, move '5' to the variable that stores the number of elements in the array and display the table again.
- At last, display the table addressing all bytes. For example, "DISPLAY WORD-TAB(1 : 100)".
Hint 1
Notice that the length displayed by LENGHT OF or FUNCTION LENGHT display length of the storage the variable occupies, not the actual data length. In COBOL for z/OS there is no function that displays the length of data. That's our goal here so, for now, ignore that, we'll take a look at this problem in the next Task. COBOL language doesn't allow defining tables in the first variable level (01). This level always identifies the entire storage area that a structure, table or variable occupies. So OCCURS clause must occur on one of the higher levels, 05 for example.
Hint 2
You'll need to use UNSTRING function. Check "Enterprise COBOL for z/OS: Language Reference" for the description. To display the actual length of a string variable you'll have to use INSPECT function. FUNCTION LENGHT or LENGHT OF functions display the maximum length of the variable defined in PICTURE definition.
Hint 4
To declare table size dynamically you'll need to use DEPENDING ON instruction. Check "Enterprise COBOL for z/OS: Language Reference" for more information.
Hint 10
Both sequential and binary search is done with the use of SEARCH function. Check "Enterprise COBOL for z/OS: Language Reference" for guidance.
Solution 1
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP301. DATA DIVISION. WORKING-STORAGE SECTION. 01 DOG. 05 RACE PIC X(40). 05 NAME PIC X(20). 05 AGE PIC 9(2). 05 OWNER PIC X(40). PROCEDURE DIVISION. DISPLAY "Enter dog's race:" ACCEPT RACE. DISPLAY "Enter dog's name:" ACCEPT NAME. DISPLAY "Enter dog's age:" ACCEPT AGE. DISPLAY "Enter dog's owner:" ACCEPT OWNER. DISPLAY "FIELD LENGTH: " LENGTH OF RACE ", RACE: " RACE. DISPLAY "FIELD LENGTH: " LENGTH OF NAME ", NAME: " NAME. DISPLAY "FIELD LENGTH: " LENGTH OF AGE ", AGE: " AGE. DISPLAY "FIELD LENGTH: " LENGTH OF OWNER ", OWNER: " OWNER. DISPLAY "FIELD LENGTH: " LENGTH OF DOG ", DOG: " DOG. STOP RUN.
This program nicely shows the entire idea behind structures (compound variables). Each structure is a single string variable (a record). It can be divided into substrings (fields), each can be interpreted in various ways, as strings, numerics, edited numerics etc. That's why displaying DOG variables results in:
FIELD LENGTH: 000000102, DOG: Husky Fluffy 08Tom Hardy
We could go even futher and also divide OWNER field into first and last name:
WORKING-STORAGE SECTION. 01 DOG. 05 RACE PIC X(40). 05 NAME PIC X(20). 05 AGE PIC 9(2). 05 OWNER. 10 FIRST-NAME PIC X(20). 10 LAST-NAME PIC X(20).
Output:
FIELD LENGTH: 000000040, RACE: Husky FIELD LENGTH: 000000020, NAME: Fluffy FIELD LENGTH: 000000002, AGE: 08 FIELD LENGTH: 000000102, DOG: Husky Fluffy 08Tom Hardy FIELD LENGTH: 000000040, OWNER: Tom Hardy FIELD LENGTH: 000000020, FIRST-NAME: Tom FIELD LENGTH: 000000020, LAST-NAME: Hardy
Solution 2
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP302. DATA DIVISION. WORKING-STORAGE SECTION. 01 USER-DATA. 05 NAME PIC X(40). 05 AGE PIC 9(3). 05 GENDER PIC X(6). 01 L PIC 9(4) COMP. LINKAGE SECTION. 01 PARM. 05 PARML PIC 9(4) USAGE COMP. 05 PARMD PIC X(80). PROCEDURE DIVISION USING PARM. DISPLAY "FULL PARM (" PARMD ") LENGTH: " PARML. UNSTRING PARMD DELIMITED BY ALL ',' INTO NAME AGE GENDER. DISPLAY "NAME (" NAME ")" DISPLAY "AGE (" AGE ")" DISPLAY "GENDER (" GENDER ")" * INCORRECT CALCULATIONS COMPUTE L = FUNCTION LENGTH(NAME). DISPLAY "LENGHT OF NAME (PIC): " L. COMPUTE L = LENGTH OF GENDER. DISPLAY "LENGHT OF GENDER (PIC): " L. * CALCULATING LENGHT OF NAME MOVE 0 TO L. INSPECT FUNCTION REVERSE(NAME) TALLYING L FOR LEADING SPACES. COMPUTE L = LENGTH OF NAME - L. DISPLAY "LENGTH OF NAME: " L. * CALCULATING LENGHT OF GENDER MOVE 0 TO L. INSPECT FUNCTION REVERSE(GENDER) TALLYING L FOR LEADING SPACES. COMPUTE L = LENGTH OF GENDER - L. DISPLAY "LENGHT OF GENDER: " L. * CALCULATING LENGHT OF AGE MOVE 0 TO L. INSPECT AGE TALLYING L FOR LEADING ZEROES. COMPUTE L = LENGTH OF AGE - L. DISPLAY "LENGHT OF AGE: " L. STOP RUN.
The best way of thinking about parameter passed to COBOL program is as a variable length record. The first 2 bytes of the parameter contain record length, the rest of the parameter is its value. UNSTRING function provides an easy way to divide string passed as the parameter into appropriate fields. In this example, we can execute the program as follows: "CALL 'JSADEK.MY.COBOL.LINKLIB(MP108)' 'John Hurt,38,Male' ASIS" As you can see here LENGTH OF and FUNCTION LENGTH doesn't return the length of the actual variable but the maximum length defined by PICTURE statement, so the size of the variable. It may seem strange but COBOL on z/OS doesn't have any function that can return the length of the data in a variable. Because of that, it is done with INSPECT and COMPUTE/SUBTRACT instructions. In case of string variables we must first reverse the string and then check the number of spaces at the beginning (INSPECT function doesn't have TRAILING version). Then we can subtract this value from the size of the string using LENGTH OF function. In case of number it's a bit easier since, we don't have to reverse it and we check for leading zeroes, not spaces. Also remember that you must reinitialize the variable L before each INSPECT function with "MOVE 0 TO L" otherwise you'll get incorrect results.
Solution 3
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP303. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM-TBL. 05 NUM PIC 9(3) OCCURS 5 TIMES. 01 I PIC 9(2). 01 K PIC 9(2). 01 K-INIT PIC 9(2). 01 TEMP-NUM PIC 9(3). 01 LOWEST PIC 9(2). PROCEDURE DIVISION. ACCEPT-NUMS-FOR-SORTING. DISPLAY "Specify 5 NUMs: " ACCEPT NUM(1). ACCEPT NUM(2). ACCEPT NUM(3). ACCEPT NUM(4). ACCEPT NUM(5). SORT-NUMS. PERFORM VARYING I FROM 1 BY 1 UNTIL I = 5 COMPUTE K-INIT = I + 1 MOVE I TO LOWEST PERFORM VARYING K FROM K-INIT BY 1 UNTIL K = 6 * DISPLAY I "-" K IF NUM(K) < NUM(LOWEST) * DISPLAY NUM(K) " IS LOWER THAN " NUM(LOWEST) MOVE K TO LOWEST END-IF END-PERFORM * DISPLAY NUM(LOWEST) " IS THE LOWEST" MOVE NUM(I) TO TEMP-NUM MOVE NUM(LOWEST) TO NUM(I) MOVE TEMP-NUM TO NUM(LOWEST) END-PERFORM. DISPLAY-TABLE. PERFORM VARYING I FROM 1 BY 1 UNTIL I = 5 + 1 DISPLAY NUM(I) END-PERFORM. END-PROGRAM. STOP RUN.
There are tens of algorithms for sorting which you can check online but when starting with programming the best solution is to figure it out by yourself. You can see here how one-dimensional table is created and referenced. Another thing worth mentioning is programming style, compare the above program with the code below:
IDENTIFICATION DIVISION. PROGRAM-ID. MP303. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM-TBL. 05 NUM PIC 9(3) OCCURS 5 TIMES. 01 I PIC 9(2). 01 K PIC 9(2). 01 K-INIT PIC 9(2). 01 TEMP-NUM PIC 9(3). 01 LOWEST PIC 9(2). PROCEDURE DIVISION. MAIN-PROCEDURE. PERFORM ACCEPT-NUMS-FOR-SORTING. PERFORM SORT-NUMS. PERFORM DISPLAY-TABLE. STOP RUN. ACCEPT-NUMS-FOR-SORTING. DISPLAY "Specify 5 NUMs: " ACCEPT NUM(1). ACCEPT NUM(2). ACCEPT NUM(3). ACCEPT NUM(4). ACCEPT NUM(5). SORT-NUMS. PERFORM VARYING I FROM 1 BY 1 UNTIL I = 5 COMPUTE K-INIT = I + 1 MOVE I TO LOWEST PERFORM VARYING K FROM K-INIT BY 1 UNTIL K = 6 * DISPLAY I "-" K IF NUM(K) < NUM(LOWEST) * DISPLAY NUM(K) " IS LOWER THAN " NUM(LOWEST) MOVE K TO LOWEST END-IF END-PERFORM * DISPLAY NUM(LOWEST) " IS THE LOWEST" MOVE NUM(I) TO TEMP-NUM MOVE NUM(LOWEST) TO NUM(I) MOVE TEMP-NUM TO NUM(LOWEST) END-PERFORM. DISPLAY-TABLE. PERFORM VARYING I FROM 1 BY 1 UNTIL I = 5 + 1 DISPLAY NUM(I) END-PERFORM.
It's only small modification, instead of executing program senquentially we invoke procedures separately, using PERFORM instruction. This is how COBOL program should be coded. This way we improve readability of the program, it's not that visible here but in normal programs that have hundreds and thousands of lines it makes a big difference. Also we can execute each paragraph many times without the need of copying it, for example:
MAIN-PROCEDURE. PERFORM ACCEPT-NUMS-FOR-SORTING. PERFORM DISPLAY-TABLE. PERFORM SORT-NUMS. PERFORM DISPLAY-TABLE. STOP RUN.
Solution 4
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP304. DATA DIVISION. WORKING-STORAGE SECTION. 01 TBL-SIZE PIC 9(2). 01 WORD-TBL. 05 WORD PIC X(8) OCCURS 1 TO 99 TIMES DEPENDING ON TBL-SIZE. 01 I PIC 9(2). 01 K PIC 9(2). 01 K-INIT PIC 9(2). 01 TEMP-WORD PIC X(8). 01 LOWEST PIC 9(2). PROCEDURE DIVISION. MAIN-PROCEDURE. PERFORM ACCEPT-WORDS-FOR-SORTING. DISPLAY "Table before sort:". PERFORM DISPLAY-TABLE. PERFORM SORT-WORDS. DISPLAY "Table after sort:". PERFORM DISPLAY-TABLE. DISPLAY "Full table representation:". DISPLAY ">>>" WORD-TBL "<<<". STOP RUN. ACCEPT-WORDS-FOR-SORTING. DISPLAY "Specify the table size:" ACCEPT TBL-SIZE. DISPLAY "Specify " TBL-SIZE " WORDs: " PERFORM VARYING I FROM 1 BY 1 UNTIL I > TBL-SIZE ACCEPT WORD(I) END-PERFORM. SORT-WORDS. PERFORM VARYING I FROM 1 BY 1 UNTIL I = TBL-SIZE COMPUTE K-INIT = I + 1 MOVE I TO LOWEST PERFORM VARYING K FROM K-INIT BY 1 UNTIL K > TBL-SIZE * DISPLAY I "-" K IF WORD(K) < WORD(LOWEST) * DISPLAY WORD(K) " IS LOWER THAN " WORD(LOWEST) MOVE K TO LOWEST END-IF END-PERFORM * DISPLAY WORD(LOWEST) " IS THE LOWEST" MOVE WORD(I) TO TEMP-WORD MOVE WORD(LOWEST) TO WORD(I) MOVE TEMP-WORD TO WORD(LOWEST) END-PERFORM. DISPLAY-TABLE. PERFORM VARYING I FROM 1 BY 1 UNTIL I > TBL-SIZE DISPLAY WORD(I) END-PERFORM.
With COBOL we can define table dynamically with use of DEPENDING ON keyword. You can verify it by displaying the entire table "DISPLAY WORD-TBL.". Another thing that this program teaches is sort order for EBCDIC strings. Unlike ASCII EBCDIC defines characters in correct order: - Lower-case letters - Upper-case letters - Numbers Thanks to that we can sort string in exactly the same way as numbers and get correct results.
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP305. DATA DIVISION. WORKING-STORAGE SECTION. 01 MULTI-TBL. 05 ROW OCCURS 2 TO 20 TIMES DEPENDING ON TBL-SIZE. 10 FIELD PIC 9(3) OCCURS 2 TO 20 TIMES DEPENDING ON TBL-SIZE. 01 I PIC 9(2). 01 K PIC 9(2). 01 ROW-EDITED PIC X(100). 01 ROW-POINTER PIC 9(3). LINKAGE SECTION. 01 PARMDATA. 05 PARML PIC 9(4) COMP. 05 TBL-SIZE PIC 9(2). PROCEDURE DIVISION USING PARMDATA. MAIN-LOGIC. PERFORM CHECK-TABLE-SIZE. PERFORM GENERATE-MULTI-TABLE. PERFORM DISPLAY-MULTI-TABLE. STOP RUN. * PROCEDURES USED BY MAIN-LOGIC. CHECK-TABLE-SIZE. IF TBL-SIZE < 2 OR TBL-SIZE > 20 DISPLAY TBL-SIZE " is not allowed by the program." DISPLAY "2-20 are allowed values." STOP RUN ELSE DISPLAY TBL-SIZE " x " TBL-SIZE " table will be " "generated.". DISPLAY-MULTI-TABLE. PERFORM VARYING I FROM 1 BY 1 UNTIL I > TBL-SIZE MOVE " " TO ROW-EDITED PERFORM VARYING K FROM 1 BY 1 UNTIL K > TBL-SIZE COMPUTE ROW-POINTER = ( (K - 1) * 5 ) + 1 STRING FIELD (I K) DELIMITED BY SIZE INTO ROW-EDITED POINTER ROW-POINTER END-STRING END-PERFORM DISPLAY ROW-EDITED END-PERFORM. GENERATE-MULTI-TABLE. PERFORM VARYING I FROM 1 BY 1 UNTIL I > TBL-SIZE PERFORM VARYING K FROM 1 BY 1 UNTIL K > TBL-SIZE COMPUTE FIELD (I K) = I * K END-PERFORM END-PERFORM.
Above program presents how two-dimensional tables are defined and referenced. You definition itself is fairly complicated but it is referenced the same way as in other programming language with the exception that in COBOL you need to use the name of the cell, not the name of the table like in other languages. A nice thing about tables in COBOL is that you can very easily display the entire table, selected row or cell:
DISPLAY MULTI-TBL. DISPLAY ROW (1). DISPLAY FIELD (1 1).
It's also worth taking look at a structure of STRING function and analyze it, it presents how you can concatenate strings in COBOL. Important: When executing PERFORM loop the entire loop is treated as a single statement. That's why you cannot use '.' as a delimiter for IF or STRING instructions. You need to use END-IF or END-STRING instead.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP306. DATA DIVISION. WORKING-STORAGE SECTION. 01 CAR. 02 BRAND PIC X(40). 02 MODEL PIC X(40). 02 GENERATIONS OCCURS 50 TIMES. 03 GENERATION-NAME PIC X(40). 03 GENERATION-PROD-START-YEAR PIC 9(4). 03 GENERATION-PROD-END-YEAR PIC 9(4). 03 VERSIONS OCCURS 50 TIMES. 04 VERSION-NAME PIC X(40). 04 VERSION-DESCRIPTION PIC X(100). 04 VERSION-PARAMETERS OCCURS 50 TIMES. 05 VERSION-P-NAME PIC X(40). 05 VERSION-P-UNIT PIC X(10). 05 VERSION-P-VALUE PIC X(40). 04 EQUIPMENT-VERSION OCCURS 50 TIMES. 05 EQUIPMENT-VER-NAME PIC X(40). 03 ENGINE-VERSION OCCURS 50 TIMES. 04 ENGINE-TYPE PIC X(40). 04 TOP-SPEED-KM-H PIC 9(3). 04 ACCELERATION-0-100-KM-H PIC Z9.99. 04 HORSE-POWER PIC 9(4). 04 ENGINE-PARAMETERS OCCURS 50 TIMES. 05 ENGINE-P-NAME PIC X(40). 05 ENGINE-P-UNIT PIC X(10). 05 ENGINE-P-VALUE PIC X(40). 04 CAR-VERSIONS-WITH-THE-ENGINE OCCURS 50 TIMES. 05 VERSION-NAME-FOR-ENGINE PIC X(40). 03 EQUIPMENT-ITEMS OCCURS 500 TIMES. 04 EQUIPMENT-NAME PIC X(40). 04 EQUIPMENT-DESCRIPTION PIC X(100). 04 CAR-VERSIONS-WITH-THE-EQUIP OCCURS 50 TIMES. 05 EQUIPMENT-VER-NAME-FOR-ITEM PIC X(40). 01 K1 PIC 9(2). 01 K2 PIC 9(2). 01 K3 PIC 9(2). 01 K4 PIC 9(2). 01 K5 PIC 9(2). 01 K6 PIC 9(2). PROCEDURE DIVISION. MOVE "Audi" TO BRAND. MOVE "A4" TO MODEL. MOVE "B7" TO GENERATION-NAME (1). MOVE "B8" TO GENERATION-NAME (2). MOVE "B9" TO GENERATION-NAME (3). MOVE 2007 TO GENERATION-PROD-START-YEAR(2). MOVE 2015 TO GENERATION-PROD-END-YEAR(2). MOVE 2015 TO GENERATION-PROD-START-YEAR(3). MOVE "LIMUSINE" TO VERSION-NAME(3 1). MOVE "SEDAN VERSION" TO VERSION-DESCRIPTION(3 1). MOVE "AVANT" TO VERSION-NAME(3 2). MOVE "COMBI VERSION" TO VERSION-DESCRIPTION(3 2). MOVE "RS4 AVANT" TO VERSION-NAME(3 3). MOVE "Height" TO VERSION-P-NAME(3 2 1). MOVE "MM" TO VERSION-P-UNIT(3 2 1). MOVE "1434" TO VERSION-P-VALUE(3 2 1). MOVE "Width" TO VERSION-P-NAME(3 2 2). MOVE "MM" TO VERSION-P-UNIT(3 2 2). MOVE "1842" TO VERSION-P-VALUE(3 2 2). MOVE "Length" TO VERSION-P-NAME(3 2 3). MOVE "MM" TO VERSION-P-UNIT(3 2 3). MOVE "4727" TO VERSION-P-VALUE(3 2 3). MOVE "LOW-EQ" TO EQUIPMENT-VER-NAME(3 1 1). MOVE "MID-EQ" TO EQUIPMENT-VER-NAME(3 1 2). MOVE "HIGH-EQ" TO EQUIPMENT-VER-NAME(3 1 3). MOVE "LOW-EQ" TO EQUIPMENT-VER-NAME(3 2 1). MOVE "MID-EQ" TO EQUIPMENT-VER-NAME(3 2 2). MOVE "HIGH-EQ" TO EQUIPMENT-VER-NAME(3 2 3). MOVE "HIGH-EQ" TO EQUIPMENT-VER-NAME(3 3 1). MOVE "1.4 TFSI" TO ENGINE-TYPE(3 1). MOVE "2.0 TFSI" TO ENGINE-TYPE(3 2). MOVE "210" TO TOP-SPEED-KM-H(3 1). MOVE "250" TO TOP-SPEED-KM-H(3 2). MOVE 9 TO ACCELERATION-0-100-KM-H(3 1). MOVE 6.5 TO ACCELERATION-0-100-KM-H(3 2). MOVE "150" TO HORSE-POWER(3 1). MOVE "252" TO HORSE-POWER(3 2). MOVE "GEARBOX" TO ENGINE-P-NAME(3 1 1). MOVE "GEARS" TO ENGINE-P-UNIT(3 1 1). MOVE "6" TO ENGINE-P-VALUE(3 1 1). MOVE "FUEL CONSUMPTION" TO ENGINE-P-NAME(3 2 1). MOVE "L/100KM" TO ENGINE-P-UNIT(3 2 1). MOVE "8.7" TO ENGINE-P-VALUE(3 2 1). MOVE "LIMUSINE" TO VERSION-NAME-FOR-ENGINE(3 1 1). MOVE "AVANT" TO VERSION-NAME-FOR-ENGINE(3 1 2). MOVE "LIMUSINE" TO VERSION-NAME-FOR-ENGINE(3 2 1). MOVE "AVANT" TO VERSION-NAME-FOR-ENGINE(3 2 2). MOVE "RS4 AVANT" TO VERSION-NAME-FOR-ENGINE(3 2 3). MOVE "BOSS RADIO" TO EQUIPMENT-NAME(3 1). MOVE "AUDIO SYSTEM FROM BOSS WITH 6 SPEAKERS" TO EQUIPMENT-DESCRIPTION(3 1). MOVE "LEATHER STEERING WHEEL" TO EQUIPMENT-NAME(3 2). MOVE "RS4 AVANT" TO EQUIPMENT-VER-NAME-FOR-ITEM(3 1 1). MOVE "LIMUSINE" TO EQUIPMENT-VER-NAME-FOR-ITEM(3 2 1). MOVE "AVANT" TO EQUIPMENT-VER-NAME-FOR-ITEM(3 2 2). MOVE "RS4 AVANT" TO EQUIPMENT-VER-NAME-FOR-ITEM(3 2 3). DISPLAY "BRAND: " BRAND. DISPLAY "MODEL: " MODEL. PERFORM VARYING K1 FROM 1 BY 1 UNTIL GENERATION-NAME(K1) = LOW-VALUES DISPLAY " GEN NAME: " GENERATION-NAME(K1) DISPLAY " GEN START YEAR: " GENERATION-PROD-START-YEAR(K1) DISPLAY " GEN END YEAR: " GENERATION-PROD-END-YEAR(K1) PERFORM VARYING K2 FROM 1 BY 1 UNTIL VERSION-NAME(K1 K2) = LOW-VALUES DISPLAY " VERSION: " VERSION-NAME(K1 K2) DISPLAY " DESCRIPTION: " VERSION-DESCRIPTION(K1 K2) PERFORM VARYING K3 FROM 1 BY 1 UNTIL VERSION-P-NAME(K1 K2 K3) = LOW-VALUES DISPLAY " " VERSION-P-NAME(K1 K2 K3) ": " VERSION-P-VALUE(K1 K2 K3) " [" VERSION-P-UNIT(K1 K2 K3) "]" END-PERFORM PERFORM VARYING K3 FROM 1 BY 1 UNTIL EQUIPMENT-VER-NAME(K1 K2 K3) = LOW-VALUES DISPLAY " AVAILABLE OPTION: " EQUIPMENT-VER-NAME(K1 K2 K3) END-PERFORM END-PERFORM PERFORM VARYING K2 FROM 1 BY 1 UNTIL ENGINE-TYPE(K1 K2) = LOW-VALUES DISPLAY " ENGINE: " ENGINE-TYPE(K1 K2) DISPLAY " TOP SPEED: " TOP-SPEED-KM-H(K1 K2) " [KM/H]" DISPLAY " ACCELERATION: " ACCELERATION-0-100-KM-H(K1 K2) " [0-100 KM/H]" DISPLAY " HORSE POWER: " HORSE-POWER(K1 K2) PERFORM VARYING K3 FROM 1 BY 1 UNTIL VERSION-NAME-FOR-ENGINE(K1 K2 K3) = LOW-VALUES DISPLAY " AVAILABLE IN VERSION: " VERSION-NAME-FOR-ENGINE(K1 K2 K3) END-PERFORM END-PERFORM PERFORM VARYING K2 FROM 1 BY 1 UNTIL ENGINE-TYPE(K1 K2) = LOW-VALUES DISPLAY " EQUIPMENT: " EQUIPMENT-NAME(K1 K2) DISPLAY " DESCRIPTION: " EQUIPMENT-DESCRIPTION(K1 K2) PERFORM VARYING K3 FROM 1 BY 1 UNTIL EQUIPMENT-VER-NAME-FOR-ITEM(K1 K2 K3) = LOW-VALUES DISPLAY " AVAILABLE IN VERSION: " EQUIPMENT-VER-NAME-FOR-ITEM(K1 K2 K3) END-PERFORM END-PERFORM END-PERFORM. STOP RUN.
Output:
BRAND: Audi MODEL: A4 GEN NAME: B7 GEN START YEAR: GEN END YEAR: GEN NAME: B8 GEN START YEAR: 2007 GEN END YEAR: 2015 GEN NAME: B9 GEN START YEAR: 2015 GEN END YEAR: VERSION: LIMUSINE DESCRIPTION: SEDAN VERSION AVAILABLE OPTION: LOW-EQ AVAILABLE OPTION: MID-EQ AVAILABLE OPTION: HIGH-EQ VERSION: AVANT DESCRIPTION: COMBI VERSION Height : 1434 [MM ] Width : 1842 [MM ] Length : 4727 [MM ] AVAILABLE OPTION: LOW-EQ AVAILABLE OPTION: MID-EQ AVAILABLE OPTION: HIGH-EQ VERSION: RS4 AVANT DESCRIPTION: AVAILABLE OPTION: HIGH-EQ ENGINE: 1.4 TFSI TOP SPEED: 210 [KM/H] ACCELERATION: 9.00 [0-100 KM/H] HORSE POWER: 0150 AVAILABLE IN VERSION: LIMUSINE AVAILABLE IN VERSION: AVANT ENGINE: 2.0 TFSI TOP SPEED: 250 [KM/H] ACCELERATION: 6.50 [0-100 KM/H] HORSE POWER: 0252 AVAILABLE IN VERSION: LIMUSINE AVAILABLE IN VERSION: AVANT AVAILABLE IN VERSION: RS4 AVANT EQUIPMENT: BOSS RADIO DESCRIPTION: AUDIO SYSTEM FROM BOSS WITH 6 SPEAKERS AVAILABLE IN VERSION: RS4 AVANT EQUIPMENT: LEATHER STEERING WHEEL DESCRIPTION: AVAILABLE IN VERSION: LIMUSINE AVAILABLE IN VERSION: AVANT AVAILABLE IN VERSION: RS4 AVANT
This program presents a fairly complex structure that represents a particular model of a car. Structures in COBOL are designed in a hierarchical way, the same way as hierarchical databases are designed (IMS uses hierarchical databases). Definitions itself are not difficult to understand, the complexity lies in the design of such structure/database. Many items could have been designed differently. For example, car equipment items could have been part of VERSIONS level, with this solution we wouldn't need CAR-VERSIONS-WITH-THE-EQUIP table but we would have to duplicate each equipment item many times. This would make management of such database much more difficult. LOW-VALUES are a new keyword we used in this program, this keyword tests if the variable is made of nulls X'00', similarly you can test is the string is filled with SPACES X'40'. Those keywords are useful when you have a table which is only partially populated and you want to process only cells that contain some data.
Solution 7
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP307. DATA DIVISION. WORKING-STORAGE SECTION. 01 TEST-STRUCTURE. 05 NUMBER1 PIC S9(8)V99. 05 FILLER PIC X(21) VALUE " can be formatted as ". 05 NUMBER1-EDI PIC -(7)9.99. 05 FILLER PIC X(16) VALUE " it's square is ". 05 NUMBER1-SQUARE PIC S9(8)V99 USAGE COMP. 05 FILLER PIC X(13) VALUE ". That's all ". 05 USER-NAME PIC X(15). PROCEDURE DIVISION. MAIN-LOGIC. MOVE 54.12 TO NUMBER1 NUMBER1-EDI. COMPUTE NUMBER1-SQUARE = NUMBER1 * NUMBER1. MOVE "Joanna" TO USER-NAME. DISPLAY TEST-STRUCTURE. DISPLAY NUMBER1-SQUARE. MOVE NUMBER1-SQUARE TO NUMBER1 NUMBER1-EDI. DISPLAY TEST-STRUCTURE. MOVE "SOME VERY LOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO - "OOOONG MESSAGE" TO TEST-STRUCTURE. DISPLAY TEST-STRUCTURE. DISPLAY NUMBER1. DISPLAY NUMBER1-EDI. DISPLAY NUMBER1-SQUARE. STOP RUN.
Output:
000000541B can be formatted as 54.12 it's square is . That's all Joanna 0000292897 000029289G can be formatted as 2928.97 it's square is . That's all Joanna SOME VERY LOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOONG MESSAGE SOME VERY OOOOOOOOOOO CEE3209S The system detected a fixed-point divide exception (System Completion Code=0C9).
Comments: - This program presents one of the best uses of structures – a message definition. Consider a situation in which a program often issues some kind of informational or error message. Defining a structure for such message will save you time on message formatting and allows quick modification of specific parts of the message. - You can also see how string continuation is done in COBOL. Text must end at exactly 72 column and in the next line continuation sign '-' must be put in column 7. Also, notice that both quotes are put in the continuing line but only one on the first line. - Moving string directly to a structure (using structure name) overwrites all field without regard to their types, including FILLER and NUMERIC fields. It's because structure itself is always treated as alphanumeric field X(n) and behaves the same way. - Still, if you reference a child variable, for example, NUMBER1 it's treated as a numeric type. That's why you won't be able to use them in some functions for example COMPUTE, or even DISPLAY like in this example. NUMERIC1 and NUMERIC1-EDI was displayed and as you can see they now contain part of the string but program abended when displaying NUMERIC-COMP variable.
Solution 8
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP308. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM-TABLE. 05 NUM-ITEM PIC 9 OCCURS 1 TO 9999 TIMES DEPENDING ON NUM-COUNT. 77 NUM-COUNT PIC 9(4). 77 K1 PIC 9(4). 77 K2 PIC 9(4). 77 ITERATIONS PIC 9(4). 77 TEMP PIC 9. PROCEDURE DIVISION. MAIN-LOGIC. DISPLAY "Please specify number of items to add:" ACCEPT NUM-COUNT. DISPLAY NUM-COUNT " items will be accepted" PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > NUM-COUNT ACCEPT NUM-ITEM(K1) END-PERFORM. COMPUTE ITERATIONS = NUM-COUNT / 2. DISPLAY "BEFORE REVERSAL >" NUM-TABLE "<". PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > ITERATIONS MOVE NUM-ITEM(K1) TO TEMP COMPUTE K2 = NUM-COUNT + 1 - K1 MOVE NUM-ITEM(K2) TO NUM-ITEM(K1) MOVE TEMP TO NUM-ITEM(K2) END-PERFORM. DISPLAY "AFTER REVERSAL >" NUM-TABLE "<". STOP RUN.
Comments: - Table reversal is rarely done but it's a nice and easy way to get more practice with tables. - Notice that in number of inputs are uneven, for example, 7, the number of iterations needed for reversal is equal to 3, the middle item will stay unchanged. The K2 variable is an integer, so although the result would be 3.5 digits after the decimal point are trimmed and we get the correct number of iterations. It's mentioned here because you need to always pay attention to such conditions when working with tables. - In case of dynamic table size you can check their length by issuing LENGHT function against the table name: "DISPLAY LENGTH OF NUM-TABLE".
Solution 9
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP309) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP309. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 COMP-TABLE. 05 COMP-RECORD OCCURS 1000 TIMES INDEXED BY COMP-IX. 10 COMP-ID PIC 9(8). 10 OWNER-NAME PIC X(25). 10 OWNER-EMAIL PIC X(25). 10 PURCHASE-DATE PIC X(10). 10 TRANSFER-DATE PIC X(10). 77 INPUT-END PIC 9 VALUE 0. 77 COMP-NUM PIC 9(4) COMP. 77 K1 PIC 9(8) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-RECORDS. PERFORM DISPLAY-BY-SUBSCRIPT. PERFORM DISPLAY-BY-INDEX. STOP RUN. ACCEPT-RECORDS. ACCEPT COMP-RECORD(1). IF COMP-RECORD(1) = LOW-VALUES DISPLAY "NO RECORDS FOUND" STOP RUN END-IF. PERFORM VARYING K1 FROM 2 BY 1 UNTIL INPUT-END = 1 ACCEPT COMP-RECORD(K1) IF COMP-RECORD(K1) = LOW-VALUES COMPUTE COMP-NUM = K1 - 1 MOVE 1 TO INPUT-END END-IF END-PERFORM. DISPLAY-BY-SUBSCRIPT. DISPLAY "SUBSCRIPT:". PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > COMP-NUM DISPLAY COMP-RECORD(K1) END-PERFORM. DISPLAY-BY-INDEX. DISPLAY "INDEX:". PERFORM VARYING COMP-IX FROM 1 BY 1 UNTIL COMP-IX > COMP-NUM DISPLAY COMP-RECORD(COMP-IX) END-PERFORM. //GO.SYSIN DD * 00000011MARK TWAIN MARK.T@GMAIL.COM 2017-10-032017-12-17 00000322JOHN MAL JOHN293@SSD.COM 2018-01-122018-02-13 00000413SARAH SMITH SARAH.S@YAHOO.COM 2017-11-042017-11-23 000004333OM HARDING PIT@GMAIL.COM 2017-10-032017-12-17 00000522DICK MACH BIG.ONE@OUTLOOK.COM 2017-12-232018-02-01
Comments: - INDEX is an alternative way of accessing elements in an array. - The fact the table is indexed doesn't mean it's sorted. If it is you should also use ASCENDING/ DESCENDING KEY clauses to indicate that. Sorted tables can use binary search which is much faster than serial search. - The main difference between index and subscript is that subscript stores element number while index its byte address. In this example subscript of the second element in the table would have value 2, while index 77. The record has 78 bytes but index counts address from 0 therefore 77, not 78. Still, those values are invisible to the programmer, and you access elements via index using the element number, just like in case of the subscript. - Using it is most beneficial in programs that use SEARCH statement since it enables binary search on an array for which INDEX is defined. - Also, access to array items via INDEX is faster so using it should be also considered in programs that perform a lot of operations on the table. - You can't use index variable in any calculations, so in COMPUTE, ADD, DIVIDE etc. functions. All you can do is to use SET statement which allows some simple operations such as index incrementation. - Notice how input data is accepted in this program. In the previous task, the user specified number of records that will be read from SYSIN. Now program detects the end of input data by itself by checking for LOW-VALUES.
Solution 10
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP310. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 COMP-TABLE. 05 COMP-RECORD OCCURS 1000 TIMES DEPENDING ON COMP-NUM ASCENDING KEY COMP-ID INDEXED BY COMP-IX. 10 COMP-ID PIC 9(8). 10 OWNER-NAME PIC X(25). 10 OWNER-EMAIL PIC X(25). 10 PURCHASE-DATE PIC X(10). 10 TRANSFER-DATE PIC X(10). 77 INPUT-END PIC 9 VALUE 0. 77 COMP-NUM PIC 9(4) COMP. 77 K1 PIC 9(8) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-RECORDS. PERFORM SEQUENTIAL-SEARCH. PERFORM INDEXED-SEARCH. STOP RUN. ACCEPT-RECORDS. ACCEPT COMP-RECORD(1). IF COMP-RECORD(1) = LOW-VALUES DISPLAY "NO RECORDS FOUND" STOP RUN END-IF. PERFORM VARYING K1 FROM 2 BY 1 UNTIL INPUT-END = 1 ACCEPT COMP-RECORD(K1) IF COMP-RECORD(K1) = LOW-VALUES COMPUTE COMP-NUM = K1 - 1 MOVE 1 TO INPUT-END END-IF END-PERFORM. SEQUENTIAL-SEARCH. MOVE 1 TO K1. SEARCH COMP-RECORD VARYING K1 AT END DISPLAY "NO SUCH RECORD IN THE TABLE" WHEN COMP-ID(K1) = 433 DISPLAY COMP-ID(K1) " FOUND ON " K1 " POSITION". INDEXED-SEARCH. SEARCH ALL COMP-RECORD AT END DISPLAY "NO SUCH RECORD IN THE TABLE" WHEN COMP-ID(COMP-IX) = 11 SET K1 TO COMP-IX DISPLAY COMP-ID(COMP-IX) " FOUND ON " K1 " POSITION".
Comments: - Notice DEPENDING ON clause, we haven't used it in Task#9. Without it, the table is considered to have 1000 elements and that much will be searched. It wasn't a problem in Task#9 since we've only displayed non-empty records but it matters now. SEARCH function searches the entire table, so (without DEPENDING ON clause) 1000 records. It's a waste of processor time in case of serial search and causes incorrect search result in case of an indexed search. - You cannot use the index in MOVE or DISPLAY functions but you can copy it to a normal variable using SET keyword and then do some further processing with its value. - ASCENDING/DESCENDING keyword are only indicators, they do not ensure that the data is actually sorted. Also, SEARCH ALL will end fine for unsorted records but the search result will be incorrect. Therefore you must ensure that the data is sorted by yourself.
Solution 11
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP311. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 WORD-TAB. 05 A-WORD OCCURS 0 TO 10 TIMES DEPENDING ON WORD-NUM PIC X(10). 77 WORD-NUM PIC 9(2). 77 K1 PIC 9(2) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-WORDS. PERFORM DISPLAY-THE-TABLE. STOP RUN. ACCEPT-WORDS. ACCEPT WORD-NUM. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > WORD-NUM ACCEPT A-WORD(K1) END-PERFORM. DISPLAY-THE-TABLE. DISPLAY "- WORD-TAB:". DISPLAY ">>>" WORD-TAB "<<<". DISPLAY "- WORD-TAB(1 : 100):". DISPLAY ">>>" WORD-TAB(1 : 100) "<<<". MOVE 5 TO WORD-NUM. DISPLAY "- WORD-TAB AFTER MOVING 5 TO WORD-NUM:". DISPLAY ">>>" WORD-TAB "<<<". DISPLAY "- WORD-TAB(1 : 100) AGAIN:". DISPLAY ">>>" WORD-TAB(1 : 100) "<<<".
Output:
- WORD-TAB: >>>COBOL IS THE GREATEST LANGUAGE TO HATE <<< - WORD-TAB(1 : 100): >>>COBOL IS THE GREATEST LANGUAGE TO HATE <<< - WORD-TAB AFTER MOVING 5 TO WORD-NUM: >>>COBOL IS THE GREATEST LANGUAGE <<< - WORD-TAB(1 : 100) AGAIN: >>>COBOL IS THE GREATEST LANGUAGE TO HATE <<<
Comments: - This assignment presents that OCCURS/TIMES/DEPENDING clause has nothing to do with dynamic table allocation. Always the maximum possible size is reserved in RAM memory. The purpose of this clause is not storage saving but making array operations simpler. - It's important to remember that. If your structure has 1000 bytes and you'll define the table of such structure as having maximum 1000000 elements you'll waste a lot of Central Storage. Important: - Starting from Enterprise COBOL 6.1 a new ALLOCATE keyword was introduced. With it, you can create a truly dynamic table and allocate just the amount of storage your program needs.
PICTURE clause
Introduction
Except unusual English-like syntax the way variables in COBOL are defined and handled may be a shock for a typical programmer. There are basically two data types in COBOL, strings, and numerics. Simple enough but in reality data types are more messed up than in most other programming languages. Here is a brief list of types used in COBOL: - Numeric (6 subtypes). - Numeric-edited (2 subtypes). - Alphabetic. - Alphanumeric. - Alphanumeric-edited. - DBCS. - National. - National-Edited. Each of those types has a set of characters you use for editing their length, structure or how they are displayed. You can see the detailed description of every of those types in "PICTURE clause" sub-chapter in "Enterprise COBOL for z/OS: Language Reference". Also, you'll play with them more in "USAGE" Assignment.
Tasks
![]() 1. Define appropriate variables for storing following data:
- Bank account balance
- Bank account number
- Date
- Time
- First name
- Last name
- Address
- Age
- Number used for mathematical calculation on large values
- Geographic coordinates
Assign some data to them and display them.
1. Define appropriate variables for storing following data:
- Bank account balance
- Bank account number
- Date
- Time
- First name
- Last name
- Address
- Age
- Number used for mathematical calculation on large values
- Geographic coordinates
Assign some data to them and display them.
![]() 2. Modify the program from Task#1:
- Bank account balance - Display it in readable form and suppress leading zeros.
- Bank account number - Display it in format: NN NNNN NNNN NNNN NNNN NNNN NNNN.
- Date - Display it in format: YYYY/MM/DD.
- Time - Display it in format: HH:MM:SS.
- Age - Suppress leading zeros.
- Number used for mathematical calculation on large values - Suppress leading zeros.
- Geographic coordinates - Add ":" separator between coordinates, display them in readable form and suppress leading zeros.
2. Modify the program from Task#1:
- Bank account balance - Display it in readable form and suppress leading zeros.
- Bank account number - Display it in format: NN NNNN NNNN NNNN NNNN NNNN NNNN.
- Date - Display it in format: YYYY/MM/DD.
- Time - Display it in format: HH:MM:SS.
- Age - Suppress leading zeros.
- Number used for mathematical calculation on large values - Suppress leading zeros.
- Geographic coordinates - Add ":" separator between coordinates, display them in readable form and suppress leading zeros.
![]() 3. Modify the program from Task#2:
- Trim all leading and trailing spaces of all variables.
- In case of signed numerics also remove spaces between the sign and the number.
- In case of coordinates variable round the values to 5 digits after the decimal point.
- In case of address variable also add commas between fields.
3. Modify the program from Task#2:
- Trim all leading and trailing spaces of all variables.
- In case of signed numerics also remove spaces between the sign and the number.
- In case of coordinates variable round the values to 5 digits after the decimal point.
- In case of address variable also add commas between fields.
![]() 4. Define PROFITS variable which represents company profits from last year:
- Use REDEFINE clause to represent profits in terms of cents, dollars, thousands, millions and billions.
- Define second variable WORD which represents zOS architecture WORD (64bits) in readable form (as string).
- Use REDEFINE clause to represent separate bytes of the WORD.
- Use another REDEFINE clause to represent bits 57, 58 and 59 of the WORD.
4. Define PROFITS variable which represents company profits from last year:
- Use REDEFINE clause to represent profits in terms of cents, dollars, thousands, millions and billions.
- Define second variable WORD which represents zOS architecture WORD (64bits) in readable form (as string).
- Use REDEFINE clause to represent separate bytes of the WORD.
- Use another REDEFINE clause to represent bits 57, 58 and 59 of the WORD.
![]() 5. Define two variables. One numeric 999V999 and one alphanumeric X(8):
- Accept following values to the numeric: 2.3, 1211 392.11112.
- Accept following values to the alphanumeric: A Word, Something, My Variable.
- Add another two variables 99.99 and X(6). Move to them all the above variables and display the results.
5. Define two variables. One numeric 999V999 and one alphanumeric X(8):
- Accept following values to the numeric: 2.3, 1211 392.11112.
- Accept following values to the alphanumeric: A Word, Something, My Variable.
- Add another two variables 99.99 and X(6). Move to them all the above variables and display the results.
![]() 6. Create 3 variables and initialize them with following values: " Cobol ", -832.118, 4321. Display them in following formats:
- "Cobol "
- " Cobol"
- "Cob o"
- "/C o b o l/"
- - 832.118
- -00832.11800
- -**832.118
- - 832.12 (round the value)
- -832.11 (with no spaces between '-' and the number)
- +4321
- 4321+
- 4 3 2 1
- 0,004,321.000,000
- $4 321.00
- 04/03/02/01
6. Create 3 variables and initialize them with following values: " Cobol ", -832.118, 4321. Display them in following formats:
- "Cobol "
- " Cobol"
- "Cob o"
- "/C o b o l/"
- - 832.118
- -00832.11800
- -**832.118
- - 832.12 (round the value)
- -832.11 (with no spaces between '-' and the number)
- +4321
- 4321+
- 4 3 2 1
- 0,004,321.000,000
- $4 321.00
- 04/03/02/01
![]() 7. Define a structure representing a coffee.
- Each variable in the structure should represent one ingredient, coffee type, coffee percentage, milk percentage, sugar percentage and so on.
- Use special variable number 66 to define cappuccino.
7. Define a structure representing a coffee.
- Each variable in the structure should represent one ingredient, coffee type, coffee percentage, milk percentage, sugar percentage and so on.
- Use special variable number 66 to define cappuccino.
![]() 8. Define a structure representing an employee.
- In the structure define item YEARS-OF-EXPERIENCE.
- Use 88 conditional variable that defines payment rate depending on the experience.
- Use EVALUATE statement to test the 88 variable.
8. Define a structure representing an employee.
- In the structure define item YEARS-OF-EXPERIENCE.
- Use 88 conditional variable that defines payment rate depending on the experience.
- Use EVALUATE statement to test the 88 variable.
Solution 1
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP401. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 ACCOUNT-BALANCE PIC S9(16)V99. 01 ACCOUNT-NUMBER. 05 SUM-CNTL PIC 9(2). 05 BANK-ID PIC 9(8). 05 CUST-NUMBER PIC 9(16). 01 UDATE. 05 UYEAR PIC 9(4). 05 UMONTH PIC 9(2). 05 UDAY PIC 9(2). 01 UTIME. 05 UHOUR PIC 9(2). 05 UMINUTE PIC 9(2). 05 USECOND PIC 9(2). 01 NAME. 05 FIRST-NAME PIC X(100). 05 LAST-NAME PIC X(100). 01 UADDRESS. 05 STREET PIC X(100). 05 BUILDING PIC X(10). 05 APARTMENT PIC X(10). 05 POSTAL-CODE PIC 9(5). 05 CITY PIC X(100). 05 STATE PIC X(100). 05 COUNTRY PIC X(100). 01 AGE PIC 9(3). 01 CALC-NUMBER PIC S9(18). 01 COORDINATES. 05 XC PIC S9(3)V9(15). 05 YC PIC S9(3)V9(15). PROCEDURE DIVISION. MOVE -3222213.43 TO ACCOUNT-BALANCE. DISPLAY "ACCOUNT BALANCE: " ACCOUNT-BALANCE. MOVE "23827162718326100088352182" TO ACCOUNT-NUMBER. DISPLAY "ACCOUNT NUMBER: " ACCOUNT-NUMBER. MOVE 20180203 TO UDATE. DISPLAY "DATE: " UDATE. MOVE 132206 TO UTIME. DISPLAY "DATE: " UTIME. MOVE "Jan" TO FIRST-NAME. MOVE "Sadek" TO LAST-NAME. DISPLAY "FULL NAME: " NAME. MOVE "Norweska" TO STREET. MOVE "48C" TO BUILDING. MOVE "-" TO APARTMENT. MOVE "54404" TO POSTAL-CODE. MOVE "Wroclaw" TO CITY. MOVE "Dolnoslaskie" TO STATE. MOVE "Poland" TO COUNTRY. DISPLAY "ADDRESS: " UADDRESS. MOVE 32 TO AGE. DISPLAY "Age: " AGE. MOVE 3283272392298 TO CALC-NUMBER. DISPLAY "Some large number: " CALC-NUMBER. MOVE 12.3287320 TO XC. MOVE -31.3928291 TO YC. DISPLAY "Coordinates: " COORDINATES. STOP RUN.
This assignment shows a few important points about variable initialization: - You must always cosider the purpose of your programs and what data will be stored in your variables. For example, POSTAL-CODE and ACCOUNT-NUMBER are different in different countries. In this example, variable definition will do just fine for Polish citizens but problem may appear for people from other countries. - You could of course use X(50) for those fields, this way you'll be sure that data from all countries will fit there but you'll have to code additional logic that verifies the data. - If there is a variable that can be defined as a structure, code it that way. It makes the program more readable and allows you to use such variables in a more flexible way. - ACCOUNT-NUMBER variable points to a variable that doesn't have to be structured but we must do it anyway because of the COBOL limitations. Numerics can have up to 18 digits while account numbers in Poland 26, we can easily overcome this limitation by coding variable as structure, even with meangless parts as A, B, C etc. - COBOL doesn't have DATE & TIME types so you must store this data in form of numbers or strings. The usual way is to use structure as shown in this example. It shows again how important design it, the DATE structure presented here will do fine in 99% cases but what if your program should also store dates from B.C.? - Many character variables are defined here as X(100) seems large enough but is it really? The is a very small percentage of cities, streets and people with names longer than that. Can you affort limiting such data in your program? Can you afford to work on so large variables while in 99.9% of cases X(40) would be sufficient? - What about national characters? In this case, we cannot use them anyways since all variables are assigned inside COBOL program but what if your program uses data coded in UTF-16? Should you program support DBCS and national characters? - Another question you must always consider is if a numeric will be used in some calculations. If yes, what are the largest values in those calculations? What precision is needed? Results:
ACCOUNT BALANCE: 00000000032222134L ACCOUNT NUMBER: 23827162718326100088352182 DATE: 20180203 DATE: 132206 FULL NAME: Jan Sadek ADDRESS: Norweska 48C - 54404Wroclaw Dolnos laskie Poland Age: 032 Some large number: 00000328327239229H Coordinates: 01232873200000000{03139282910000000}
As you can see formatting of text representation of COBOL variables could be better. Fortunately, we have some tools to fix that. The next Task is just about that.
Solution 2
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP402. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 ACCOUNT-BALANCE. 05 ACCOUNT-BALANCE-C PIC S9(16)V99. 05 ACCOUNT-BALANCE-EDI PIC -Z(15)9.99. 01 ACCOUNT-NUMBER. 05 SUM-CNTL PIC 9(2). 05 BANK-ID PIC 9(8). 05 CUST-NUMBER PIC 9(16). 01 ACCOUNT-NUMBER-EDI PIC X(2)B9(4)B9(4)B9(4)B9(4)B9(4)B9(4). 01 UDATE PIC 9(4)/9(2)/9(2). 01 UTIME. 05 UHOUR PIC 9(2). 05 FILLER PIC X VALUE ":". 05 UMINUTE PIC 9(2). 05 FILLER PIC X VALUE ":". 05 USECOND PIC 9(2). 01 NAME. 05 FIRST-NAME PIC X(100). 05 LAST-NAME PIC X(100). 01 UADDRESS. 05 STREET PIC X(100). 05 BUILDING PIC X(10). 05 APARTMENT PIC X(10). 05 POSTAL-CODE PIC 9(5). 05 CITY PIC X(100). 05 STATE PIC X(100). 05 COUNTRY PIC X(100). 01 AGE PIC 9(3). 01 AGE-EDI PIC Z(2)9. 01 CALC-NUMBER PIC S9(18). 01 CALC-NUMBER-EDI PIC -Z(17)9. 01 COORDINATES. 05 XC PIC S9(3)V9(15). 05 YC PIC S9(3)V9(15). 01 COORDINATES-EDI. 05 XC-EDI PIC +Z(2)9.9(15). 05 FILLER PIC X(3) VALUE " : ". 05 YC-EDI PIC +Z(2)9.9(15). PROCEDURE DIVISION. MOVE -3222213.43 TO ACCOUNT-BALANCE-C ACCOUNT-BALANCE-EDI. DISPLAY "Accoutn banalce: " ACCOUNT-BALANCE-EDI. MOVE "23827162718326100088352182" TO ACCOUNT-NUMBER ACCOUNT-NUMBER-EDI. DISPLAY "Account number: " ACCOUNT-NUMBER-EDI. MOVE 20180203 TO UDATE. DISPLAY "Date: " UDATE. MOVE "12:22:06" TO UTIME. DISPLAY "Time: " UTIME. MOVE "Jan" TO FIRST-NAME. MOVE "Sadek" TO LAST-NAME. DISPLAY "Full name: " NAME. MOVE "Norweska" TO STREET. MOVE "48C" TO BUILDING. MOVE "-" TO APARTMENT. MOVE "54404" TO POSTAL-CODE. MOVE "Wroclaw" TO CITY. MOVE "Dolnoslaskie" TO STATE. MOVE "Poland" TO COUNTRY. DISPLAY "Address: " UADDRESS. MOVE 32 TO AGE AGE-EDI. DISPLAY "Age: " AGE-EDI MOVE 3283272392298 TO CALC-NUMBER CALC-NUMBER-EDI. DISPLAY "Some large number: " CALC-NUMBER-EDI. MOVE 12.3287320 TO XC XC-EDI. MOVE -31.3928291 TO YC YC-EDI. DISPLAY "Coordinates: " COORDINATES-EDI. STOP RUN.
Output is still not perfect but definitely readable, especially in case of signed numbers:
Account banalce: - 3222213.43 Account number: 23 8271 6271 8326 1000 8835 2182 Date: 2018/02/03 Time: 12:22:06 Full name: Jan Sadek Address: Norweska 48C - 54404Wroclaw Dolnos laskie Poland Age: 32 Some large number: 3283272392298 Coordinates: + 12.328732000000000 : - 31.392829100000000
You can see here a few methods of data editing: - You can make a structure with two version of the same variable, NUMERIC and NUMERIC-EDITED as in case of ACCOUNT-BALANCE variables. - You can also make a new edited variable like in case of AGE and CALC-NUMBER. - You can completely redefine variable from NUMERIC to NUMERIC-EDITED like in case of DATE. Now you can easily assign new values to it but you're limiting your flexibility in using this variable. You cannot change separators from '/' and to refer to the year you'll have to use UDATE(1:4) instead of simply UYEAR. - Changing data type to EDITED version is not always possible. EDITED numerics cannot be used for calculation so if you'll have to use year or day for this purpose you'll have a problem. Also unlike '/', ':' cannot be used as a separator in NUMERIC-EDITED variables. That's why most often it's better to store the date is similar manner as UTIME is defined. Now you can refer each part of the variable separately, use it in calculation and edit separators. - You can make a new structure like in case of COORDINATES-EDI structures. This method gives you a lot of flexibility. You can use edited versions of the variables, change their order and any separator you want. - In case of ACCOUNT-NUMBER-EDI the length of the number is more than 18 chars (maximum for numerics). We could divide this variable as in case of ACCOUNT-NUMBER. Another solution is to use ALPHANUMERIC-EDITED type as shown here. All we need to do is use X(2) at the beginning, now variable is recognized as ALPHANUMERIC and with the addition of 'B' separator as ALPHANUMEERIC-EDITED. Few important comments: - You can use special keyword FILLER to name variables that you don't need to reference in the code. With it, you don't have to figure out unique names for separators and make the program clearer. - You cannot suppress zeros after the decimal point. - You cannot make calculations on NUMERIC-EDITED fields. - You can MOVE a value to many variables in one sentence (instruction). - '+' sign in NUMERIC-EDITED variables defines that then sign is always displayed even if a value is positive. '-' sign will display the sign if the value is negative and a space if it's positive. - COBOL is kind of stupid when it comes to structures with different data types:
MOVE "12:22:06" TO UTIME. DISPLAY UTIME. * Displays "12:22:06" MOVE "QI:22:A6" TO UTIME. DISPLAY UTIME. * Displays "QI:22:A6" DISPLAY UHOUR. * Displays "QI"
Compute can also process such data:
MOVE "QI:22:A6" TO UTIME. DISPLAY UTIME. * Displays "QI:22:A6" COMPUTE UHOUR = UHOUR + 1. DISPLAY UTIME. * Displays "90:22:A6"
But following instruction ends in "IGYPA3005-S ""QI"" and "UHOUR (NUMERIC INTEGER)" did not follow the "MOVE" statement compatibility rules. The statement was discarded." error:
MOVE "QI:22:A6" TO UTIME. DISPLAY UTIME. * Displays "QI:22:A6" MOVE "QI" TO UHOUR. * Error
Solution 3
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP403. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 ACCOUNT-BALANCE. 05 ACCOUNT-BALANCE-C PIC S9(16)V99. 05 ACCOUNT-BALANCE-EDI PIC -Z(15)9.99. 01 ACCOUNT-NUMBER. 05 SUM-CNTL PIC 9(2). 05 BANK-ID PIC 9(8). 05 CUST-NUMBER PIC 9(16). 01 ACCOUNT-NUMBER-EDI PIC X(2)B9(4)B9(4)B9(4)B9(4)B9(4)B9(4). 01 UDATE PIC 9(4)/9(2)/9(2). 01 UTIME. 05 UHOUR PIC 9(2). 05 FILLER PIC X VALUE ":". 05 UMINUTE PIC 9(2). 05 FILLER PIC X VALUE ":". 05 USECOND PIC 9(2). 01 NAME. 05 FIRST-NAME PIC X(100). 05 LAST-NAME PIC X(100). 01 UADDRESS. 05 STREET PIC X(100). 05 BUILDING PIC X(10). 05 APARTMENT PIC X(10). 05 POSTAL-CODE PIC 9(5). 05 CITY PIC X(100). 05 STATE PIC X(100). 05 COUNTRY PIC X(100). 01 AGE PIC 9(3). 01 AGE-EDI PIC Z(2)9. 01 CALC-NUMBER PIC S9(18). 01 CALC-NUMBER-EDI PIC -Z(17)9. 01 COORDINATES. 05 XC PIC S9(3)V9(15). 05 YC PIC S9(3)V9(15). 01 COORDINATES-EDI. 05 XC-EDI PIC +Z(2)9.9(5). 05 FILLER PIC X(3) VALUE " : ". 05 YC-EDI PIC +Z(2)9.9(5). 01 TRIM-VAR. 05 STR PIC X(500). 05 STR-B PIC 9(4) COMP. 05 STR-L PIC 9(4) COMP. 05 NBR-P PIC 9(4) COMP. 05 NBR-STR PIC X(500). 05 K1 PIC 9(4) COMP. 01 ADDRESS-SMALL. 05 ADDRESS-STR PIC X(500). 05 ADDRESS-L PIC 9(4) COMP. PROCEDURE DIVISION. MOVE -3222213.43 TO ACCOUNT-BALANCE-C ACCOUNT-BALANCE-EDI. MOVE ACCOUNT-BALANCE-EDI TO STR. PERFORM TRIM-NBR. DISPLAY "Account balance: " NBR-STR(1 : NBR-P). MOVE "23827162718326100088352182" TO ACCOUNT-NUMBER ACCOUNT-NUMBER-EDI. DISPLAY "Account number: " ACCOUNT-NUMBER-EDI. MOVE 20180203 TO UDATE. DISPLAY "Date: " UDATE. MOVE "12:22:06" TO UTIME. DISPLAY "Time: " UTIME. MOVE " Jan " TO FIRST-NAME. MOVE FIRST-NAME TO STR. PERFORM TRIM-STR. DISPLAY "First name: " STR(STR-B : STR-L). MOVE "Sadek" TO LAST-NAME. MOVE LAST-NAME TO STR. PERFORM TRIM-STR. DISPLAY "Last name: " STR(STR-B : STR-L). MOVE "Norweska" TO STREET. MOVE "48C" TO BUILDING. MOVE "-" TO APARTMENT. MOVE "54404" TO POSTAL-CODE. MOVE "Wroclaw" TO CITY. MOVE "Dolnoslaskie" TO STATE. MOVE "Poland" TO COUNTRY. PERFORM JOIN-ADDRESS. MOVE 32 TO AGE AGE-EDI. MOVE AGE-EDI TO STR. PERFORM TRIM-NBR. DISPLAY "Age: " NBR-STR(1 : NBR-P). MOVE 3283272392298 TO CALC-NUMBER CALC-NUMBER-EDI. MOVE CALC-NUMBER-EDI TO STR. PERFORM TRIM-NBR. DISPLAY "Some large number: " NBR-STR(1 : NBR-P). MOVE 12.3287320 TO XC XC-EDI. MOVE -31.3928291 TO YC YC-EDI. DISPLAY "Coordinates: " COORDINATES-EDI. STOP RUN. TRIM-STR. MOVE 0 TO STR-B. MOVE 0 TO STR-L. INSPECT STR TALLYING STR-B FOR LEADING SPACES. INSPECT FUNCTION REVERSE(STR) TALLYING STR-L FOR LEADING SPACES. COMPUTE STR-L = LENGTH OF STR - STR-L - STR-B. COMPUTE STR-B = STR-B + 1. TRIM-NBR. MOVE 0 TO NBR-P. PERFORM TRIM-STR. COMPUTE STR-L = STR-L + STR-B. PERFORM VARYING K1 FROM STR-B BY 1 UNTIL K1 > STR-L IF STR(K1 : 1) NOT = LOW-VALUES AND STR(K1 : 1) NOT = SPACES COMPUTE NBR-P = NBR-P + 1 MOVE STR(K1 : 1) TO NBR-STR(NBR-P : 1) END-IF END-PERFORM. JOIN-ADDRESS. MOVE SPACES TO ADDRESS-STR. MOVE 0 TO ADDRESS-L. STRING STREET "," BUILDING "," APARTMENT "," POSTAL-CODE(1 : 2) "-" POSTAL-CODE(3 : 3) "," CITY "," STATE "," COUNTRY DELIMITED BY SPACE INTO ADDRESS-STR. INSPECT FUNCTION REVERSE(ADDRESS-STR) TALLYING ADDRESS-L FOR LEADING SPACES. COMPUTE ADDRESS-L = LENGTH OF ADDRESS-STR - ADDRESS-L. DISPLAY ADDRESS-STR(1 : ADDRESS-L).
Output:
Account balance: -3222213.43 Account number: 23 8271 6271 8326 1000 8835 2182 Date: 2018/02/03 Time: 12:22:06 First name: Jan Last name: Sadek Norweska,48C,-,54-404,Wroclaw,Dolnoslaskie,Poland Age: 32 Some large number: 3283272392298 Coordinates: + 12.32873 : - 31.39282
At last, the output is formatted as desired but to do so we need to define many additional variables, play a little bit with PIC definitions and create three paragraphs for string manipulation. Comments: - If your goal is not to remove all blanks from the number but only put '-' sign next to the value you could use PIC -(16)9.99. Leading spaces would still exist but the number would be correctly presented as -3222213.43. - In above example, paragraphs are used in a similar manner to functions. It's not recommended since it makes code messy, it's much better to write such functions separately. We'll discuss that in one of the later Assignments. - You cannot remove blanks or justify NUMERIC or NUMERIC-EDITED variables. The only way to change the way they're displayed is to convert them to strings. - There is no TRIM function in COBOL. It may seem strange at first but the fact is that it is rarely needed in normal programming task so lack of it isn't that much of a problem. - Notice that in JOIN-ADDRESS paragraph ADDRESS-STR is initialized with " ". Uninitialized strings just like numbers are filled with nulls X'00'. During initialization, it is filled with spaces. So "MOVE " " TO ADDRESS-STR." works the same way as "MOVE SPACES TO ADDRESS-STR.". We need to do that so STRING function correctly recognizes the number of trailing spaces.
Solution 4
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP404) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP404. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 PROFITS. 05 DOLLARS PIC 9(16)V9(2). 05 CENTS REDEFINES DOLLARS PIC 9(18). 05 THOUSANDS REDEFINES DOLLARS PIC 9(13)V9(5). 05 MILLIONS REDEFINES DOLLARS PIC 9(10)V9(8). 05 BILLIONS REDEFINES DOLLARS PIC 9(7)V9(11). 01 PROFITS-EDI. 05 DOLLARS-EDI PIC Z(15)9.9(2). 05 CENTS-EDI PIC Z(17)9. 05 THOUSANDS-EDI PIC Z(12)9.9(5). 05 MILLIONS-EDI PIC Z(9)9.9(8). 05 BILLIONS-EDI PIC Z(6)9.9(11). 01 WORD PIC X(64). 01 BYTES REDEFINES WORD. 05 BYTE1 PIC X(8). 05 BYTE2 PIC X(8). 05 BYTE3 PIC X(8). 05 BYTE4 PIC X(8). 05 BYTE5 PIC X(8). 05 BYTE6 PIC X(8). 05 BYTE7 PIC X(8). 05 BYTE8 PIC X(8). 01 RESTART-FLAGS REDEFINES WORD. 05 FILLER PIC X(56). 05 NO-RESTART PIC X. 05 AUTO-RESTART PIC X. 05 USER-RESTART PIC X. 05 FILLER PIC X(5). PROCEDURE DIVISION. DISPLAY "Specify A:". ACCEPT DOLLARS. MOVE DOLLARS TO DOLLARS-EDI. MOVE CENTS TO CENTS-EDI. MOVE THOUSANDS TO THOUSANDS-EDI. MOVE MILLIONS TO MILLIONS-EDI. MOVE BILLIONS TO BILLIONS-EDI. DISPLAY "CENTS: " CENTS-EDI. DISPLAY "DOLLARS: " DOLLARS-EDI. DISPLAY "THOUSANDS: " THOUSANDS-EDI DISPLAY "MILLIONS: " MILLIONS-EDI DISPLAY "BILLIONS: " BILLIONS-EDI ACCEPT WORD. DISPLAY WORD. DISPLAY BYTE5. DISPLAY USER-RESTART. STOP RUN. //GO.SYSIN DD * 000000008261398232 1111000011010101010101101010101100111010101101010101010101110111
Output:
CENTS: 8261398232 DOLLARS: 82613982.32 THOUSANDS: 82613.98232 MILLIONS: 82.61398232 BILLIONS: 0.08261398232 1111000011010101010101101010101100111010101101010101010101110111 00111010 1
Comments: - REDEFINE clause is used to define more than one representation of the same data. This means that you cannot use it to redefine different the type of data, for example, NUMERIC to NUMERIC-EDITED or NUMERIC(COMP) to NUMERIC(COMP-5) since such variables differ from each other bit-wise. - REDEFINE definition must follow immediately variable that is being redefined. - In simplest term REDEFINES does not create a new variable but defines a new name for an existing variable. - In the above example, we could easily define WORD as a structure without the need of using REDEFINE clause but consider what happens if you want to refer to some bits separately. It would make structure definition very messy. With REDEFINE you can define as many names for the same data as you like and structure them in any way you like.
Solution 5
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP405) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP405. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC 999V999. 01 B PIC X(8). 01 AA PIC 99.99. 01 BB PIC X(6). PROCEDURE DIVISION. ACCEPT A. DISPLAY A. MOVE A TO AA. DISPLAY AA. ACCEPT A. DISPLAY A. MOVE A TO AA. DISPLAY AA. ACCEPT A. DISPLAY A. MOVE A TO AA. DISPLAY AA. ACCEPT B. DISPLAY B. MOVE B TO BB. DISPLAY BB. ACCEPT B. DISPLAY B. MOVE B TO BB. DISPLAY BB. ACCEPT B DISPLAY B. MOVE B TO BB. DISPLAY BB. STOP RUN. //GO.SYSIN DD * 002300 211000 392111 A Word Something My Variable
Output:
002300 02.30 211000 11.00 392111 92.11 A Word A Word Somethin Someth My Varia My Var
This Task shows how ACCEPT and MOVE functions handle data that doesn't fit variable definitions: - In case of moving smaller values to larger variables – spaces or zeros are added. - In case of moving larger numerics to smaller ones – left-most digits are truncated. - In case of moving larger numerics with a decimal point to smaller ones – decimal point position stays intact while left-most and right-most digits are truncated if needed. - In case of moving larger strings to smaller ones – right-most characters are truncated. Comments: - ACCEPT verb doesn't recognize decimal point. It accepts values as given so in the below example 1211 was not truncated although it doesn't fit 999V999 definition while 392.11112 will be truncated to 392.11 instead of 392.112 since the decimal point is treated as one character:
2.3 1211 392.11112 A word Something My Variable
- In case of ACCEPT verb, right-most characters that don't fit the PICTURE are always truncated. - You cannot use COMP var definitions with ACCEPT verb.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP406. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 STR1 PIC X(10). 01 STR1E1 PIC X(10) JUST RIGHT. 01 STR1E2 PIC X(3)BBX(1). 01 STR1E3 PIC /XBXBXBXBX/. 01 NBR1 PIC S9(5)V999. 01 NBR1E1 PIC -Z(4)9.999. 01 NBR1E2 PIC -9(5).99999. 01 NBR1E3 PIC -*(4)9.999. 01 NBR1E4 PIC -Z(4)9.99. 01 NBR1E4TEMP PIC S9(5)V99. 01 NBR1E5 PIC -----9.99. 01 NBR2 PIC 9(4). 01 NBR2E1 PIC +Z(4). 01 NBR2E2 PIC Z(4)+. 01 NBR2E3 PIC ZBZBZBZ. 01 NBR2E4 PIC 9,999,999.999,999. 01 NBR2E5 PIC $9B999.99. 01 NBR2E6 PIC 09/09/09/09. PROCEDURE DIVISION. PERFORM DISPLAY-STR1. PERFORM DISPLAY-NBR1. PERFORM DISPLAY-NBR2. STOP RUN. DISPLAY-NBR2. MOVE 4321 TO NBR2 NBR2E1 NBR2E2 NBR2E3 NBR2E4 NBR2E5 NBR2E6. DISPLAY ">" NBR2 "<". DISPLAY ">" NBR2E1 "<". DISPLAY ">" NBR2E2 "<". DISPLAY ">" NBR2E3 "<". DISPLAY ">" NBR2E4 "<". DISPLAY ">" NBR2E5 "<". DISPLAY ">" NBR2E6 "<". DISPLAY-NBR1. MOVE -832.118 TO NBR1 NBR1E1 NBR1E2 NBR1E3 NBR1E5. DISPLAY ">" NBR1 "<". DISPLAY ">" NBR1E1 "<". DISPLAY ">" NBR1E2 "<". DISPLAY ">" NBR1E3 "<". COMPUTE NBR1E4TEMP ROUNDED = NBR1 * 1. MOVE NBR1E4TEMP TO NBR1E4. DISPLAY ">" NBR1E4 "<". DISPLAY ">" NBR1E5 "<". DISPLAY-STR1. MOVE "Cobol" TO STR1 STR1E1 STR1E2 STR1E3. DISPLAY ">" STR1 "<". DISPLAY ">" STR1E1 "<". DISPLAY ">" STR1E2 "<". DISPLAY ">" STR1E3 "<".
Output:
>Cobol < > Cobol< >Cob o< >/C o b o l/< >0083211Q< >- 832.118< >-00832.11800< >-**832.118< >- 832.12< > -832.11< >4321< >+4321< >4321+< >4 3 2 1< >0,004,321.000,000< >$4 321.00< >04/03/02/01<
Comments: - JUST RIGHT clause recognizes spaces as characters. That's why moving PIC(10) variable with the same length won't justify the data even if it has only 5 chars like in this case:
... WORKING-STORAGE SECTION. 01 STR1 PIC X(10). 01 STR1E1 PIC X(10) JUST RIGHT. 01 STR1E2 PIC X(20) JUST RIGHT. ... MOVE "Cobol" TO STR1. DISPLAY ">" STR1 "<". MOVE STR1 TO STR1E1 STR1E2. DISPLAY ">" STR1E1 "<". DISPLAY ">" STR1E2 "<". ... Output: >Cobol < >Cobol < > Cobol <
- You can use multiple sign characters '-(3)9.' or '+(3)9.' if you want the sign to appear near the number instead of at the beginning of the numeric field. - Currency symbols can be put only at the beginning of the value. Just like in case of '-' and '+' you can use multiple currency signs '$$$$' if you want it to immediately precede the value.
Solution 7
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP407. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 COFFEE-RECEIPT. 05 COFFEE. 10 COFFEE-TYPE PIC X(20). 10 FILLER PIC X VALUE ";". 10 COFFEE-P PIC ZZ9. 05 FILLER PIC X VALUE ";". 05 MILK-P PIC Z9. 05 FILLER PIC X VALUE ";". 05 FOAM-P PIC Z9. 05 FILLER PIC X VALUE ";". 05 SUGAR-P PIC Z9. 05 FILLER PIC X VALUE ";". 05 CREAM-P PIC Z9. 05 FILLER PIC X VALUE ";". 05 SYRUP. 10 SYRUP-TYPE PIC X(20). 10 FILLER PIC X VALUE ";". 10 SYRUP-P PIC Z9. 05 FILLER PIC X VALUE ";". 05 ALCOHOL. 10 ALCOHOL-TYPE PIC X(20). 10 FILLER PIC X VALUE ";". 10 ALCOHOL-P PIC Z9. 66 CAPPUCCINO RENAMES COFFEE THRU SUGAR-P. PROCEDURE DIVISION. PERFORM SHOW-ME-CAPPUCCINO. STOP RUN. SHOW-ME-CAPPUCCINO. MOVE "ARABICA" TO COFFEE-TYPE. MOVE 40 TO COFFEE-P. MOVE 30 TO MILK-P. MOVE 30 TO FOAM-P. MOVE 0 TO SUGAR-P. DISPLAY CAPPUCCINO.
Comments: - This simple program presents the usage of special number 66. It's always used with RENAMES keyword and it defines another name or one or more variables. If you use it for referencing many variables they must be defined one after another. - You can achieve very similar results using REDEFINES clause although 66 items cannot be structures while you can use structures with REDEFINES clause.
Solution 8
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP408. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 EMPLOYEE. 05 FIRST-NAME PIC X(40). 05 LAST-NAME PIC X(40). 05 CURRENT-POSITION PIC X(40). 05 YEARS-OF-EXPERIENCE PIC 99. 88 RATE-1 VALUE 0. 88 RATE-2 VALUE 1 THRU 2. 88 RATE-3 VALUE 2 THRU 5. 88 RATE-4 VALUE 5 THRU 10. 88 RATE-5 VALUE 11 THRU 20. 88 RATE-6 VALUE 21 THRU 30. 88 RATE-7 VALUE 31 THRU 60. PROCEDURE DIVISION. ACCEPT FIRST-NAME. ACCEPT LAST-NAME. ACCEPT CURRENT-POSITION. ACCEPT YEARS-OF-EXPERIENCE. DISPLAY "FIRST NAME: " FIRST-NAME. DISPLAY "LAST NAME: " LAST-NAME. DISPLAY "POSITION: " CURRENT-POSITION. DISPLAY "EXPERIENCE: " YEARS-OF-EXPERIENCE " YEARS". EVALUATE TRUE WHEN RATE-1 DISPLAY "RATE: 20000-30000$/YEAR" WHEN RATE-2 DISPLAY "RATE: 25000-35000$/YEAR" WHEN RATE-3 DISPLAY "RATE: 32000-40000$/YEAR" WHEN RATE-4 DISPLAY "RATE: 35000-50000$/YEAR" WHEN RATE-5 DISPLAY "RATE: 40000-60000$/YEAR" WHEN RATE-6 DISPLAY "RATE: 50000-80000$/YEAR" WHEN RATE-7 DISPLAY "RATE: 60000-90000$/YEAR" END-EVALUATE. STOP RUN.
Comments: - 88 number is used for defining conditional variables. - Actually, those are not variables because they don't occupy any storage. 88 items are defined as variables but in reality, they are just an addition to conditional processing you can use with IF, EVALUATE and PERFORM statements. - Each 88 variable has FALSE or TRUE value depending on the value of its parent variable. - Although not really needed 88 variables are worth using for two reasons. The first is that they make code easier to understand. The second is that they can simplify and shorten complex condition checks. In total there are three special variable numbers: 66, 77 and 88. You've just learned about two of them. The purpose of the third, 77 is very simple, 77 variables must be level one items. That means that they cannot be base for a structure and cannot be part of a structure. From the point of view of program logic, you don't need 77 variables at all. They only give a programmer additional hint about the purpose of such variable and block some uses for the variable.
USAGE clause
Introduction
USAGE clause is part of PIC variable definition. It's used for defining special variable coding. For example, the default coding for NUMERIC variables is Zoned Decimal, which stores one digit on one byte which is not the most optimal solution when it comes to computations. So if you have a variable that is used primarily for calculation it's best to use binary or floating-point representation, to do that you need USAGE clause.
Tasks
![]() 1. Describe all variable types in COBOL language including:
- Possible USAGE for each type.
- Symbols allowed in PIC definition.
- Also, explain what each symbol in PIC definition means.
1. Describe all variable types in COBOL language including:
- Possible USAGE for each type.
- Symbols allowed in PIC definition.
- Also, explain what each symbol in PIC definition means.
![]() 2. Define variables for all numeric data types in COBOL in form of a structure:
- Move the following number to all those variables: -432.75, -999999382732432.327, and 138245511.
- Display all variables in their original form and after moving them to a NUMERIC-EDITED variable.
2. Define variables for all numeric data types in COBOL in form of a structure:
- Move the following number to all those variables: -432.75, -999999382732432.327, and 138245511.
- Display all variables in their original form and after moving them to a NUMERIC-EDITED variable.
![]() 3. Write a program that calculates factorial:
- You can use the program written in Task#4 of "PERFORM & GO TO" Assignment.
- Test program defining result variable as Zoned Decimal, Binary, Long Floating Point, and External Floating Point.
- Which type is the best for working with very large numbers?
3. Write a program that calculates factorial:
- You can use the program written in Task#4 of "PERFORM & GO TO" Assignment.
- Test program defining result variable as Zoned Decimal, Binary, Long Floating Point, and External Floating Point.
- Which type is the best for working with very large numbers?
![]() 4. Define an indexed table that will store 10000 numbers from 0-99 range:
- Populate the table with use of the RANDOM function.
- Search for all numbers that are multiplications of the number 27.
- Use another table with a set of items with USAGE INDEX. This table will store indexes (pointers) to the found numbers.
- Display all found numbers using the table with indexes.
4. Define an indexed table that will store 10000 numbers from 0-99 range:
- Populate the table with use of the RANDOM function.
- Search for all numbers that are multiplications of the number 27.
- Use another table with a set of items with USAGE INDEX. This table will store indexes (pointers) to the found numbers.
- Display all found numbers using the table with indexes.
![]() 5. Define two identical structures:
- In each of them put 5 digits of different length, for example, 9(1), 9(3), 9(4) etc.
- All numbers should be in binary format.
- Use SYNCHRONIZED clause for one structure.
- Display both structures as strings and compare the results.
5. Define two identical structures:
- In each of them put 5 digits of different length, for example, 9(1), 9(3), 9(4) etc.
- All numbers should be in binary format.
- Use SYNCHRONIZED clause for one structure.
- Display both structures as strings and compare the results.
Hint 1
A detailed description of all variable types available in COBOL can be found in "USAGE clause" sub-chapter of "Enterprise COBOL for z/OS: Language Reference" document.
Hint 4
You cannot use table element as an index but you can store index values in the table. The trick is to copy an index from the table to an elementary variable which is referenced by INDEX IS clause. This way you'll be able to display elements with indexes that are stored in a table.
Solution 1
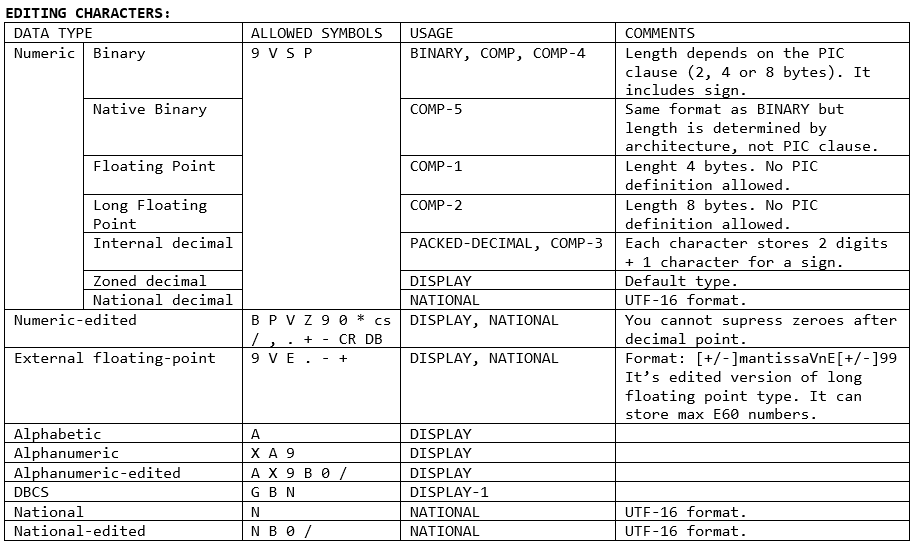
A – Alphabetic – A-Z, a-z, spaces. B – Blank – a space. E – Exponent – the place of an exponent in floating-point numbers. G – DBCS – DBCS character. N – National – UTF-16 character. P – Decimal point – used when the decimal point is not defined by the variable itself. S – Number sign ‘-‘ – can be specified both at the beginning or at the end of a number. V – Decimal point. X – Alphanumeric. Z – Zeros suppressor – it defines that, instead of ‘0’, space will be displayed. 9 – Numeric. 0 – Zero – Inserts ‘0’. / - Slash – Inserts ‘/’. , - Comma – Inserts ‘,’. . – Period – Inserts ‘.’ - in numeric specifies where the decimal point is. * - Asterix – works as Z but instead of spaces inserts ‘*’ in place of zeroes. cs – Currency symbol – inserts ‘$’ or other currency symbol specified in the ENVIRONMENTAL DIVISION. + - CR DB – editing sign control symbols. ‘+’ means that sigh is always shown while ‘-‘ will show the sign for negative numbers only.
Solution 2
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP502. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUMERICS. 05 FILLER PIC X(4) VALUE "ZD: ". 05 ZONED-DECIMAL PIC S9(15)V9(3). 05 FILLER PIC X(5) VALUE ",PD: ". 05 PACKED-DEC PIC S9(15)V9(3) USAGE COMP-3. 05 FILLER PIC X(5) VALUE ",BI: ". 05 BINARY-STD PIC S9(15)V9(3) USAGE COMP. 05 FILLER PIC X(6) VALUE ",NBI: ". 05 BINARY-NATIVE PIC S9(15)V9(3) USAGE COMP-5. 05 FILLER PIC X(5) VALUE ",FP: ". 05 FLOATING-POINT USAGE COMP-1. 05 FILLER PIC X(6) VALUE ",LFP: ". 05 LONG-FLOATING-POINT USAGE COMP-2. 05 FILLER PIC X(6) VALUE ",EFP: ". 05 EXT-FLOATING-POINT PIC -(12)9V9(3)E+99. 05 FILLER PIC X(6) VALUE ",NAT: ". 05 NATIONAL-NBR PIC S9(15)V9(3) SIGN IS LEADING SEPARATE USAGE NATIONAL. 05 FILLER PIC X VALUE ".". 77 TEST-NBR PIC S9(15)V9(3). 77 TEST-NBR-EDI PIC -(15)9.9(3). PROCEDURE DIVISION. MOVE -432.75 TO TEST-NBR. PERFORM DISPLAY-NUMERICS. MOVE -999999382732432.327 TO TEST-NBR. PERFORM DISPLAY-NUMERICS. MOVE 138245511 TO TEST-NBR. PERFORM DISPLAY-NUMERICS. STOP RUN. DISPLAY-NUMERICS. MOVE TEST-NBR TO ZONED-DECIMAL. MOVE TEST-NBR TO PACKED-DEC. MOVE TEST-NBR TO BINARY-STD. MOVE TEST-NBR TO BINARY-NATIVE. MOVE TEST-NBR TO FLOATING-POINT. MOVE TEST-NBR TO LONG-FLOATING-POINT. MOVE TEST-NBR TO NATIONAL-NBR. MOVE TEST-NBR TO EXT-FLOATING-POINT. DISPLAY NUMERICS. MOVE ZONED-DECIMAL TO TEST-NBR-EDI. DISPLAY "ZD: >>" TEST-NBR-EDI "<<". MOVE PACKED-DEC TO TEST-NBR-EDI. DISPLAY "PD: >>" TEST-NBR-EDI "<<". MOVE BINARY-STD TO TEST-NBR-EDI. DISPLAY "BI: >>" TEST-NBR-EDI "<<". MOVE BINARY-NATIVE TO TEST-NBR-EDI. DISPLAY "NBI: >>" TEST-NBR-EDI "<<". MOVE FLOATING-POINT TO TEST-NBR-EDI. DISPLAY "FP: >>" TEST-NBR-EDI "<<". MOVE LONG-FLOATING-POINT TO TEST-NBR-EDI. DISPLAY "LFP: >>" TEST-NBR-EDI "<<". MOVE NATIONAL-NBR TO TEST-NBR-EDI. DISPLAY "NAT: >>" TEST-NBR-EDI "<<". MOVE EXT-FLOATING-POINT TO TEST-NBR-EDI. DISPLAY "EFP: >>" TEST-NBR-EDI "<<".
Output:
ZD: 00000000000043275},PD: ,BI: 9 k,NBI: 9 k,FP: C ,LFP: C ,EFP: -432750000000000E-09,NAT: . ZD: >> -432.750<< PD: >> -432.750<< BI: >> -432.750<< NBI: >> -432.750<< FP: >> -432.750<< LFP: >> -432.750<< NAT: >> -432.750<< EFP: >> -432.750<< ZD: 99999938273243232P,PD: rrlb ',BI: 2 ,NBI: 2 ,FP: PY,LFP: PX Z ,EFP: -999999382732432E+03,NAT: . ZD: >>-999999382732432.327<< PD: >>-999999382732432.327<< BI: >>-999999382732432.327<< NBI: >>-999999382732432.327<< FP: >>-999999383000000.000<< LFP: >>-999999382732432.312<< NAT: >>-999999382732432.327<< EFP: >>-999999382732431.999<< ZD: 00000013824551100{,PD: ,BI: ,NBI: ,FP: cP ,LFP: cP ,EFP: 138245511000000E-03,NAT: . ZD: >> 138245511.000<< PD: >> 138245511.000<< BI: >> 138245511.000<< NBI: >> 138245511.000<< FP: >> 138245504.000<< LFP: >> 138245511.000<< NAT: >> 138245511.000<< EFP: >> 138245511.000<<
This example shows a few characteristics of different data types: - Using structure to display all numerics in character form allows us to see how much storage they actually occupy. Zoned Decimal (USAGE DISPLAY) and National are the largest. - Maximum allowed size for numerics in COBOL is 18 digits. As you can see all numeric formats except COMP-1 (floating-point) are sufficient to store this data. Also, external floating point number lost some accuracy because of its formatting. - If your goal is to save some storage and speed up calculation binary format is appropriate in most cases. - Size of most numeric types depends on PIC definition. The exception here is Native Binary, Floating-Point, and Long-Floating-Point types. - In case of binary items, they have either 2, 4, or 8 bytes: 2 bytes = PIC S9(4), 4 bytes = PIC S9(9), 8 bytes = PIC S9(18).
Solution 3
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP503. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC 9(2) VALUE 0. 01 K PIC 9(2). 01 RESULT PIC -9(16)VE+99. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM CALCULATE-FACTORIAL THROUGH DISPLAY-RESULT 50 TIMES. STOP RUN. CALCULATE-FACTORIAL. MOVE 1 TO RESULT. COMPUTE A = A + 1. PERFORM VARYING K FROM 1 BY 1 UNTIL K > A COMPUTE RESULT = RESULT * K ON SIZE ERROR PERFORM OVERFLOW-ERROR END-COMPUTE END-PERFORM. DISPLAY-RESULT. DISPLAY "Factorial of " A " is " RESULT. OVERFLOW-ERROR. DISPLAY "Overflow on number " K. STOP RUN.
Output:
*** PIC 9(18). *** Factorial of 18 is 006402373705728000 Factorial of 19 is 121645100408832000 Overflow on number 20 *** PIC 9(18) USAGE COMP. *** Factorial of 18 is 006402373705728000 Factorial of 19 is 121645100408832000 Overflow on number 20 *** COMP-2. *** Factorial of 48 is .12413915592536063E 62 Factorial of 49 is .60828186403426707E 63 Factorial of 50 is .30414093201713352E 65 *** PIC -(16)9VE+99. *** Factorial of 48 is 1241391559253606E+46 Factorial of 49 is 6082818640342669E+47 Factorial of 50 is 3041409320171334E+49
Comments: - You can see EXTERNAL FLOATING POINT data type as the edited version of LONG FLOATING POINT type (COMP-2) the same way NUMERIC EDITED is the edited version for other numerics. - The difference is that you cannot perform COMPUTE and some other numeric functions on NUMERIC EDITED items but you can on EXTERNAL FLOATING POINT. - LONG FLOATING POINT and its edited version are only numeric types in COBOL that can be used for storing and computing very large numbers. Still, you should be aware that the number always stored on 8 bytes so the larger the number the less accurate it becomes. - ON SIZE ERROR doesn't work with floating point numbers, instead, you'll get an abend near 60th exponent:
... Factorial of 54 is 2308436973392410E+56 Factorial of 55 is 1269640335365826E+58 Factorial of 56 is 7109985878048625E+59 CEE3212S The system detected an exponent-overflow exception (System Completion Code=0CC).
Solution 4
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP504. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM-TABLE. 05 NUM-RECORD OCCURS 10000 TIMES INDEXED BY NUM-IX. 10 NUM PIC 9(2). 01 IX-TABLE. 05 IX-RECORD OCCURS 10000 TIMES DEPENDING ON P1. 10 IX-PLACE USAGE IS INDEX. 77 K1 PIC 9(8) COMP. 77 P1 PIC 9(8) COMP. 77 SEARCHED-NUM PIC 9(2). 77 RAND-SEED PIC 9(8). PROCEDURE DIVISION. MAIN-LOGIC. MOVE 27 TO SEARCHED-NUM. PERFORM GENERATE-DATA. PERFORM SEARCH-NUMBER. * DISPLAY "BINARY REPRESENTATION OF THE FIRST 4 INDEXES:". * DISPLAY IX-TABLE(1:16). PERFORM DISPLAY-MOD7. STOP RUN. DISPLAY-MOD7. DISPLAY P1 " NUMBERS FOUND:". PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > P1 SET NUM-IX TO IX-PLACE(K1) DISPLAY NUM(NUM-IX) END-PERFORM. SEARCH-NUMBER. MOVE 0 TO P1. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 10000 IF FUNCTION REM(NUM(NUM-IX) SEARCHED-NUM) = 0 AND NUM(NUM-IX) NOT = 0 ADD 1 TO P1 SET IX-PLACE(P1) TO NUM-IX END-IF SET NUM-IX UP BY 1 END-PERFORM. GENERATE-DATA. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 10000 MOVE FUNCTION CURRENT-DATE (9:8) TO RAND-SEED COMPUTE RAND-SEED = RAND-SEED * K1 COMPUTE NUM(K1) ROUNDED = FUNCTION RANDOM(RAND-SEED) * 99 * DISPLAY NUM(K1) END-PERFORM.
Comments: - An indexed table does not necessarily need to be sorted in key order. You won't be able to use some functions on it such as binary search but you'll still be able to get an advantage of faster access to table elements via the index. That's why the serial search was used in this example. - You cannot reference a table in INDEX IS clause. So if you have a set of pointers (indexes) to specific table elements you'll have to copy their values to an index variable used in INDEX IS clause before using them. - As in any other programming language, RANDOM function works as designed only if a seed is given. Usually, the current time is given as a seed, but you should also remember about the speed of a computer. Hundreds of RANDOM function can be executed in one millisecond so they'll have the same seed. Because of this, it's also a good habit to use another variable, for example, loop iterator for seed generation. - RANDOM function always returns value between 0 and 1, so if you need it to generate a value from a specific array you need to multiply it by the maximum of the array. In this example, it generate a number between 0 and 99. The ROUNDED keyword is needed in such case. Without it, digits after the decimal point are trimmed. In result, the maximum value of such computation would be 98 instead of 99. - Notice that the table is searched with a loop and not a SEARCH function. The reason is simple, SEARCH functions terminate at the first found occurrence while we want to find all elements in the table that match search criteria. - If you had displayed an index you'd found that it's values really point to a particular byte-location in the table:
DISPLAY IX-TABLE(1:16). - Indexes are 4-byte variables so this way we'll display the first 4 indexes. SDSF ; '?' ; 'SE' on SYSOUT ; HEX ON - To display their binary representation open output in hex mode. ... À k m Y 000600090009000E 0004000200040028
So we have values 64, 92, 94, and 2E8 in the table. Those are byte-addresses of numbers that are the multiplication of 27. In decimal representation, these would be 100, 146, 148, and 744 byte. An address is counted from 0 so the first found element will be at byte-address 101, so 51 positions (each number is stored on 2 bytes in this example).
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP504. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM-TABLE1. 05 NUM11 PIC 9(1) COMP VALUE 3. 05 FILLER PIC X VALUE ";". 05 NUM12 PIC 9(5) COMP VALUE 3722. 05 FILLER PIC X VALUE ";". 05 NUM13 PIC 9(2) COMP VALUE 12. 05 FILLER PIC X VALUE ";". 05 NUM14 PIC 9(7) COMP VALUE 3928132. 05 FILLER PIC X VALUE ";". 05 NUM15 PIC 9(3) COMP VALUE 876. 01 NUM-TABLE2 SYNCHRONIZED. 05 NUM21 PIC 9(1) COMP VALUE 3. 05 FILLER PIC X VALUE ";". 05 NUM22 PIC 9(5) COMP VALUE 3722. 05 FILLER PIC X VALUE ";". 05 NUM23 PIC 9(2) COMP VALUE 12. 05 FILLER PIC X VALUE ";". 05 NUM24 PIC 9(7) COMP VALUE 3928132. 05 FILLER PIC X VALUE ";". 05 NUM25 PIC 9(3) COMP VALUE 876. PROCEDURE DIVISION. MAIN-LOGIC. DISPLAY "NON-SYNCHRONIZED TABLE: " DISPLAY NUM-TABLE1. DISPLAY "SYNCHRONIZED TABLE: " DISPLAY NUM-TABLE2. STOP RUN.
Output with HEX ON:
NON-SYNCHRONIZED TABLE: ------------------------ ; «; ; 0à; % 0050008500503F4506444444 03E00EAE0CE0B04E3C000000 ------------------------ SYNCHRONIZED TABLE: ------------------------ ; «; ; 0à; % 005000085000500003F45006 03E000EAE00CE0000B04E03C
Comments: - The first thing to notice is the difference in length between specific numbers. Length of binary items is assigned dynamically depending on PIC clause, so three smaller items are stored on 2 bytes and two larger ones on 4 bytes. - The second thing to notice is that when the SYNCHRONIZED clause is used each number starts a the beginning of the byte-address that is a multiplication of 2. It depends on the type of item, COMP items are funny because the ones the have max 4 digits are stored at a byte that is multiplication of 2, but bytes that have more than 4 digits start at a byte that is multiplication of 4, that why the fourth number seems to have 6 bytes instead of 4. - SYNC clause is usually used with COMP items. It's also recommended for table indexes. - Using SYNC clause is never needed but if you do thousands of millions of calculation or references by table index using SYNC will speed up the program.
Working with sequential files
Introduction
It's time to get into more practical tasks. COBOL is a programming language that excels in data processing, especially data organized in tables, where a record has a clearly defined structure. As a COBOL programmer, most of your activities will be related to data processing. This data will be most often taken from DB2 and various data sets. In this Assignment, you'll learn basics of file processing. For now, we'll focus on sequential files. In COBOL the term "file" is used but since we're working on z/OS those two terms "file" and "data set" are used interchangeably.
Tasks
![]() 1. Answer following questions:
- What file types can be processed by COBOL?
- What file open modes are available in COBOL?
- What access modes are available in COBOL?
- Describe all steps needed to process a file.
1. Answer following questions:
- What file types can be processed by COBOL?
- What file open modes are available in COBOL?
- What access modes are available in COBOL?
- Describe all steps needed to process a file.
![]() 2. Write a program that reads and displays a data set.
- Use ISPF to allocate the data set
- Populate it with data about countries population included in IEBGENER Assignment in Utilities Tab.
2. Write a program that reads and displays a data set.
- Use ISPF to allocate the data set
- Populate it with data about countries population included in IEBGENER Assignment in Utilities Tab.
![]() 3. Modify program written in Task#2:
- This time create a new file (without headers) with three new fictional countries.
- Structure the file the same way as the original data set from IEBGENER Assignment.
3. Modify program written in Task#2:
- This time create a new file (without headers) with three new fictional countries.
- Structure the file the same way as the original data set from IEBGENER Assignment.
![]() 4. Modify program written in Task#2:
- Merge two files, the original one from Task#2 (File A) and the one you've created in Task#3 (File B).
- Output (File A) should contain records in that order: Rec1 from FileA; Rec1 from FileB; Rec2 from FileA; Rec2 from FileB and so on, until all records from both files are written.
4. Modify program written in Task#2:
- Merge two files, the original one from Task#2 (File A) and the one you've created in Task#3 (File B).
- Output (File A) should contain records in that order: Rec1 from FileA; Rec1 from FileB; Rec2 from FileA; Rec2 from FileB and so on, until all records from both files are written.
![]() 5. Write a program that:
- Processes output from Task#4.
- Removes Doubling rate [years] column.
- Converts all numeric columns to COBOL format (Justifies them to the right).
- Saves output as a new file with appropriate record length.
5. Write a program that:
- Processes output from Task#4.
- Removes Doubling rate [years] column.
- Converts all numeric columns to COBOL format (Justifies them to the right).
- Saves output as a new file with appropriate record length.
![]() 6. Modify the program written in Task#5:
- Process output from Task#5.
- Remove countries with the population below 1000.
- Recalculate Population[%] and Annual Growth[%] columns.
- Switch Rank & Country columns with each other.
- Separate each column with ';'.
- Save output as a new file.
6. Modify the program written in Task#5:
- Process output from Task#5.
- Remove countries with the population below 1000.
- Recalculate Population[%] and Annual Growth[%] columns.
- Switch Rank & Country columns with each other.
- Separate each column with ';'.
- Save output as a new file.
![]() 7. Modify the program from Task#6 in such way that it doesn't create a new file but modifies the output from Task#5.
- You cannot delete records from sequential files, so instead of removing countries with less than 1000 people replace their names with "----" string. You'll fix that in the next Assignment.
7. Modify the program from Task#6 in such way that it doesn't create a new file but modifies the output from Task#5.
- You cannot delete records from sequential files, so instead of removing countries with less than 1000 people replace their names with "----" string. You'll fix that in the next Assignment.
![]() 8. Write a program that:
- Processes output from Task#7.
- Sorts countries by population in descending order.
- Removes countries marked "----" in the previous assignment.
- Rewrites Rank column.
- Saves output to UNIX file.
8. Write a program that:
- Processes output from Task#7.
- Sorts countries by population in descending order.
- Removes countries marked "----" in the previous assignment.
- Rewrites Rank column.
- Saves output to UNIX file.
![]() 9. Write a program that copies SMF records of a given type or all records, depending on the user selection:
- Use offloaded SMF logs.
- The program should accept one numeric parameter: 0-255 - copies SMF record of a specific type, 256 - copies all SMF records.
- The output file should have RECFM=VB.
- SMF records are spanned and can have more than 32760 bytes. Such records won't fit VB records. If a program encounters such record it should issue a warning message and after the processing is complete end with RC=4.
9. Write a program that copies SMF records of a given type or all records, depending on the user selection:
- Use offloaded SMF logs.
- The program should accept one numeric parameter: 0-255 - copies SMF record of a specific type, 256 - copies all SMF records.
- The output file should have RECFM=VB.
- SMF records are spanned and can have more than 32760 bytes. Such records won't fit VB records. If a program encounters such record it should issue a warning message and after the processing is complete end with RC=4.
![]() 10. Write a program that dynamically allocates 10 files with the same characteristics:
- The program should simply count records in each file and display it.
- Use offloaded SYSLOGs if possible. If not, use any set of sequential files with equal LRECL.
- What's the difference between allocating files via JCL and dynamically?
10. Write a program that dynamically allocates 10 files with the same characteristics:
- The program should simply count records in each file and display it.
- Use offloaded SYSLOGs if possible. If not, use any set of sequential files with equal LRECL.
- What's the difference between allocating files via JCL and dynamically?
![]() 11. Write a program that:
- Dynamically allocates PDS data set.
- Accepts user data via SYSIN (first name, last name, e-mail address, age).
- For each user, the program should create a new member in the PDS and copy the data from SYSIN there.
- PDS name should be passed via a parameter.
11. Write a program that:
- Dynamically allocates PDS data set.
- Accepts user data via SYSIN (first name, last name, e-mail address, age).
- For each user, the program should create a new member in the PDS and copy the data from SYSIN there.
- PDS name should be passed via a parameter.
Hint 1-3
You'll need to take a look at ENVIRONMENT, DATA and PROCEDURE divisions, especially INPUT-OUTPUT and FILE SECTION. Check "Enterprise COBOL for z/OS: Language Reference" for more info.
Hint 4
In case of sequential files you cannot simply insert records at the place you desire, to realize this program you'll have to use a third temporary file.
Hint 5
An intrinsic function NUMVAL will be helpful in this Task.
Hint 8
For more details about SORT statement see "SORT & MERGE" Assignment. Also, since we need to exclude some records before sort and edit all sorted record this program is a perfect candidate for using INPUT & OUTPUT PROCEDURES of SORT statement. See "SORT", "RELEASE", and "RETURN" chapters in "Enterprise COBOL for z/OS: Language Reference".
Hint 10
You'll need to call "SETENV" program to set an appropriate Environment Variable and by that allocate the file dynamically.
Hint 11
Dynamic dataset allocation via COBOL has many limitations. In order to create PDS or PDS/E data set, you must use DATACLAS. If you don't have appropriate DATACLAS and cannot define it, you can allocate PDS manually and code the rest of program functionality.
Solution 1
- What file types can be processed by COBOL? There are four file types, or rather file categories that can be processed by COBOL: - Sequential - Sequential data sets, PDS members, VSAM ESDS. - Indexed - VSAM KSDS, Indexed ESDS. - Relative - VSAM RRDS. - Line sequential - z/OS UNIX files. ________________________________________ - What file open modes are available in COBOL? There are four open modes: - INPUT – READ access. The file must exist. - OUTPUT – WRITE access. If the file does not exist, it is created. Existing records are deleted. - EXTEND – WRITE access. If the file does not exist, it is created. Existing records are kept and new ones are added at the end of the file. - I-O – READ and WRITE access. The file must exist. Existing records are kept and new ones are added at the end of the file. There is also a keyword OPTIONAL which enables you to use INPUT and I-O modes even if the file does not exist. ________________________________________ - What access modes are available in COBOL? There are three access modes: - Sequential – records are read sequentially, one-by-one until file ends. - Random – here user (programmer) specifies which records should be read, modified or added. - Dynamic – allows a programmer to use both modes, sequential and random. When it comes to file types: - Sequential – can use only sequential mode. - Indexed – can use all three modes. - Relative – can use all three modes. - Line sequential – can use only sequential mode. ________________________________________ - Describe all steps needed to process a file. The process of allocating and processing files is a bit complicated in COBOL, at least in comparison to other programming languages. 1. Define the file in FILE-CONTROL paragraph of INPUT-OUTPUT SECTION of ENVIRONMENT DIVISION. (SELECT clause, there are four versions of SELECT depending on the file type you're defining). 2. Define file definition in FILE SECTION of DATA DIVISION. (FD or SD data definitions). 3. Define record structure in FILE SECTION of DATA DIVISION. 4. Open the file in the desired mode. (OPEN function). 5. Process the file. (READ, WRITE, REWRITE, DELETE, START functions). 6. Close the file. (CLOSE function).
Solution 2
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP602) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP602. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT COUNTRY-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL. DATA DIVISION. FILE SECTION. FD COUNTRY-FILE RECORDING MODE F. 01 COUNTRY-RECORD. 05 COUNTRY-RANK PIC X(5). 05 COUNTRY-NAME PIC X(23). 05 COUNTRY-POPULATION PIC X(12). 05 COUNTRY-POPUL-PERC PIC X(16). 05 COUNTRY-GROWTH PIC X(16). 05 COUNTRY-GROW-PERC PIC X(20). 05 COUNTRY-DBL-RATE PIC X(21). WORKING-STORAGE SECTION. 77 EOF PIC X VALUE "N". PROCEDURE DIVISION. MAIN-LOGIC. OPEN INPUT COUNTRY-FILE. PERFORM READ-AND-DISPLAY-FILE. CLOSE COUNTRY-FILE. STOP RUN. READ-AND-DISPLAY-FILE. READ COUNTRY-FILE AT END MOVE "Y" TO EOF. PERFORM UNTIL EOF = "Y" DISPLAY COUNTRY-RECORD READ COUNTRY-FILE AT END MOVE "Y" TO EOF END-READ END-PERFORM. //GO.IN1 DD DISP=SHR,DSN=JSADEK.COUNTRY.DATA
Comments: - Name in SELECT clause is not data set name but DD name. Data set must be allocated by the party that executes COBOL program, in this case, GO step in our batch job. - It's a good habit to use the same prefix for all definition related to the file. - AT END option should be always used to test if the end of the file is reached. - To be sure you won't display empty line (in case data set is empty) you should read the first record before the processing loop. - Using this method, record processing should be done at the beginning of the loop (before the next record is read). - RECORDING MODE is used to specify record format of the data set. For COBOL program it doesn't matter if it's blocked. Valid options are F, V, S, and U.
Solution 3
COBOL code:
//CLEANUP EXEC PGM=IEFBR14 //DELDD DD DSN=JSADEK.COUNTRY.DATA.NEW, // SPACE=(TRK,1),DISP=(MOD,DELETE) //RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP603) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP603. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT COUNTRY-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL. DATA DIVISION. FILE SECTION. FD COUNTRY-FILE RECORDING MODE F. 01 COUNTRY-RECORD. 05 COUNTRY-RANK PIC X(5). 05 COUNTRY-NAME PIC X(23). 05 COUNTRY-POPULATION PIC X(12). 05 COUNTRY-POPUL-PERC PIC X(16). 05 COUNTRY-GROWTH PIC X(16). 05 COUNTRY-GROW-PERC PIC X(20). 05 COUNTRY-DBL-RATE PIC X(21). WORKING-STORAGE SECTION. 77 EOF PIC X VALUE "N". PROCEDURE DIVISION. MAIN-LOGIC. OPEN OUTPUT COUNTRY-FILE. PERFORM WRITE-NEW-COUNTRIES. CLOSE COUNTRY-FILE. STOP RUN. WRITE-NEW-COUNTRIES. MOVE "-" TO COUNTRY-RANK. MOVE "Middle-earth" TO COUNTRY-NAME. MOVE "123211554" TO COUNTRY-POPULATION. MOVE "-" TO COUNTRY-POPUL-PERC. MOVE "-23422232" TO COUNTRY-GROWTH. MOVE "-" TO COUNTRY-GROW-PERC. MOVE "-" TO COUNTRY-DBL-RATE. WRITE COUNTRY-RECORD. MOVE "-" TO COUNTRY-RANK. MOVE "Atlantis" TO COUNTRY-NAME. MOVE "0" TO COUNTRY-POPULATION. MOVE "0" TO COUNTRY-POPUL-PERC. MOVE "0" TO COUNTRY-GROWTH. MOVE "0" TO COUNTRY-GROW-PERC. MOVE "0" TO COUNTRY-DBL-RATE. WRITE COUNTRY-RECORD. MOVE "-" TO COUNTRY-RANK. MOVE "COBOL Land" TO COUNTRY-NAME. MOVE "2001232" TO COUNTRY-POPULATION. MOVE "-" TO COUNTRY-POPUL-PERC. MOVE "-100282" TO COUNTRY-GROWTH. MOVE "-" TO COUNTRY-GROW-PERC. MOVE "-" TO COUNTRY-DBL-RATE. WRITE COUNTRY-RECORD. //GO.OUT1 DD DSN=JSADEK.COUNTRY.DATA.NEW,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=113,BLKSIZE=11300,RECFM=FB
One great thing about COBOL is that file definition clearly describes what fields are stored in specific columns and also their data types. This makes file definitions longer but the actual file processing much easier.
Solution 4
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP604) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP604. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CTRYOLD-FILE ASSIGN TO CTRYOLD ORGANIZATION IS SEQUENTIAL. SELECT CTRYNEW-FILE ASSIGN TO CTRYNEW ORGANIZATION IS SEQUENTIAL. SELECT CTRYTMP-FILE ASSIGN TO CTRYTMP ORGANIZATION IS SEQUENTIAL. DATA DIVISION. FILE SECTION. FD CTRYOLD-FILE RECORDING MODE F. 01 CTRYOLD-RECORD PIC X(113). FD CTRYNEW-FILE RECORDING MODE F. 01 CTRYNEW-RECORD PIC X(113). FD CTRYTMP-FILE RECORDING MODE F. 01 CTRYTMP-RECORD PIC X(113). WORKING-STORAGE SECTION. 77 CTRYOLD-EOF PIC X VALUE "N". 77 CTRYNEW-EOF PIC X VALUE "N". 77 CTRYTMP-EOF PIC X VALUE "N". PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM READ-AND-JOIN-FILES. PERFORM REOPEN-FILES. PERFORM REPLACE-CTRYOLD. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN OUTPUT CTRYTMP-FILE. OPEN INPUT CTRYOLD-FILE. OPEN INPUT CTRYNEW-FILE. CLOSE-FILES. CLOSE CTRYTMP-FILE. CLOSE CTRYOLD-FILE. CLOSE CTRYNEW-FILE. REOPEN-FILES. CLOSE CTRYTMP-FILE. CLOSE CTRYOLD-FILE. OPEN INPUT CTRYTMP-FILE. OPEN OUTPUT CTRYOLD-FILE. READ-AND-JOIN-FILES. READ CTRYOLD-FILE AT END MOVE "Y" TO CTRYOLD-EOF. READ CTRYNEW-FILE AT END MOVE "Y" TO CTRYNEW-EOF. PERFORM UNTIL CTRYOLD-EOF = "Y" AND CTRYNEW-EOF = "Y" IF CTRYOLD-EOF = "N" MOVE CTRYOLD-RECORD TO CTRYTMP-RECORD WRITE CTRYTMP-RECORD READ CTRYOLD-FILE AT END MOVE "Y" TO CTRYOLD-EOF END-READ END-IF IF CTRYNEW-EOF = "N" MOVE CTRYNEW-RECORD TO CTRYTMP-RECORD WRITE CTRYTMP-RECORD READ CTRYNEW-FILE AT END MOVE "Y" TO CTRYNEW-EOF END-READ END-IF END-PERFORM. REPLACE-CTRYOLD. READ CTRYTMP-FILE AT END MOVE "Y" TO CTRYTMP-EOF. PERFORM UNTIL CTRYTMP-EOF = "Y" MOVE CTRYTMP-RECORD TO CTRYOLD-RECORD WRITE CTRYOLD-RECORD READ CTRYTMP-FILE AT END MOVE "Y" TO CTRYTMP-EOF END-READ END-PERFORM. //GO.CTRYTMP DD DSN=&&TEMPFILE,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=113,BLKSIZE=11300,RECFM=FB //GO.CTRYOLD DD DISP=OLD,DSN=JSADEK.COUNTRY.DATA //GO.CTRYNEW DD DISP=SHR,DSN=JSADEK.COUNTRY.DATA.NEW
Output:
Rank Country Population Population[%] Annual growth Annual growth[%] Doubling rate [years] - Middle-earth 123211554 - -23422232 - - 1 Russia 144031000 16.91 278000 0.19 368 - Atlantis 0 0 0 0 0 2 Germany 81459000 9.54 256000 0.32 220 - COBOL Land 2001232 - -100282 - - 3 Turkey 78214000 9.18 1035000 1.34 52 4 France 66484000 7.8 261022 0.39 177 5 United Kingdom 65081276 7.64 484000 0.75 92 ...
Comments: - In case of files processed sequentially, you cannot simply insert a record into a file. You can only read, add, or modify records. That's why we need to first read all files and then join their records into a single output. In this case, files are tiny and even table could be used to temporarily store all records in memory. Still, this solution is not acceptable in case of medium and large files. In such cases, it's best to use a temporary file as in the code above. - Notice that there is a logical error in this program. What would happen if the program abended during REPLACE-CTRYOLD function? Data from the original file could be lost. Fortunately, we would still have it in CTRYTMP but this file is defined in JCL as a temporary data set which is removed after the job ends. The simplest way to solve this issue is to add a new JCL step. This way GO step would allocate and catalog "temporary" file and if it ended with CC=0 the next step would remove it. This way, in case of the abend, even if the original file is damaged we would have a backup copy. There are also other solutions to this problem, it's mentioned here because as a programmer you must pay attention to such potential problems.
Solution 5
COBOL code:
//CLEANUP EXEC PGM=IEFBR14 //DELDD DD DSN=JSADEK.COUNTRY.DATA.V2, // SPACE=(TRK,(1,1)),DISP=(MOD,DELETE) //RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP605) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP605. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CTRYOLD-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL. SELECT CTRYNEW-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL. DATA DIVISION. FILE SECTION. FD CTRYOLD-FILE RECORDING MODE F. 01 CTRYOLD-RECORD. 05 CTRYOLD-RANK PIC X(5). 05 CTRYOLD-NAME PIC X(23). 05 CTRYOLD-POPULATION PIC X(12). 05 CTRYOLD-POPUL-PERC PIC X(16). 05 CTRYOLD-GROWTH PIC X(16). 05 CTRYOLD-GROW-PERC PIC X(20). 05 CTRYOLD-DBL-RATE PIC X(21). FD CTRYNEW-FILE RECORDING MODE F. 01 CTRYNEW-RECORD. 05 CTRYNEW-RANK PIC Z(3)9. 05 FILLER1 PIC X. 05 CTRYNEW-NAME PIC X(22). 05 FILLER2 PIC X. 05 CTRYNEW-POPULATION PIC Z(10)9. 05 FILLER3 PIC X. 05 CTRYNEW-POPUL-PERC PIC -(11)9.99. 05 FILLER4 PIC X. 05 CTRYNEW-GROWTH PIC -(14)9. 05 FILLER5 PIC X. 05 CTRYNEW-GROW-PERC PIC -(12)9.99. WORKING-STORAGE SECTION. 77 CTRYOLD-EOF PIC 9 VALUE 0. 77 COPYNUM PIC S9(16)V99. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM COPY-AND-CONVERT. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CTRYOLD-FILE. OPEN OUTPUT CTRYNEW-FILE. CLOSE-FILES. CLOSE CTRYOLD-FILE. CLOSE CTRYNEW-FILE. COPY-AND-CONVERT. PERFORM COPY-HEADER. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. PERFORM UNTIL CTRYOLD-EOF = 1 PERFORM COPY-RECORD WRITE CTRYNEW-RECORD READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF END-READ END-PERFORM. COPY-HEADER. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. MOVE CTRYOLD-RECORD(1:88) TO CTRYNEW-RECORD. WRITE CTRYNEW-RECORD. COPY-RECORD. MOVE " " TO FILLER1 FILLER2 FILLER3 FILLER4 FILLER5. MOVE CTRYOLD-NAME TO CTRYNEW-NAME. IF CTRYOLD-RANK(1:2) = "- " MOVE "0" TO CTRYOLD-RANK. IF CTRYOLD-POPULATION(1:2) = "- " MOVE "0" TO CTRYOLD-POPULATION. IF CTRYOLD-POPUL-PERC(1:2) = "- " MOVE "0" TO CTRYOLD-POPUL-PERC. IF CTRYOLD-GROWTH(1:2) = "- " MOVE "0" TO CTRYOLD-GROWTH. IF CTRYOLD-GROW-PERC(1:2) = "- " MOVE "0" TO CTRYOLD-GROW-PERC. COMPUTE COPYNUM = FUNCTION NUMVAL(CTRYOLD-RANK). MOVE COPYNUM TO CTRYNEW-RANK. COMPUTE COPYNUM = FUNCTION NUMVAL(CTRYOLD-POPULATION). MOVE COPYNUM TO CTRYNEW-POPULATION. COMPUTE COPYNUM = FUNCTION NUMVAL(CTRYOLD-POPUL-PERC). MOVE COPYNUM TO CTRYNEW-POPUL-PERC. COMPUTE COPYNUM = FUNCTION NUMVAL(CTRYOLD-GROWTH). MOVE COPYNUM TO CTRYNEW-GROWTH. COMPUTE COPYNUM = FUNCTION NUMVAL(CTRYOLD-GROW-PERC). MOVE COPYNUM TO CTRYNEW-GROW-PERC. //GO.IN1 DD DISP=SHR,DSN=JSADEK.COUNTRY.DATA //GO.OUT1 DD DSN=JSADEK.COUNTRY.DATA.V2,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=88,BLKSIZE=8800,RECFM=FB
Output:
Rank Country Population Population[%] Annual growth Annual growth[%] 0 Middle-earth 123211554 0.00 -23422232 0.00 1 Russia 144031000 16.91 278000 0.19 0 Atlantis 0 0.00 0 0.00 2 Germany 81459000 9.54 256000 0.32 0 COBOL Land 2001232 0.00 -100282 0.00 3 Turkey 78214000 9.18 1035000 1.34 4 France 66484000 7.80 261022 0.39 5 United Kingdom 65081276 7.64 484000 0.75 ...
Comments: - NUMVAL is a useful function which converts strings containing numbers to numeric variables. It's usually used with COMPUTE statement. - Input file also contains other data header and '-' characters that indicate that data is not present. Before using the NUMVAL function you must always ensure that the given field actually contains a numeric, otherwise, it will abend. - To keep a separation space FILLERn variables were defined. In case of files, you cannot use VALUE clause next to FILLER variables. It wouldn't make much sense anyway because file records are reinitialized each time a record is READ or WRITTEN.
Solution 6
COBOL code:
//CLEANUP EXEC PGM=IEFBR14 //DELDD DD DSN=JSADEK.COUNTRY.DATA.V3, // SPACE=(TRK,(1,1)),DISP=(MOD,DELETE) //RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP606) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP606. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CTRYOLD-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL. SELECT CTRYNEW-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL. DATA DIVISION. FILE SECTION. FD CTRYOLD-FILE RECORDING MODE F. 01 CTRYOLD-RECORD. 05 CTRYOLD-RANK PIC X(4). 05 FILLER PIC X. 05 CTRYOLD-NAME PIC X(22). 05 FILLER PIC X. 05 CTRYOLD-POPULATION PIC X(11). 05 FILLER PIC X. 05 CTRYOLD-POPUL-PERC PIC X(15). 05 FILLER PIC X. 05 CTRYOLD-GROWTH PIC X(15). 05 FILLER PIC X. 05 CTRYOLD-GROW-PERC PIC X(16). FD CTRYNEW-FILE RECORDING MODE F. 01 CTRYNEW-RECORD. 05 CTRYNEW-NAME PIC X(22). 05 FILLER1 PIC X. 05 CTRYNEW-RANK PIC X(4). 05 FILLER2 PIC X. 05 CTRYNEW-POPULATION PIC Z(10)9. 05 FILLER3 PIC X. 05 CTRYNEW-POPUL-PERC PIC -(11)9.99. 05 FILLER4 PIC X. 05 CTRYNEW-GROWTH PIC -(14)9. 05 FILLER5 PIC X. 05 CTRYNEW-GROW-PERC PIC -(12)9.99. WORKING-STORAGE SECTION. 77 CTRYOLD-EOF PIC 9 VALUE 0. 77 TNUM1 COMP-2. 77 TNUM2 COMP-2. 77 EUROPE-POPULATION PIC 9(11) COMP VALUE 0. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM SUM-PEOPLE. PERFORM REOPEN-INPUT. PERFORM COPY-AND-CONVERT. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CTRYOLD-FILE. OPEN OUTPUT CTRYNEW-FILE. CLOSE-FILES. CLOSE CTRYOLD-FILE. CLOSE CTRYNEW-FILE. REOPEN-INPUT. CLOSE CTRYOLD-FILE. OPEN INPUT CTRYOLD-FILE. MOVE 0 TO CTRYOLD-EOF. SUM-PEOPLE. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. PERFORM UNTIL CTRYOLD-EOF = 1 COMPUTE TNUM1 = FUNCTION NUMVAL(CTRYOLD-POPULATION) IF TNUM1 NOT < 1000 COMPUTE EUROPE-POPULATION = EUROPE-POPULATION + TNUM1 END-COMPUTE END-IF READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF END-READ END-PERFORM. COPY-AND-CONVERT. PERFORM COPY-HEADER. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. PERFORM UNTIL CTRYOLD-EOF = 1 PERFORM COPY-RECORD READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF END-READ END-PERFORM. COPY-HEADER. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. MOVE CTRYOLD-RECORD TO CTRYNEW-RECORD. MOVE ";" TO FILLER1 FILLER2 FILLER3 FILLER4 FILLER5. MOVE CTRYOLD-RANK TO CTRYNEW-RANK. MOVE CTRYOLD-NAME TO CTRYNEW-NAME. WRITE CTRYNEW-RECORD. COPY-RECORD. MOVE ";" TO FILLER1 FILLER2 FILLER3 FILLER4 FILLER5. COMPUTE TNUM1 = FUNCTION NUMVAL(CTRYOLD-POPULATION). IF TNUM1 > 999 MOVE TNUM1 TO CTRYNEW-POPULATION MOVE CTRYOLD-NAME TO CTRYNEW-NAME MOVE CTRYOLD-RANK TO CTRYNEW-RANK COMPUTE TNUM1 = TNUM1 / EUROPE-POPULATION * 100 MOVE TNUM1 TO CTRYNEW-POPUL-PERC COMPUTE TNUM1 = FUNCTION NUMVAL(CTRYOLD-GROWTH) MOVE TNUM1 TO CTRYNEW-GROWTH COMPUTE TNUM2 = FUNCTION NUMVAL(CTRYOLD-POPULATION) COMPUTE TNUM1 = TNUM1 / TNUM2 * 100 MOVE TNUM1 TO CTRYNEW-GROW-PERC WRITE CTRYNEW-RECORD END-IF. //GO.IN1 DD DISP=SHR,DSN=JSADEK.COUNTRY.DATA.V2 //GO.OUT1 DD DSN=JSADEK.COUNTRY.DATA.V3,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=88,BLKSIZE=8800,RECFM=FB
Output:
Country ;Rank;Population ;Population[%] ;Annual growth ;Annual growth[%] Middle-earth ; 0; 123211554; 12.61; -23422232; -19.01 Russia ; 1; 144031000; 14.74; 278000; 0.19 Germany ; 2; 81459000; 8.33; 256000; 0.31 COBOL Land ; 0; 2001232; 0.20; -100282; -5.01 Turkey ; 3; 78214000; 8.00; 1035000; 1.32 France ; 4; 66484000; 6.80; 261022; 0.39 United Kingdom ; 5; 65081276; 6.66; 484000; 0.74 ...
Comments: - This example nicely shows how important variable definitions are when it comes to calculations:
*** Definition *** 77 TNUM1 PIC S9(14)V99 COMP. 77 TNUM2 PIC S9(14)V99 COMP. *** Output *** Middle-earth 0 123211554 12.00 234222320 -19.00 Russia 1 144031000 14.00 2780000 0.00 *** Definition *** 77 TNUM1 PIC S9(14)V9999 COMP. 77 TNUM2 PIC S9(14)V9999 COMP. *** Output *** Middle-earth 0 123211554 12.60 234222320 -19.00 Russia 1 144031000 14.73 2780000 0.19 *** Definition *** 77 TNUM1 COMP-2. 77 TNUM2 COMP-2. *** Output *** Middle-earth 0 123211554 12.61 234222320 -19.01 Russia 1 144031000 14.74 2780000 0.19
First definition S9(14)V99 is not sufficient enough, digits after the decimal point are trimmed during COMPUTE statement. Another thing that's worth noticing is that moving S9(14)V9999 to -(11)9.99 trims last two digits while moving Long Floating Point COMP-2 to -(11)9.99 moves rounded value.
Solution 7
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP607) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP607. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CTRYOLD-FILE ASSIGN TO CTRYFILE ORGANIZATION IS SEQUENTIAL. DATA DIVISION. FILE SECTION. FD CTRYOLD-FILE RECORDING MODE F. 01 CTRYOLD-RECORD. 05 CTRYOLD-RANK PIC X(4). 05 FILLER PIC X. 05 CTRYOLD-NAME PIC X(22). 05 FILLER PIC X. 05 CTRYOLD-POPULATION PIC X(11). 05 FILLER PIC X. 05 CTRYOLD-POPUL-PERC PIC X(15). 05 FILLER PIC X. 05 CTRYOLD-GROWTH PIC X(15). 05 FILLER PIC X. 05 CTRYOLD-GROW-PERC PIC X(16). WORKING-STORAGE SECTION. 01 CTRYNEW-RECORD. 05 CTRYNEW-NAME PIC X(22). 05 FILLER1 PIC X. 05 CTRYNEW-RANK PIC X(4). 05 FILLER2 PIC X. 05 CTRYNEW-POPULATION PIC Z(10)9. 05 FILLER3 PIC X. 05 CTRYNEW-POPUL-PERC PIC -(11)9.99. 05 FILLER4 PIC X. 05 CTRYNEW-GROWTH PIC -(14)9. 05 FILLER5 PIC X. 05 CTRYNEW-GROW-PERC PIC -(12)9.99. 77 CTRYOLD-EOF PIC 9 VALUE 0. 77 TNUM1 COMP-2. 77 TNUM2 COMP-2. 77 EUROPE-POPULATION PIC 9(11) COMP VALUE 0. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM SUM-PEOPLE. PERFORM REOPEN-INPUT. PERFORM COPY-AND-CONVERT. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CTRYOLD-FILE. CLOSE-FILES. CLOSE CTRYOLD-FILE. REOPEN-INPUT. CLOSE CTRYOLD-FILE. OPEN I-O CTRYOLD-FILE. MOVE 0 TO CTRYOLD-EOF. SUM-PEOPLE. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. PERFORM UNTIL CTRYOLD-EOF = 1 COMPUTE TNUM1 = FUNCTION NUMVAL(CTRYOLD-POPULATION) IF TNUM1 NOT < 1000 COMPUTE EUROPE-POPULATION = EUROPE-POPULATION + TNUM1 END-COMPUTE END-IF READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF END-READ END-PERFORM. COPY-AND-CONVERT. PERFORM COPY-HEADER. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. PERFORM UNTIL CTRYOLD-EOF = 1 PERFORM COPY-RECORD READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF END-READ END-PERFORM. COPY-HEADER. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. MOVE CTRYOLD-RECORD TO CTRYNEW-RECORD. MOVE ";" TO FILLER1 FILLER2 FILLER3 FILLER4 FILLER5. MOVE CTRYOLD-RANK TO CTRYNEW-RANK. MOVE CTRYOLD-NAME TO CTRYNEW-NAME. MOVE CTRYNEW-RECORD TO CTRYOLD-RECORD. REWRITE CTRYOLD-RECORD. COPY-RECORD. COMPUTE TNUM1 = FUNCTION NUMVAL(CTRYOLD-POPULATION). IF TNUM1 < 1000 MOVE CTRYOLD-RECORD TO CTRYNEW-RECORD MOVE CTRYOLD-RANK TO CTRYNEW-RANK MOVE "----" TO CTRYNEW-NAME END-IF. IF TNUM1 > 999 MOVE TNUM1 TO CTRYNEW-POPULATION MOVE CTRYOLD-NAME TO CTRYNEW-NAME MOVE CTRYOLD-RANK TO CTRYNEW-RANK COMPUTE TNUM1 = TNUM1 / EUROPE-POPULATION * 100 MOVE TNUM1 TO CTRYNEW-POPUL-PERC COMPUTE TNUM1 = FUNCTION NUMVAL(CTRYOLD-GROWTH) MOVE TNUM1 TO CTRYNEW-GROWTH COMPUTE TNUM2 = FUNCTION NUMVAL(CTRYOLD-POPULATION) COMPUTE TNUM1 = TNUM1 / TNUM2 * 100 MOVE TNUM1 TO CTRYNEW-GROW-PERC END-IF. MOVE ";" TO FILLER1 FILLER2 FILLER3 FILLER4 FILLER5. MOVE CTRYNEW-RECORD TO CTRYOLD-RECORD. REWRITE CTRYOLD-RECORD. //GO.CTRYFILE DD DISP=OLD,DSN=JSADEK.COUNTRY.DATA.V2
Comments: - It's highly unusual to modify the file as presented in this example. Much easier and safer solution is to create new edited copy of the file, and if needed rename the files via JCL. If old version is not needed, it's best to remove it via JCL at the end of the job or in case of IWS Application at the beginning of the new occurrence of the Application. - Having said that, when you are writing a program that modifies a file it is always a good idea to first write a version that creates a new copy. This way you'll test program logic and computations without destroying original file. When everything is tested you can modify the program so it works on the desired file. Also, it goes without saying that you should always have a backup copy of the file you are working with. - REWRITE function enables us to modify the record that is currently being read. To do it you need to open it in "I-O" mode. - Notice that CTRYNEW-RECORD is still present in the program although only one file is opened. It was moved from FILE SECTION to WORKING-STORAGE SECTION. Keeping it not only saves us time but also has tested NUMERIC-EDITED variables which we would need anyway. Important: - It's a good place to mention one less-known programming rule. Programmer (your) time and code clarity are much more important that program optimization, especially in COBOL. So when you are coding an initial version of the program, forget about optimization. Focus on coding a clear, easy to understand and error-free code. Even after everything is tested, code optimization should be done only in most important loops, parts of the programs which are executed thousands and millions of times. The reason for that is simple, cost of programmers payment and time spend to figuring out messy code is much higher than few cycles of processor time.
Solution 8
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP608) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP608. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CTRYOLD-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL. SELECT CTRYNEW-FILE ASSIGN TO OUT1 ORGANIZATION IS LINE SEQUENTIAL. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. FD CTRYOLD-FILE RECORDING MODE F. 01 CTRYOLD-RECORD. 05 CTRYOLD-NAME PIC X(22). 05 FILLER PIC X. 05 CTRYOLD-RANK PIC X(4). 05 FILLER PIC X. 05 CTRYOLD-POPULATION PIC X(11). 05 FILLER PIC X. 05 CTRYOLD-POPUL-PERC PIC X(15). 05 FILLER PIC X. 05 CTRYOLD-GROWTH PIC X(15). 05 FILLER PIC X. 05 CTRYOLD-GROW-PERC PIC X(16). FD CTRYNEW-FILE RECORDING MODE F. 01 CTRYNEW-RECORD. 05 CTRYNEW-NAME PIC X(22). 05 FILLER PIC X. 05 CTRYNEW-RANK PIC Z(3)9. 05 FILLER PIC X. 05 CTRYNEW-POPULATION PIC X(11). 05 FILLER PIC X. 05 CTRYNEW-POPUL-PERC PIC X(15). 05 FILLER PIC X. 05 CTRYNEW-GROWTH PIC X(15). 05 FILLER PIC X. 05 CTRYNEW-GROW-PERC PIC X(16). SD SORTWRK-FILE. 01 SORTWRK-RECORD. 05 SORTWRK-NAME PIC X(22). 05 FILLER PIC X. 05 SORTWRK-RANK PIC X(4). 05 FILLER PIC X. 05 SORTWRK-POPULATION PIC X(11). 05 FILLER PIC X. 05 SORTWRK-POPUL-PERC PIC X(15). 05 FILLER PIC X. 05 SORTWRK-GROWTH PIC X(15). 05 FILLER PIC X. 05 SORTWRK-GROW-PERC PIC X(16). WORKING-STORAGE SECTION. 77 CTRYOLD-EOF PIC 9 VALUE 0. 77 SORTWRK-EOF PIC 9 VALUE 0. 77 HEADER PIC X(88). 77 K1 PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. DISPLAY SORT-MESSAGE. PERFORM OPEN-FILES. PERFORM SORT-RECORDS. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CTRYOLD-FILE. OPEN OUTPUT CTRYNEW-FILE. CLOSE-FILES. CLOSE CTRYOLD-FILE. CLOSE CTRYNEW-FILE. SORT-RECORDS. SORT SORTWRK-FILE DESCENDING KEY SORTWRK-POPULATION INPUT PROCEDURE PRE-SORT-PROC OUTPUT PROCEDURE POST-SORT-PROC. PRE-SORT-PROC. READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF. MOVE CTRYOLD-RECORD TO HEADER. PERFORM UNTIL CTRYOLD-EOF = 1 IF CTRYOLD-NAME NOT = "----" AND CTRYOLD-NAME NOT = "Country" RELEASE SORTWRK-RECORD FROM CTRYOLD-RECORD END-IF READ CTRYOLD-FILE AT END MOVE 1 TO CTRYOLD-EOF END-READ END-PERFORM. POST-SORT-PROC. MOVE HEADER TO CTRYNEW-RECORD. WRITE CTRYNEW-RECORD. RETURN SORTWRK-FILE RECORD INTO CTRYNEW-RECORD AT END MOVE 1 TO SORTWRK-EOF. PERFORM VARYING K1 FROM 1 BY 1 UNTIL SORTWRK-EOF = 1 MOVE K1 TO CTRYNEW-RANK WRITE CTRYNEW-RECORD RETURN SORTWRK-FILE RECORD INTO CTRYNEW-RECORD AT END MOVE 1 TO SORTWRK-EOF END-RETURN END-PERFORM. //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COUNTRY.DATA.V2 //GO.OUT1 DD PATH='/u/jsadek/countries.txt',PATHDISP=(KEEP,KEEP), // PATHOPTS=(OWRONLY,OCREAT),PATHMODE=(SIRWXU,SIRGRP,SIROTH) //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COUNTRY.DATA.V2
Output:
Country ;Rank;Population ;Population[%] ;Annual growth ;Annual growth[%] Russia ; 1; 144031000; 14.74; 278000; 0.19 Middle-earth ; 2; 123211554; 12.61; -23422232; -19.01 Germany ; 3; 81459000; 8.33; 256000; 0.31 Turkey ; 4; 78214000; 8.00; 1035000; 1.32 France ; 5; 66484000; 6.80; 261022; 0.39 United Kingdom ; 6; 65081276; 6.66; 484000; 0.74 Italy ; 7; 60963000; 6.24; 298000; 0.49 Spain ; 8; 46423064; 4.75; -28000; -0.06 Ukraine ; 9; 42850000; 4.38; -136000; -0.32 Poland ; 10; 38494000; 3.94; 20000; 0.05 ...
Comments: - Work files used for SORT and MERGE operation should be defined the same way as any other file. The only difference is that you must use SD instead of FD file definition in FILE-SECTION as assign them to temp. Also, you don't have to worry about OPEN and CLOSE instructions since it's managed by DFSORT. - If you have to process input records before sort you should use INPUT PROCEDURE keyword of SORT. RELEASE statement moves selected variable to SORT file. Similarly, if you need to process records after sort use OUTPUT PROCEDURE keyword and RETURN statement which works the same way as READ but reads sort work data set. - In this example, all columns in the file are defined in FILE SECTION. You don't need to do that, we work only on Rank & Population columns so Population [%], Growth, and Growth [%] could have been defined as one variable. Still, it's a good habit to always keep full file definition. It may become useful in the future during code updates and functionality changes. - To work on UNIX files you need only one modification in the COBOL code. You have to replace "ORGANIZATION IS SEQUENTIAL" to "ORGANIZATION IS LINE SEQUENTIAL", that's all. Data set allocation and creation is managed by JCL, or to be more specific system macros triggered by an initiator under which the job run so you don't have to worry about it in the code.
Solution 9
COBOL code:
//DELSTEP EXEC PGM=IEFBR14 //DELDD DD DSN=JSADEK.COBOL.MP609.SMFCOPY, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //RUNCOBOL EXEC IGYWCLG,PARM.GO='30' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP609) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP609. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT SMF-FILE ASSIGN TO SMFFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS SMF-STAT. SELECT OUT-FILE ASSIGN TO OUTFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS OUT-STAT. DATA DIVISION. FILE SECTION. FD SMF-FILE RECORDING MODE IS S RECORD IS VARYING IN SIZE FROM 1 TO 32763 CHARACTERS DEPENDING ON SMF-REC-SIZE BLOCK CONTAINS 0 CHARACTERS. 01 SMF-REC PIC X(32763). FD OUT-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 32752 CHARACTERS DEPENDING ON OUT-REC-SIZE. 01 OUT-REC PIC X(32752). WORKING-STORAGE SECTION. 77 SMF-EOF PIC 9. 77 SMF-STAT PIC XX. 77 SMF-REC-SIZE PIC 9(8) COMP. 01 SMF-REC-TYPE-STRUCT. 05 SMF-REC-TYPE PIC 9(3) COMP. 77 OUT-STAT PIC XX. 77 OUT-REC-SIZE PIC 9(8) COMP. 77 KA PIC 9(8) COMP. 77 KC PIC 9(8) COMP. 77 KS PIC 9(8) COMP. 77 KE PIC 9(8) COMP. 77 PARM-NUM PIC 9(3) COMP. LINKAGE SECTION. 01 PARM-REC. 05 PARM-LEN PIC 9(4) COMP-5. 05 PARM PIC X(4). PROCEDURE DIVISION USING PARM-REC. MAIN-LOGIC. PERFORM VERIFY-PARM. PERFORM OPEN-FILES. PERFORM COPY-SMF-RECORDS. PERFORM CLOSE-FILES. STOP RUN. COPY-SMF-RECORDS. MOVE 0 TO KC KS KE. DISPLAY "COPY STARTED.". PERFORM COPY-A-RECORD. PERFORM CHECK-SMF-FILE. PERFORM UNTIL SMF-EOF = 1 PERFORM COPY-A-RECORD END-PERFORM. DISPLAY "COPY DONE:". DISPLAY "RECORDS PROCESSED: " KA. DISPLAY "RECORDS CORRECTLY COPIED: " KC. DISPLAY "RECORDS SKIPPED DUE TO DIFFERENT TYPE: " KS. DISPLAY "RECORDS SKIPPED DUE TO LENGTH ERROR: " KE. IF KE > 0 MOVE 4 TO RETURN-CODE. COPY-A-RECORD. ADD 1 TO KA. READ SMF-FILE AT END MOVE 1 TO SMF-EOF. IF SMF-STAT = "39" OR SMF-REC-SIZE > 32752 DISPLAY "RECORD " KA " IS TOO LARGE (" SMF-REC-SIZE ")" MOVE "00" TO SMF-STAT ADD 1 TO KE ELSE MOVE SMF-REC(2 : 1) TO SMF-REC-TYPE-STRUCT(2 : 1) IF SMF-REC-TYPE = PARM-NUM OR PARM-NUM = 256 MOVE SMF-REC-SIZE TO OUT-REC-SIZE MOVE SMF-REC TO OUT-REC WRITE OUT-REC ADD 1 TO KC ELSE ADD 1 TO KS END-IF END-IF. OPEN-FILES. MOVE 0 TO SMF-EOF. OPEN INPUT SMF-FILE. PERFORM CHECK-SMF-FILE. OPEN OUTPUT OUT-FILE. PERFORM CHECK-OUT-FILE. CLOSE-FILES. CLOSE SMF-FILE. CLOSE OUT-FILE. VERIFY-PARM. IF PARM(1 : PARM-LEN) IS NOT NUMERIC DISPLAY "PARAMETER IS NOT A NUMBER: " PARM MOVE 16 TO RETURN-CODE PERFORM CLOSE-FILES STOP RUN ELSE IF FUNCTION NUMVAL(PARM(1 : PARM-LEN)) < 0 OR FUNCTION NUMVAL(PARM(1 : PARM-LEN)) > 256 DISPLAY "INCORRECT PARAMETER VALUE: " PARM MOVE 12 TO RETURN-CODE PERFORM CLOSE-FILES STOP RUN END-IF END-IF. COMPUTE PARM-NUM = FUNCTION NUMVAL(PARM(1 : PARM-LEN)). CHECK-SMF-FILE. IF SMF-STAT NOT = "00" DISPLAY "SMF FILE ERROR OCCURED. RC = " SMF-STAT MOVE SMF-STAT TO RETURN-CODE PERFORM CLOSE-FILES STOP RUN END-IF. CHECK-OUT-FILE. IF OUT-STAT NOT = "00" DISPLAY "OUT FILE ERROR OCCURED. RC = " OUT-STAT MOVE OUT-STAT TO RETURN-CODE PERFORM CLOSE-FILES STOP RUN END-IF. //GO.SMFFILE DD DISP=SHR,DSN=SYSU.SMF.DUMP.G0051V00 // DD DISP=SHR,DSN=SYSU.SMF.DUMP.G0052V00 // DD DISP=SHR,DSN=SYSU.SMF.DUMP.G0053V00 //GO.OUTFILE DD DSN=JSADEK.COBOL.MP609.SMFCOPY,DISP=(NEW,CATLG), // SPACE=(CYL,(5,20),RLSE),BLKSIZE=32760,LRECL=32756,RECFM=VB
Output:
COPY STARTED. COPY DONE: RECORDS PROCESSED: 00194370 RECORDS CORRECTLY COPIED: 00005729 RECORDS SKIPPED DUE TO DIFFERENT TYPE: 00188641 RECORDS SKIPPED DUE TO LENGTH ERROR: 00000000
Comments: - In this assignment, you've learned how to process variable and spanned records. - When working with variable records you must specify RECORD IS VARYING and DEPENDING ON clauses. - When working with spanned records you must additionally specify BLOCK CONTAINS CHARACTERS clause. - Notice that BLOCK CONTAINS specifies 0. In such case, the system will determine the optimal block size on the basis of file characteristic. This is recommended for two reasons. First, you don't have to worry about block size in your program. Second, BLOCK CONTAINS 0 has better performance. - Remember how VB records are structured: BLOCK = BDW + LRECL = BDW + RDW + Data length (32760 = max block size = 4 + LRECL = 4 + 4 + data length = 8 + 32752). - Of course those the above applies to VB format, in VBS block size can be shorter than LRECL. Therefoere: LRECL = 32767, BLKSIZE = 27998. 32767 – RDW (4 bytes) = 32763. - Another thing that's worth noticing is how character data is converted to binary form "MOVE SMF-REC(2 : 1) TO SMF-REC-TYPE-STRUCT(2 : 1)". SMF record is like a structure, it contains many different fields with various data types. Byte 2 is a record type, we copy this byte to the last byte of a variable which is interpreted by the program as a numeric in binary format.
Solution 10
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP610. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT LOG-FILE ASSIGN TO LOGFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS LOG-FS. DATA DIVISION. FILE SECTION. FD LOG-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 133 CHARACTERS DEPENDING ON LOG-REC-SIZE. 01 LOG-RECORD PIC X(133). WORKING-STORAGE SECTION. 77 LOG-EOF PIC 9. 77 LOG-FS PIC XX. 77 LOG-REC-SIZE PIC 9(9) COMP. 77 REC-COUNT PIC 9(8) COMP. 77 REC-COUNT-EDI PIC Z(7)9. 77 K1 PIC 9(4) COMP. 77 K1-EDI PIC 0099. 01 ENV-VARIABLES. 05 ENV-NAME PIC X(9). 05 ENV-VALUE PIC X(100). 05 ENV-OVERWRITE PIC S9(8) COMP. 77 DSNAME PIC X(44). 77 DSNAME-LEN PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. MOVE 1 TO ENV-OVERWRITE. MOVE Z"LOGFILE" TO ENV-NAME. PERFORM COUNT-RECORDS VARYING K1 FROM 15 BY 1 UNTIL K1 > 25. STOP RUN. COUNT-RECORDS. PERFORM OPEN-THE-FILE. READ LOG-FILE AT END MOVE 1 TO LOG-EOF. PERFORM CHECK-LOG-FILE. PERFORM UNTIL LOG-EOF = 1 ADD 1 TO REC-COUNT READ LOG-FILE AT END MOVE 1 TO LOG-EOF END-READ END-PERFORM. PERFORM CLOSE-THE-FILE. MOVE REC-COUNT TO REC-COUNT-EDI. DISPLAY "'" DSNAME(1 : DSNAME-LEN) "' CONTAINS " REC-COUNT-EDI " RECORDS.". OPEN-THE-FILE. MOVE 0 TO LOG-EOF REC-COUNT. MOVE 1 TO DSNAME-LEN. MOVE K1 TO K1-EDI. STRING "SYSU.MVS.SYSLOG.G" K1-EDI "V00" SPACES DELIMITED BY SIZE INTO DSNAME POINTER DSNAME-LEN. SUBTRACT 2 FROM DSNAME-LEN. STRING "DSN(" DELIMITED BY SIZE DSNAME DELIMITED BY SPACE ") SHR" DELIMITED BY SIZE LOW-VALUES DELIMITED BY SIZE INTO ENV-VALUE. CALL "SETENV" USING ENV-NAME ENV-VALUE ENV-OVERWRITE. OPEN INPUT LOG-FILE. PERFORM CHECK-LOG-FILE. CLOSE-THE-FILE. CLOSE LOG-FILE. PERFORM CHECK-LOG-FILE. CHECK-LOG-FILE. IF LOG-FS NOT = "00" AND "10" DISPLAY "FILE ERROR: " LOG-FS MOVE 12 TO RETURN-CODE STOP RUN END-IF.
Output:
'SYSU.MVS.SYSLOG.G0015V00' CONTAINS 218 RECORDS. 'SYSU.MVS.SYSLOG.G0016V00' CONTAINS 189 RECORDS. 'SYSU.MVS.SYSLOG.G0017V00' CONTAINS 71 RECORDS. 'SYSU.MVS.SYSLOG.G0018V00' CONTAINS 2684 RECORDS. 'SYSU.MVS.SYSLOG.G0019V00' CONTAINS 0 RECORDS. 'SYSU.MVS.SYSLOG.G0020V00' CONTAINS 0 RECORDS. 'SYSU.MVS.SYSLOG.G0021V00' CONTAINS 0 RECORDS. 'SYSU.MVS.SYSLOG.G0022V00' CONTAINS 0 RECORDS. 'SYSU.MVS.SYSLOG.G0023V00' CONTAINS 3585 RECORDS. 'SYSU.MVS.SYSLOG.G0024V00' CONTAINS 2759 RECORDS. 'SYSU.MVS.SYSLOG.G0025V00' CONTAINS 6814 RECORDS.
Comments: - SETENV program uses three arguments. The first one is the file name, so the name you use in ASSIGN clause which normally refers to DD name. The second argument is variable value which in this case is allocation command similar to TSO ALLOC. The last one is an overwrite indicator which in this case should be always equal to 1. - Environmental variables must always end with LOW-VALUES. That's why file name has 'PIC X(9)' definition. There can be max 8 letters, but there must be also a place for LOW-VALUE (X'00') at the end. Using 'Z' indicator in MOVE statement results in filling in empty bates with binary zeroes instead of spaces. - Also, applications of STRING function are worth looking at. DSNAME STRING function uses POINTER clause to save string length at the same time it's created. - When you allocate the file via JCL you don't have to worry about contention, SMS manages that. When you allocate the file dynamically via COBOL you must remember that if the file does not exist or is allocated by other program or user, your program will abend during execution. So in most situations it's easier and safer to allocate files via JCL. - Still, some activities can be done only with dynamic allocation, so you should keep in mind you have such possibility.
Solution 11
COBOL code:
//RUNCOBOL EXEC IGYWCLG,PARM.GO='JSADEK.COBOL.MP611.USER.DATA' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP611) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP611. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT USER-FILE ASSIGN TO USERFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS USER-FS. DATA DIVISION. FILE SECTION. FD USER-FILE RECORDING MODE IS F. 01 USER-RECORD PIC X(80). WORKING-STORAGE SECTION. 01 USER-DATA. 05 USER-FIRST-NAME PIC X(15). 05 USER-LAST-NAME PIC X(15). 05 USER-EMAIL PIC X(27). 05 USER-AGE PIC X(3). 77 USER-EOF PIC 9. 77 USER-FS PIC XX. 77 K1 PIC 9(4) COMP VALUE 0. 77 K1-EDI PIC 0999. 01 ENV-VARIABLES. 05 ENV-NAME PIC X(9). 05 ENV-VALUE PIC X(100). 05 ENV-OVERWRITE PIC S9(8) COMP. 77 MEMNAME PIC X(8). 77 IN-REC PIC X(80). LINKAGE SECTION. 01 PARM. 05 DSNAME-LEN PIC 9(4) COMP. 05 DSNAME PIC X(44). PROCEDURE DIVISION USING PARM. MAIN-LOGIC. PERFORM CREATE-PDS. MOVE LOW-VALUES TO IN-REC. ACCEPT IN-REC. PERFORM ACCEPT-USER UNTIL IN-REC = LOW-VALUES. STOP RUN. CREATE-PDS. MOVE 1 TO ENV-OVERWRITE. MOVE Z"USERFILE" TO ENV-NAME. STRING "DSN(" DSNAME(1 : DSNAME-LEN) "(USER0001)" ") NEW CYL SPACE(1,1) CATALOG DATACLAS(PDS80)" LOW-VALUES DELIMITED BY SIZE INTO ENV-VALUE. CALL "SETENV" USING ENV-NAME ENV-VALUE ENV-OVERWRITE. OPEN OUTPUT USER-FILE. PERFORM CHECK-USER-FILE. CLOSE USER-FILE PERFORM CHECK-USER-FILE. ACCEPT-USER. UNSTRING IN-REC DELIMITED BY ALL SPACES INTO USER-FIRST-NAME USER-LAST-NAME USER-EMAIL USER-AGE. PERFORM OPEN-MEMBER. PERFORM WRITE-USER-DATA-TO-MEMBER. PERFORM CLOSE-MEMBER. DISPLAY "MEMBER USER" K1-EDI " CREATED.". MOVE LOW-VALUES TO IN-REC. ACCEPT IN-REC. WRITE-USER-DATA-TO-MEMBER. MOVE SPACES TO USER-RECORD. STRING "FIRST NAME: " DELIMITED BY SIZE USER-FIRST-NAME DELIMITED BY SPACES INTO USER-RECORD. WRITE USER-RECORD. MOVE SPACES TO USER-RECORD. STRING "LAST NAME: " DELIMITED BY SIZE USER-LAST-NAME DELIMITED BY SPACES INTO USER-RECORD. WRITE USER-RECORD. MOVE SPACES TO USER-RECORD. STRING "EMAIL ADDRESS: " DELIMITED BY SIZE USER-EMAIL DELIMITED BY SPACES INTO USER-RECORD. WRITE USER-RECORD. MOVE SPACES TO USER-RECORD. STRING "AGE: " DELIMITED BY SIZE USER-AGE DELIMITED BY SPACES INTO USER-RECORD. WRITE USER-RECORD. OPEN-MEMBER. ADD 1 TO K1. MOVE K1 TO K1-EDI. STRING "DSN(" DSNAME(1 : DSNAME-LEN) "(USER" K1-EDI ")) SHR" LOW-VALUES DELIMITED BY SIZE INTO ENV-VALUE. CALL "SETENV" USING ENV-NAME ENV-VALUE ENV-OVERWRITE. OPEN OUTPUT USER-FILE. PERFORM CHECK-USER-FILE. CLOSE-MEMBER. CLOSE USER-FILE. PERFORM CHECK-USER-FILE. CHECK-USER-FILE. IF USER-FS NOT = "00" AND "10" DISPLAY "FILE ERROR: " USER-FS MOVE 12 TO RETURN-CODE STOP RUN END-IF. //GO.SYSIN DD * JAN SADEK SOME-EMAIL@GMAIL.COM 150 SARAH SMITH SARAH23@FAK.COM 34 TOM FRASIER FRA.TOM@OUTLOOK.COM THE GUY THEGUY@GUYTHE.NET
Comments: - Dynamic allocation in COBOL allows a very limited number of data set parameters. For example, you cannot specify LRECL, BLKSIZE, DSNTYPE and so on. This is usually not a problem since 99% of the times you'll use dynamic allocation against existing files. - Still, it's problematic if you want to create a new file like in this example. There is one workaround to that limitations, using SMS DATACLAS. With it, you can create any data set you want. But, you need to have a set of ready to use DATACLASses or ask Storage team to create them.
Working with indexed and relative files
Introduction
VSAM data sets are a quite complex subject. Having a basic understanding about their structure and processing principles is mandatory for every COBOL programmer. That's why if you're new to VSAM files it may be a good idea to first familiarize yourself with them. There is a great RedBook "VSAM Demystified" which will be helpful here. The most popular VSAM data set type is KSDS, you'll be working with it most often. You can see KSDS as a table in relational database. There are many similarities between those two structures. Both must have a primary key and can have many secondary keys. Primary key columns must be always sorted since record retrieval depends on that. Both have clearly defined columns. Although records in KSDS can have any structure this is how most often they are organized. In both structures, there are chunks of free space that make record insertion faster. In this Assignment, you'll work on data that represents a basic customer record that may be used in internet shop for instance (yes, I would also like to have an internet business that can afford using mainframes). Records will have a total length of 101 bytes and following fields: - Customer number - 8 bytes (numeric) - First name - 20 bytes - Last name - 20 bytes - E-mail address - 30 bytes - Birth date - 10 bytes - Registration date - 10 bytes - Account status - 1 byte (N(normal), D(discount eligible), S(suspended), I(inactive, not used for 3 years)) - Discount - 2 bytes (numeric, customer discount in %)
Tasks
![]() 1. Allocate three VSAM data sets with IDCAMS: KSDS, RRDS, and ESDS. Describe following parameters of VSAM data sets:
- Cluster
- Data Component
- Index Component
- Key
- Alternate Index
- Path
- Control Interval
- Control Area
- FREESPACE
- BUFFERSPACE
- REUSE
- SHAREOPTIONS
1. Allocate three VSAM data sets with IDCAMS: KSDS, RRDS, and ESDS. Describe following parameters of VSAM data sets:
- Cluster
- Data Component
- Index Component
- Key
- Alternate Index
- Path
- Control Interval
- Control Area
- FREESPACE
- BUFFERSPACE
- REUSE
- SHAREOPTIONS
![]() 2. Create a program that writes 5 records into KSDS data set.
- The program should accept customer data via SYSIN.
2. Create a program that writes 5 records into KSDS data set.
- The program should accept customer data via SYSIN.
![]() 3. Create a program that reads the file populated in Task#2:
- First, use sequential access to display all its records.
- Next, use direct(random) access to display record 4 and then 2.
- At last, use skip-sequential access to display records 2 to 4.
3. Create a program that reads the file populated in Task#2:
- First, use sequential access to display all its records.
- Next, use direct(random) access to display record 4 and then 2.
- At last, use skip-sequential access to display records 2 to 4.
![]() 4. Join & modify the code from Task#2 & Task#3:
- Copy KSDS records into RRDS.
- Add two new customers. First, add a customer with ID 1000 and then with 500.
- Display all records sequentially, then records 500 & 2 randomly and finally records 4-1000 skip-sequentially.
4. Join & modify the code from Task#2 & Task#3:
- Copy KSDS records into RRDS.
- Add two new customers. First, add a customer with ID 1000 and then with 500.
- Display all records sequentially, then records 500 & 2 randomly and finally records 4-1000 skip-sequentially.
![]() 5. Modify program from Task#4:
- Include FILE STATUS clause to check file status key and VSAM return code.
- Test all file operations for their RC. Which RC is ok?
- Generate all types of file errors that come to your mind and check how the program behaves.
5. Modify program from Task#4:
- Include FILE STATUS clause to check file status key and VSAM return code.
- Test all file operations for their RC. Which RC is ok?
- Generate all types of file errors that come to your mind and check how the program behaves.
![]() 6. Divide source code from Task#4 to perform following activities:
- Copy records from RRDS to ESDS.
- Display copied records sequentially.
- Use IDCAMS to allocate Index for ESDS.
- Write a second program which displays all records of ESDS data set sequentially, randomly and skip-sequentially.
6. Divide source code from Task#4 to perform following activities:
- Copy records from RRDS to ESDS.
- Display copied records sequentially.
- Use IDCAMS to allocate Index for ESDS.
- Write a second program which displays all records of ESDS data set sequentially, randomly and skip-sequentially.
![]() 7. Define two additional indexes to KSDS data set, one unique (e-mail address) and one non-unique (full name).
- Write a program in which user decides which key to use and then specifies the record to display.
- In case of non-unique index make sure that all records with given key are displayed.
- Also, verify user input before file operations.
7. Define two additional indexes to KSDS data set, one unique (e-mail address) and one non-unique (full name).
- Write a program in which user decides which key to use and then specifies the record to display.
- In case of non-unique index make sure that all records with given key are displayed.
- Also, verify user input before file operations.
![]() 8. Modify the program from Task#7. Add following functionality:
- Displaying all records in KSDS.
- Adding a new record.
- Modifying an existing record.
- Deleting a record.
- In add and update operations: Verify that given values are correct.
- In add operation: first name, last name, e-mail address, and birth date should be mandatory. If other fields are left blank their values should be assigned automatically.
- Registration date field should be read-only.
8. Modify the program from Task#7. Add following functionality:
- Displaying all records in KSDS.
- Adding a new record.
- Modifying an existing record.
- Deleting a record.
- In add and update operations: Verify that given values are correct.
- In add operation: first name, last name, e-mail address, and birth date should be mandatory. If other fields are left blank their values should be assigned automatically.
- Registration date field should be read-only.
![]() 9. Modify the program written in Task#8:
- Now, all add, update, and delete operations should be logged into sequential data set.
- Log data set should be considered optional. If it's not allocated to the program, it won't be used but the program should work as intended.
- One file operation should produce a single record with: time stamp, operation type, and the processed record.
9. Modify the program written in Task#8:
- Now, all add, update, and delete operations should be logged into sequential data set.
- Log data set should be considered optional. If it's not allocated to the program, it won't be used but the program should work as intended.
- One file operation should produce a single record with: time stamp, operation type, and the processed record.
Hint 1
You can find more on VSAM data sets in "DFSMS Access Method Services Commands" and in "VSAM Demystified" RedBook. When testing your programs it's worth allocating data sets with REUSE keyword. This way you'll be able to completely rewrite the data in them each time your program runs. Still, keep in mind that REUSE keyword cannot be used for data sets for which use Alternate Indexes.
Hint 2
To be able to rewrite KSDS you need to use REUSE option during its allocation and open it for OUTPUT. You should carefully consider if you need REUSE option but in case of COBOL source testing ability to rewrite VSAM data sets may be useful. Just remember that except initial data load opening VSAM file for output will either clear all the data in it or cause an abend (if NOREUSE option is used).
Hint 4
Records in RRDS are not referenced by a key but RRN which is simply a record number (record slot in the data set). In theory, CUST-ID column could be mapped to RRN but in this case record with CUST-ID = 500 will be written after 495 empty records after the one with CUST-ID = 5 which is a huge waste of space.
Hint 5
You can check what each file status key means in Table 32 "File status key values and meanings" of "Enterprise COBOL for z/OS: Language Reference".
Hint 6
There is a little but important difference between SELECT clause for sequential and ESDS data sets. Check "ASSIGN clause" sub-chapter in "Enterprise COBOL for z/OS: Language Reference".
Hint 7
You'll need to use KEY IS phrase in READ statement. Also, be careful during AIX allocation with defining columns where alternate keys start. IDCAMS columns count start with 0 not 1. For details about defining alternate indexes check "DFSMS Access Method Services Commands" and "VSAM Demystified" documents.
Solution 1
VSAM data sets allocation:
//ALLOC EXEC PGM=IDCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE CLUSTER( - NAME(JSADEK.CUSTOMER.KSDS) - CYLINDERS(1 2) - FREESPACE(20 20) - INDEXED - KEYS(8 0) - REUSE - RECORDSIZE(101 101) - ) DEFINE CLUSTER( - NAME('JSADEK.CUSTOMER.RRDS') - CYLINDERS(1 2) - FREESPACE(20 20) - NUMBERED - REUSE - RECORDSIZE(101 101) - ) DEFINE CLUSTER( - NAME('JSADEK.CUSTOMER.ESDS') - CYLINDERS(1 2) - FREESPACE(20 20) - NONINDEXED - REUSE - RECORDSIZE(101 101) - )
VSAM Terms: - Cluster At its basis cluster is simply a catalog entry that describes parameters of VSAM data set. Cluster joins VSAM data set components (DATA, INDEX, AIX, PATH) etc. The term "Cluster" is also used to refer to VSAM data set as a whole (all its components). - Data Component Data set in which the data is stored. Record structure depends on the data set type. To display VSAM data sets you need IDCAMS, your own COBOL program or additional software such as FileAID, ISPF Editor doesn't support VSAM files yet. - Index Component Index Component doesn't store any actual data, just pointers to specific places in Data Component. Having an index makes data structure more complicated but it enables very fast access to selected records. Thanks to index and VSAM data sets structure, data set operations (record addition, deletion, updates, retrieval) are done very quickly and efficiently. See "KSDS numerical example" Figure in VSAM Demistyfied for a better understanding of how Index search works. - Key Key in VSAM data set is the same thing as Primary Key in relational databases. It must be unique and is used for record identification via Indexed searched just mentioned. Data in the Primary Key column must be sorted. - Alternate Index This is an optional component, a second Index. It enables you to use alternate (secondary) key. Imagine a situation in which you want to allow users of your website to login with Personal Number or e-mail address. You may use Personal Number as the primary key for data set operations and use Alternate Index to allow login via e-mail address. You could realize that functionality without Alternate Index but in such case, you would have to search your customer list sequentially which is unacceptable in case of any large data sets. With Alternate Index customer record will be found via indexed search which if very fast. - Path A path is an additional component that must be defined alongside Alternate Index. It stores only one column of Data Component and pointers to the related records in the Data Component. VSAM data sets are always sorted by primary (main) key which is a requirement for indexed search. Of course, records are not sorted by alternate key, that's why we need Path (sorted copy of the alternate key (one column of data component)) to be able to use it for indexed file access by alternate key. - Control Interval This is a data structure in VSAM data sets. It consists of a set of records, free space that enables us to efficiently insert new records in any place of the data set and some control fields which define position and length of records stored in the particular Control Interval. - Control Area Another data structure. It's a set of Control Intervals. In a way, a Control Interval for Control Area is the same thing as Record to Control Interval. Each Control Area has some free space to enable Control Interval split. Basically, when the free space in Control Interval ends a new CI is created and records from the old one are divided between those two CIs. The new CI uses up a free space in Control Area. When free space in CA ends, similarly a new CA is created and its CIs are divided between those two new CAs. Seems complicated but this way of space management minimalizes need of data reorganization after record addition and deletion. - FREESPACE Free space parameter defines the amount of free space left in CAs and CIs. There is no optimal value for this parameter, it all depends on how the data set will be used. If you'll assign to much free space you'll waste DASD space and if you'll assign to little free space you'll increase the frequency of CI and CA splits. - BUFFERSPACE Let's imagine you add or modify a record. First VSAM access method searches Index for the CI where the record is stored (or should be added). Next, it reads it from DASD into Central Storage (RAM). The actual addition or modification operation is done in RAM. When it's finished the entire CI is rewritten to DASD. The buffer is the amount of space in RAM for CIs. It's optional parameter and usually, it's best to left it to default. - REUSE This parameter defines if you can rewrite data in VSAM data set. You can see reusable clusters as temporary files where data is not supposed to be kept for long. For example, it may be used for storing some data temporarily (during the week) until it's copied to tapes, after that the data set is cleared and reused for storing records from the next week. - SHAREOPTIONS It defines how the data set is locked during its processing. OPT1 is similar to standard data set locking, many users can read the data set but write access blocks all other operations. OPT2 means that write operation won't block read requests, although still, only one write operation can run at a time. OPT3 and OPT4 require VSAM RLS (Record Level Sharing) which means that write operation will lock only one record, the one that updated, so many write and read operations can run at the same time. You specify the above options for two scopes, system-scope (with GRS this also applies to parallel sysplex) and crosssystem so when many systems have access to the data set.
Solution 2
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP702) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP702. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO CUSTOMER ORGANIZATION IS INDEXED RECORD KEY IS CUST-ID ACCESS MODE IS DYNAMIC. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-FNAME PIC X(20). 05 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. PROCEDURE DIVISION. MAIN-LOGIC. OPEN OUTPUT CUST-FILE. PERFORM POPULATE-THE-FILE. CLOSE CUST-FILE. STOP RUN. POPULATE-THE-FILE. MOVE SPACES TO CUST-RECORD ACCEPT CUST-ID. PERFORM UNTIL CUST-ID = SPACES ACCEPT CUST-FNAME ACCEPT CUST-LNAME ACCEPT CUST-EMAIL ACCEPT CUST-BIRTH-DATE ACCEPT CUST-REG-DATE ACCEPT CUST-ACC-STATUS ACCEPT CUST-DISCOUNT WRITE CUST-RECORD INVALID KEY PERFORM INV-KEY-MSG END-WRITE DISPLAY "RECORD " CUST-ID " WRITTEN:" DISPLAY CUST-RECORD MOVE SPACES TO CUST-RECORD ACCEPT CUST-ID END-PERFORM. INV-KEY-MSG. DISPLAY CUST-ID " IS AN INVALID KEY. PROGRAM ENDS.". STOP RUN. //GO.CUSTOMER DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS //********************************************************************* //* SPECIFY FOLLOWING FIELDS, ONE IN EACH LINE: //* - CUSTOMER NUMBER - 8 BYTES (NUMERIC) //* - FIRST NAME - 20 BYTES //* - LAST NAME - 20 BYTES //* - E-MAIL ADDRESS - 30 BYTES //* - BIRTH DATE - 10 BYTES //* - REGISTRATION DATE - 10 BYTES //* - ACCOUNT STATUS - 1 BYTE (N(NORMAL), D(DISCOUNT ELIGIBLE), //* S(SUSPENDED), I(INACTIVE, NOT USED FOR 3 YEARS)) //* - DISCOUNT - 2 BYTES (NUMERIC, CUSTOMER DISCOUNT IN %) //********************************************************************* //GO.SYSIN DD * 00000001 Mark Smith mark.smith@hell.com 1982-01-30 2018-02-18 N 00 ...
Comments: - For indexed and relative files DYNAMIC access mode is almost always used. It enables you to use both sequential and random operation in your program. There is no need to limit your program flexibility by specifying only RANDOM os SEQUENTIAL mode. Important: - Opening file for OUTPUT clears VSAM data set. If you used REUSE option during Cluster allocation all record will be removed during file opening. If you used NOREUSE option the program will end in error. That's why when updating VSAM data set you must always open the file in I-O mode.
Solution 3
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP703) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP703. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO CUSTOMER ORGANIZATION IS INDEXED RECORD KEY IS CUST-ID ACCESS MODE IS DYNAMIC. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-FNAME PIC X(20). 05 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. 77 CUST-EOF PIC 9 VALUE 0. PROCEDURE DIVISION. MAIN-LOGIC. OPEN INPUT CUST-FILE. PERFORM SEQUENTIAL-READ. PERFORM RANDOM-READ. PERFORM SKIP-SEQUENTIAL-READ. CLOSE CUST-FILE. STOP RUN. SEQUENTIAL-READ. DISPLAY "SEQUENTIAL READ:". READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. RANDOM-READ. DISPLAY "RANDOM READ:" MOVE 4 TO CUST-ID. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. DISPLAY CUST-RECORD. MOVE 2 TO CUST-ID. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. DISPLAY CUST-RECORD. SKIP-SEQUENTIAL-READ. DISPLAY "SKIP SEQUENTIAL READ:" MOVE 0 TO CUST-EOF. MOVE 2 TO CUST-ID. START CUST-FILE KEY IS EQUAL TO CUST-ID INVALID KEY PERFORM INV-KEY-MSG. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM UNTIL CUST-ID > 4 OR CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. INV-KEY-MSG. DISPLAY CUST-ID " IS AN INVALID KEY. PROGRAM ENDS.". STOP RUN. //GO.CUSTOMER DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS
Output:
SEQUENTIAL READ: 00000001Mark Smith mark.smith@hell.com 1982-01-302018-02-18N00 00000002Hanna Panna your.bunny@fm.com 1999-01-302018-01-11D30 00000003Pennywise - letsfloat@fun.edu 1911-07-102017-12-15D95 00000004Dick Ditch ddman@gmail.com 1964-11-052018-02-01S00 00000005Ian Lobocetahi cob.ol.lol@yahoo.com 1982-01-302018-02-18I03 RANDOM READ: 00000004Dick Ditch ddman@gmail.com 1964-11-052018-02-01S00 00000002Hanna Panna your.bunny@fm.com 1999-01-302018-01-11D30 SKIP SEQUENTIAL READ: 00000002Hanna Panna your.bunny@fm.com 1999-01-302018-01-11D30 00000003Pennywise - letsfloat@fun.edu 1911-07-102017-12-15D95 00000004Dick Ditch ddman@gmail.com 1964-11-052018-02-01S00
Comments: - You already know sequential data access. The file is read from the beginning to the end one record after another. - Direct (or random) access requires you to specify the key. It's allowed only in Indexed and Relative files. To use direct access you need to know the key of the record you want to work with. - Skip-sequential access is a combination of both those methods. The first record is accessed directly, next records are processed sequentially. - Notice difference between sequential and random read syntax. Sequential read cannot have INVALID KEY clause and must have NEXT RECORD clause (with sequential files NEXT RECORD is optional). Random read doesn't have NEXT RECORD clause and although it's optional you should always check for INVALID KEY. - START keyword is used for cursor positioning in indexed files. On z/OS version of COBOL it's not needed file operations. Using MOVE keyword to specify the key and then reading a record does the same thing as START statement. You can simply comment START sentence and you'll see that it doesn't make any difference.
Solution 4
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP704) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP704. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUSTKSDS-FILE ASSIGN TO CUSTKSDS ORGANIZATION IS INDEXED RECORD KEY IS CUSTKSDS-ID ACCESS MODE IS DYNAMIC. SELECT CUST-FILE ASSIGN TO CUSTRRDS ORGANIZATION IS RELATIVE RELATIVE KEY IS CUST-RRN ACCESS MODE IS DYNAMIC. DATA DIVISION. FILE SECTION. FD CUSTKSDS-FILE. 01 CUSTKSDS-RECORD. 05 CUSTKSDS-ID PIC 9(8). 05 CUSTKSDS-FNAME PIC X(20). 05 CUSTKSDS-LNAME PIC X(20). 05 CUSTKSDS-EMAIL PIC X(30). 05 CUSTKSDS-BIRTH-DATE PIC X(10). 05 CUSTKSDS-REG-DATE PIC X(10). 05 CUSTKSDS-ACC-STATUS PIC X. 05 CUSTKSDS-DISCOUNT PIC 9(2). FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-FNAME PIC X(20). 05 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. 77 CUSTKSDS-EOF PIC 9 VALUE 0. 77 CUST-EOF PIC 9 VALUE 0. 77 CUST-RRN PIC 9(8) COMP VALUE 0. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM COPY-TO-RRDS. PERFORM REOPEN-RRDS. PERFORM POPULATE-THE-FILE. PERFORM SEQUENTIAL-READ. PERFORM RANDOM-READ. PERFORM SKIP-SEQUENTIAL-READ. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CUSTKSDS-FILE. OPEN OUTPUT CUST-FILE. REOPEN-RRDS. CLOSE CUST-FILE. OPEN I-O CUST-FILE. CLOSE-FILES. CLOSE CUSTKSDS-FILE. CLOSE CUST-FILE. COPY-TO-RRDS. READ CUSTKSDS-FILE NEXT RECORD AT END MOVE 1 TO CUSTKSDS-EOF. PERFORM UNTIL CUSTKSDS-EOF = 1 MOVE CUSTKSDS-RECORD TO CUST-RECORD COMPUTE CUST-RRN = CUST-RRN + 1 WRITE CUST-RECORD READ CUSTKSDS-FILE NEXT RECORD AT END MOVE 1 TO CUSTKSDS-EOF END-READ END-PERFORM. POPULATE-THE-FILE. MOVE SPACES TO CUST-RECORD ACCEPT CUST-ID. PERFORM UNTIL CUST-ID = SPACES ACCEPT CUST-FNAME ACCEPT CUST-LNAME ACCEPT CUST-EMAIL ACCEPT CUST-BIRTH-DATE ACCEPT CUST-REG-DATE ACCEPT CUST-ACC-STATUS ACCEPT CUST-DISCOUNT COMPUTE CUST-RRN = CUST-RRN + 1 WRITE CUST-RECORD INVALID KEY PERFORM INV-KEY-MSG END-WRITE MOVE SPACES TO CUST-RECORD ACCEPT CUST-ID END-PERFORM. SEQUENTIAL-READ. DISPLAY "SEQUENTIAL READ:". READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. RANDOM-READ. DISPLAY "RANDOM READ:" MOVE 7 TO CUST-RRN. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. DISPLAY CUST-RECORD. MOVE 2 TO CUST-RRN. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. DISPLAY CUST-RECORD. SKIP-SEQUENTIAL-READ. DISPLAY "SKIP SEQUENTIAL READ:" MOVE 0 TO CUST-EOF. MOVE 4 TO CUST-RRN. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD IF CUST-ID = 1000 MOVE 1 TO CUST-EOF END-IF READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. INV-KEY-MSG. DISPLAY CUST-ID " IS AN INVALID KEY. PROGRAM ENDS.". STOP RUN. //GO.CUSTKSDS DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS //GO.CUSTRRDS DD DISP=SHR,DSN=JSADEK.CUSTOMER.RRDS //********************************************************************* //* SPECIFY FOLLOWING FIELDS, ONE IN EACH LINE: //* - CUSTOMER NUMBER - 8 BYTES (NUMERIC) //* - FIRST NAME - 20 BYTES //* - LAST NAME - 20 BYTES //* - E-MAIL ADDRESS - 30 BYTES //* - BIRTH DATE - 10 BYTES //* - REGISTRATION DATE - 10 BYTES //* - ACCOUNT STATUS - 1 BYTE (N(NORMAL), D(DISCOUNT ELIGIBLE), //* S(SUSPENDED), I(INACTIVE, NOT USED FOR 3 YEARS)) //* - DISCOUNT - 2 BYTES (NUMERIC, CUSTOMER DISCOUNT IN %) //********************************************************************* //GO.SYSIN DD * 00001000 Diana Hamington Diana.ham@leco.com 1911-02-12 2018-01-01 D 10 00000500 Tom Mammoth Tommy3928@gmail.com 1990-01-16 2018-02-05 N 00
Comments: - RRDS cannot have an index and working with them is more similar to sequential than indexed files. - Records in RRDS are not referenced by a key like in KSDS but by RRN (Relative Record Number) which is simply a number of "slot" in which particular record is stored. RRN is not part of the record, it is just a pointer and therefore must be defined outside of FD record definition. - We've defined RRDS with record length = 101. By reading the record with RRN = 4, access method (VSAM) calculates physical address of this record by multiplying 101 * 4, now it knows that referenced record starts on byte 404 of the RRDS file and it has 101 bytes. - In SKIP-SEQUENTIAL-READ paragraph condition was changed to WITH TEST AFTER. Now records are not in ordered sequence so using '>' or '<' operators is a bad idea. Instead, a IF statement was added to end the loop after record with CUST-ID = 1000 is encountered.
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP705. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUSTKSDS-FILE ASSIGN TO CUSTKSDS ORGANIZATION IS INDEXED RECORD KEY IS CUSTKSDS-ID ACCESS MODE IS DYNAMIC FILE STATUS IS CUSTKSDS-STATUS CUSTKSDS-VSAMSTAT. SELECT CUST-FILE ASSIGN TO CUSTRRDS ORGANIZATION IS RELATIVE RELATIVE KEY IS CUST-RRN ACCESS MODE IS DYNAMIC FILE STATUS IS CUST-STATUS CUST-VSAMSTAT. DATA DIVISION. FILE SECTION. FD CUSTKSDS-FILE. 01 CUSTKSDS-RECORD. 05 CUSTKSDS-ID PIC 9(8). 05 CUSTKSDS-FNAME PIC X(20). 05 CUSTKSDS-LNAME PIC X(20). 05 CUSTKSDS-EMAIL PIC X(30). 05 CUSTKSDS-BIRTH-DATE PIC X(10). 05 CUSTKSDS-REG-DATE PIC X(10). 05 CUSTKSDS-ACC-STATUS PIC X. 05 CUSTKSDS-DISCOUNT PIC 9(2). FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-FNAME PIC X(20). 05 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. 77 CUSTKSDS-EOF PIC 9 VALUE 0. 77 CUST-EOF PIC 9 VALUE 0. 77 CUST-RRN PIC 9(8) COMP VALUE 0. 01 CUSTKSDS-STATUS PIC X(2). 01 CUSTKSDS-VSAMSTAT. 05 CUSTKSDS-VSAMRC PIC 9(2) COMP. 05 CUSTKSDS-VSAMFN PIC 9(2) COMP. 05 CUSTKSDS-VSAMFB PIC 9(2) COMP. 01 CUST-STATUS PIC X(2). 01 CUST-VSAMSTAT. 05 CUST-VSAMRC PIC 9(2) COMP. 05 CUST-VSAMFN PIC 9(2) COMP. 05 CUST-VSAMFB PIC 9(2) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM COPY-TO-RRDS. PERFORM REOPEN-RRDS. PERFORM POPULATE-THE-FILE. PERFORM SEQUENTIAL-READ. PERFORM RANDOM-READ. PERFORM SKIP-SEQUENTIAL-READ. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CUSTKSDS-FILE. PERFORM CUSTKSDS-FILE-CHECK. OPEN OUTPUT CUST-FILE. PERFORM CUST-FILE-CHECK. REOPEN-RRDS. CLOSE CUST-FILE. PERFORM CUST-FILE-CHECK. OPEN I-O CUST-FILE. PERFORM CUST-FILE-CHECK. CLOSE-FILES. CLOSE CUSTKSDS-FILE. PERFORM CUSTKSDS-FILE-CHECK. CLOSE CUST-FILE. PERFORM CUST-FILE-CHECK. COPY-TO-RRDS. READ CUSTKSDS-FILE NEXT RECORD AT END MOVE 1 TO CUSTKSDS-EOF. PERFORM CUSTKSDS-FILE-CHECK. PERFORM UNTIL CUSTKSDS-EOF = 1 MOVE CUSTKSDS-RECORD TO CUST-RECORD COMPUTE CUST-RRN = CUST-RRN + 1 WRITE CUST-RECORD PERFORM CUST-FILE-CHECK READ CUSTKSDS-FILE NEXT RECORD AT END MOVE 1 TO CUSTKSDS-EOF END-READ PERFORM CUSTKSDS-FILE-CHECK END-PERFORM. POPULATE-THE-FILE. MOVE SPACES TO CUST-RECORD ACCEPT CUST-ID. PERFORM UNTIL CUST-ID = SPACES ACCEPT CUST-FNAME ACCEPT CUST-LNAME ACCEPT CUST-EMAIL ACCEPT CUST-BIRTH-DATE ACCEPT CUST-REG-DATE ACCEPT CUST-ACC-STATUS ACCEPT CUST-DISCOUNT COMPUTE CUST-RRN = CUST-RRN + 1 WRITE CUST-RECORD INVALID KEY PERFORM INV-KEY-MSG END-WRITE PERFORM CUST-FILE-CHECK MOVE SPACES TO CUST-RECORD ACCEPT CUST-ID END-PERFORM. SEQUENTIAL-READ. DISPLAY "SEQUENTIAL READ:". READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF. PERFORM CUST-FILE-CHECK. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ PERFORM CUST-FILE-CHECK END-PERFORM. RANDOM-READ. DISPLAY "RANDOM READ:" MOVE 7 TO CUST-RRN. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM CUST-FILE-CHECK. DISPLAY CUST-RECORD. MOVE 2 TO CUST-RRN. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM CUST-FILE-CHECK. DISPLAY CUST-RECORD. SKIP-SEQUENTIAL-READ. DISPLAY "SKIP SEQUENTIAL READ:" MOVE 0 TO CUST-EOF. MOVE 4 TO CUST-RRN. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM CUST-FILE-CHECK. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD IF CUST-ID = 1000 MOVE 1 TO CUST-EOF END-IF READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ PERFORM CUST-FILE-CHECK END-PERFORM. INV-KEY-MSG. DISPLAY CUST-ID " IS AN INVALID KEY. PROGRAM ENDS.". PERFORM CUST-FILE-CHECK. STOP RUN. CUSTKSDS-FILE-CHECK. IF CUSTKSDS-STATUS NOT = "00" AND "10" DISPLAY "File error occured. Program ends." DISPLAY "File Status Key : " CUSTKSDS-STATUS DISPLAY "VSAM return code : " CUSTKSDS-VSAMRC DISPLAY "VSAM function code: " CUSTKSDS-VSAMFN DISPLAY "VSAM feedback code: " CUSTKSDS-VSAMFB MOVE CUSTKSDS-STATUS TO RETURN-CODE STOP RUN END-IF. CUST-FILE-CHECK. IF CUST-STATUS NOT = "00" AND "10" DISPLAY "File error occured. Program ends." DISPLAY "File Status Key : " CUST-STATUS DISPLAY "VSAM return code : " CUST-VSAMRC DISPLAY "VSAM function code: " CUST-VSAMFN DISPLAY "VSAM feedback code: " CUST-VSAMFB MOVE CUST-STATUS TO RETURN-CODE STOP RUN END-IF.
Comments: - Checking file status code after each READ, WRITE or OPEN, CLOSE operation is overkill but from now on you should always define FILE STATUS variable and use it anywhere you suspect problems. - There are two file operation RC which you should consider normal "00" and "10". 10 means end of file or that data set marked as optional was not found, so it's a normal processing condition. If you use OPTIONAL keyword for your file definition you should use file status code to test if it exists or not. - VSAM status codes must be always defined as shown above, in form of a structure with three binary (COMP) variables. - In added "check" paragraphs you can see an alternative IF condition syntax: "IF CUST-STATUS NOT = "00" AND "10"" is equal to "IF CUST-STATUS NOT = "00" AND CUST-STATUS NOT = "10"". - Special variable RETURN-CODE was used here for the first time. It's used for setting RC for the abended program. Without it, our program would end with RC = 0 which is a bad idea since it implies that files were correctly processed. Such RC can be now used by other jobs/programs which in turn may lead to all kinds of errors. Important: Using FILE STATUS clause changes program behavior in case of file error. Without that clause, a program will end with RC = file status code. With that clause, file status code is moved to the variable but it's no longer considered an error and program RC will be equal to 0. That's why you should remember to always test for file errors and if there is such need copy file status code to RETURN-CODE special variable. Errors: - File does not exist: JCL error. - Contention: "Wait for data set" message. - Retrieving record with non existing RRN. File Status Key : 23 VSAM return code : 08 VSAM function code: 00 VSAM feedback code: 16 - Inserting record with existing RRN: File Status Key : 22 VSAM return code : 08 VSAM function code: 00 VSAM feedback code: 08 - Opening KSDS for OUTPUT instead of INPUT: File Status Key : 37 VSAM return code : 08 VSAM function code: 00 VSAM feedback code: 32 - Opening RRDS for INPUT istead of OUTPUT: File Status Key : 48 VSAM return code : 00 VSAM function code: 00 VSAM feedback code: 00 - Record lenght of KSDS is larger than this of RRDS: File Status Key : 39 VSAM return code : 00 VSAM function code: 00 VSAM feedback code: 00 - Saving empty record to RRDS: No error. - Saving record with RRN = 200000: No error but RRDS data set size jumped from 1 to 27 cylinders. This is a good example of risks that mapping record key (for example CUST-ID) to RRN. If the key is a numeric which increments by 1 it may be considered but in other cases it may lead to a lot of wasted space between records. - Saving record with RRN = 20000000: "IEC070I 209-220" message. No more space on a volume.
Solution 6
Copying RRDS to ESDS:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP706) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP706. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUSTRRDS-FILE ASSIGN TO CUSTRRDS ORGANIZATION IS RELATIVE RELATIVE KEY IS CUSTRRDS-RRN ACCESS MODE IS DYNAMIC FILE STATUS IS CUSTRRDS-STATUS. SELECT CUST-FILE ASSIGN TO AS-CUSTESDS ORGANIZATION IS SEQUENTIAL ACCESS MODE IS SEQUENTIAL FILE STATUS IS CUST-STATUS. DATA DIVISION. FILE SECTION. FD CUSTRRDS-FILE. 01 CUSTRRDS-RECORD. 05 CUSTRRDS-ID PIC 9(8). 05 CUSTRRDS-FNAME PIC X(20). 05 CUSTRRDS-LNAME PIC X(20). 05 CUSTRRDS-EMAIL PIC X(30). 05 CUSTRRDS-BIRTH-DATE PIC X(10). 05 CUSTRRDS-REG-DATE PIC X(10). 05 CUSTRRDS-ACC-STATUS PIC X. 05 CUSTRRDS-DISCOUNT PIC 9(2). FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-FNAME PIC X(20). 05 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. 77 CUSTRRDS-EOF PIC 9 VALUE 0. 77 CUST-EOF PIC 9 VALUE 0. 77 CUSTRRDS-RRN PIC 9(8) COMP. 01 CUSTRRDS-STATUS PIC X(2). 01 CUST-STATUS PIC X(2). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM COPY-TO-ESDS. PERFORM REOPEN-ESDS. PERFORM SEQUENTIAL-READ. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CUSTRRDS-FILE. PERFORM CUSTRRDS-CHECK. OPEN OUTPUT CUST-FILE. PERFORM CUST-CHECK. REOPEN-ESDS. CLOSE CUST-FILE. OPEN INPUT CUST-FILE. PERFORM CUST-CHECK. CLOSE-FILES. CLOSE CUSTRRDS-FILE. CLOSE CUST-FILE. COPY-TO-ESDS. READ CUSTRRDS-FILE NEXT RECORD AT END MOVE 1 TO CUSTRRDS-EOF. PERFORM CUSTRRDS-CHECK. PERFORM UNTIL CUSTRRDS-EOF = 1 MOVE CUSTRRDS-RECORD TO CUST-RECORD WRITE CUST-RECORD PERFORM CUST-CHECK READ CUSTRRDS-FILE NEXT RECORD AT END MOVE 1 TO CUSTRRDS-EOF END-READ PERFORM CUSTRRDS-CHECK END-PERFORM. SEQUENTIAL-READ. DISPLAY "SEQUENTIAL READ:". READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. CUSTRRDS-CHECK. IF CUSTRRDS-STATUS NOT = "00" AND "10" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY : " CUSTRRDS-STATUS MOVE CUSTRRDS-STATUS TO RETURN-CODE STOP RUN END-IF. CUST-CHECK. IF CUST-STATUS NOT = "00" AND "10" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY : " CUST-STATUS MOVE CUST-STATUS TO RETURN-CODE STOP RUN END-IF. //GO.CUSTRRDS DD DISP=SHR,DSN=JSADEK.CUSTOMER.RRDS //GO.CUSTESDS DD DISP=SHR,DSN=JSADEK.CUSTOMER.ESDS
Not much new things in this program, you already know everything from previous tasks. The only significant difference is "AS-" prefix in ASSIGN clause, without it COBOL program will try to process the data set as a sequential file, "AS-" defines the file as ESDS. Previously ESDS was defined with REUSE option which enables us to erase it with each program rerun. This is a useful thing to do for testing but to define Index for ESDS it must be defined with NOREUSE attribute. Because of that, we need to: - Remove ESDS. - Create ESDS again with NOREUSE attribute. - Populate it with data by rerunning now tested program. - Create Alternate Index for it. - Create a Path that connects the Index with Base Cluster. - Build the Index. Creating Index for ESDS:
//IXALLOC EXEC PGM=IDCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE ALTERNATEINDEX( - NAME(JSADEK.CUSTOMER.ESDS.AIX) - RELATE(JSADEK.CUSTOMER.ESDS) - TRACKS(5 5) - FREESPACE(20 20) - UNIQUEKEY - KEYS(8 0) - ) //IXBUILD EXEC PGM=IDCAMS,COND=(0,NE) //SYSPRINT DD SYSOUT=* //SYSIN DD * BLDINDEX - IDS(JSADEK.CUSTOMER.ESDS) - ODS(JSADEK.CUSTOMER.ESDS.AIX) DEFINE PATH( - NAME(JSADEK.CUSTOMER.ESDS.PATH) - PATHENTRY(JSADEK.CUSTOMER.ESDS.AIX) - )
Accessing ESDS via Index:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP706) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP706. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO CUSTESDS ORGANIZATION IS INDEXED ACCESS MODE IS DYNAMIC RECORD KEY IS CUST-ID FILE STATUS IS CUST-STATUS. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-FNAME PIC X(20). 05 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. 01 CUST-EOF PIC 9. 01 CUST-STATUS PIC X(2). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM SEQUENTIAL-READ. PERFORM RANDOM-READ. PERFORM SKIP-SEQUENTIAL-READ. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT CUST-FILE. PERFORM CUST-CHECK. CLOSE-FILES. CLOSE CUST-FILE. PERFORM CUST-CHECK. SEQUENTIAL-READ. DISPLAY "SEQUENTIAL READ:". READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF. PERFORM CUST-CHECK. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. RANDOM-READ. DISPLAY "RANDOM READ:" MOVE 500 TO CUST-ID. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM CUST-CHECK. DISPLAY CUST-RECORD. MOVE 3 TO CUST-ID. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM CUST-CHECK. DISPLAY CUST-RECORD. SKIP-SEQUENTIAL-READ. DISPLAY "SKIP SEQUENTIAL READ:" MOVE 0 TO CUST-EOF. MOVE 3 TO CUST-ID. READ CUST-FILE INVALID KEY PERFORM INV-KEY-MSG. PERFORM CUST-CHECK. PERFORM UNTIL CUST-EOF = 1 OR CUST-ID > 500 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. INV-KEY-MSG. DISPLAY CUST-ID " IS AN INVALID KEY. PROGRAM ENDS.". PERFORM CUST-CHECK. STOP RUN. CUST-CHECK. IF CUST-STATUS NOT = "00" AND "10" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY : " CUST-STATUS MOVE CUST-STATUS TO RETURN-CODE STOP RUN END-IF. //GO.CUSTESDS DD DISP=SHR,DSN=JSADEK.CUSTOMER.ESDS.PATH
Output:
SEQUENTIAL READ: 00000001Mark Smith mark.smith@hell.com 1982-01-302018-02-18N00 00000002Hanna Panna your.bunny@fm.com 1999-01-302018-01-11D30 00000003Pennywise - letsfloat@fun.edu 1911-07-102017-12-15D95 00000004Dick Ditch ddman@gmail.com 1964-11-052018-02-01S00 00000005Ian Lobocetahi cob.ol.lol@yahoo.com 1982-01-302018-02-18I03 00000500Tom Mammoth Tommy3928@gmail.com 1990-01-162018-02-05N00 00001000Diana Hamington Diana.ham@leco.com 1911-02-122018-01-01D10 RANDOM READ: 00000500Tom Mammoth Tommy3928@gmail.com 1990-01-162018-02-05N00 00000003Pennywise - letsfloat@fun.edu 1911-07-102017-12-15D95 SKIP SEQUENTIAL READ: 00000003Pennywise - letsfloat@fun.edu 1911-07-102017-12-15D95 00000004Dick Ditch ddman@gmail.com 1964-11-052018-02-01S00 00000005Ian Lobocetahi cob.ol.lol@yahoo.com 1982-01-302018-02-18I03 00000500Tom Mammoth Tommy3928@gmail.com 1990-01-162018-02-05N00
Comments: - After defining an Alternate Index and a Path you can use ESDS in exactly the same way as KSDS, the only differece is that in DD statement you specify PATH component, not KSDS cluster name. - Also, "AS-" prefix is no longer used. - As you can notice from the output sequential read now displays records in the right order although in ESDS record 1000 is before the one with number 500. - In this example File Status is checked only during OPEN, CLOSE and Random READ operations. It's not included in loops since they're tested and issuing file check in each iteration is a waste of processor time. Now you know how to work with all types of VSAM, ESDS, Indexed ESDS, KSDS, and RRDS. There are two other VSAM data set types, VRRDS so RRDS with variable record lenght and LDS which is an unstructured file. In practice, you'll work almost entirely on standard sequential data sets and KSDS.
Solution 7
Creating Altenate Indexes and Paths:
//IXALLOC EXEC PGM=IDCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE ALTERNATEINDEX( - NAME(JSADEK.CUSTOMER.KSDS.MAIL.AIX) - RELATE(JSADEK.CUSTOMER.KSDS) - TRACKS(5 5) - FREESPACE(20 20) - UNIQUEKEY - KEYS(30 48) - ) DEFINE ALTERNATEINDEX( - NAME(JSADEK.CUSTOMER.KSDS.NAME.AIX) - RELATE(JSADEK.CUSTOMER.KSDS) - TRACKS(5 5) - FREESPACE(20 20) - NONUNIQUEKEY - KEYS(40 8) - ) //IXBUILD EXEC PGM=IDCAMS,COND=(0,NE) //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE PATH( - NAME(JSADEK.CUSTOMER.KSDS.MAIL.PATH) - PATHENTRY(JSADEK.CUSTOMER.KSDS.MAIL.AIX) - ) DEFINE PATH( - NAME(JSADEK.CUSTOMER.KSDS.NAME.PATH) - PATHENTRY(JSADEK.CUSTOMER.KSDS.NAME.AIX) - ) BLDINDEX - IDS(JSADEK.CUSTOMER.KSDS) - ODS(JSADEK.CUSTOMER.KSDS.MAIL.AIX) BLDINDEX - IDS(JSADEK.CUSTOMER.KSDS) - ODS(JSADEK.CUSTOMER.KSDS.NAME.AIX)
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP707) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP707. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO CUST ORGANIZATION IS INDEXED ACCESS MODE IS DYNAMIC RECORD KEY IS CUST-ID ALTERNATE KEY IS CUST-EMAIL ALTERNATE KEY IS CUST-NAME WITH DUPLICATES FILE STATUS IS CUST-STATUS CUST-VSAMSTAT. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-NAME. 10 CUST-FNAME PIC X(20). 10 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. 01 CUST-EOF PIC 9. 01 CUST-STATUS PIC X(2). 01 CUST-VSAMSTAT. 05 CUST-VSAMRC PIC 9(2) COMP. 05 CUST-VSAMFN PIC 9(2) COMP. 05 CUST-VSAMFB PIC 9(2) COMP. 77 OPT PIC X VALUE "X". 77 USER-INPUT PIC X(30) VALUE SPACES. 77 INPUT-OK PIC X VALUE "N". 77 LAST-RECORD PIC X VALUE "N". 77 K1 PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM DISPLAY-MAIN-MENU UNTIL OPT = "0". PERFORM CLOSE-FILES. STOP RUN. DISPLAY-MAIN-MENU. DISPLAY " ". DISPLAY "Which key would you like to use:". DISPLAY "- 1 - Customer ID". DISPLAY "- 2 - Customer E-mail". DISPLAY "- 3 - Customer full name". DISPLAY "- 0 - End the program". ACCEPT OPT. EVALUATE OPT WHEN "1" PERFORM DISPLAY-ID-PROMPT WHEN "2" PERFORM DISPLAY-EMAIL-PROMPT WHEN "3" PERFORM DISPLAY-NAME-PROMPT WHEN "0" CONTINUE WHEN OTHER DISPLAY OPT "is an invalid option." END-EVALUATE. DISPLAY-ID-PROMPT. DISPLAY "Specify customer ID (8 digits):". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking ID: " USER-INPUT. PERFORM VERIFY-CUST-ID. IF INPUT-OK = "Y" COMPUTE CUST-ID = FUNCTION NUMVAL(USER-INPUT) READ CUST-FILE INVALID KEY DISPLAY CUST-ID " not found in the file." NOT INVALID KEY DISPLAY CUST-RECORD END-READ END-IF. IF INPUT-OK = "N" DISPLAY USER-INPUT " is not in correct format." END-IF. DISPLAY-EMAIL-PROMPT. DISPLAY "Specify customer E-mail address:". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking E-mail: " USER-INPUT. PERFORM VERIFY-CUST-EMAIL. IF INPUT-OK = "Y" MOVE USER-INPUT TO CUST-EMAIL READ CUST-FILE KEY IS CUST-EMAIL INVALID KEY DISPLAY CUST-EMAIL " not found in the file." NOT INVALID KEY DISPLAY CUST-RECORD END-READ END-IF. IF INPUT-OK = "N" DISPLAY USER-INPUT " is not in correct format." END-IF. DISPLAY-NAME-PROMPT. DISPLAY "Specify customer name:". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking name: " USER-INPUT. PERFORM VERIFY-CUST-NAME. IF INPUT-OK = "Y" READ CUST-FILE KEY IS CUST-NAME INVALID KEY DISPLAY CUST-NAME " not found in the file." NOT INVALID KEY MOVE CUST-NAME TO USER-INPUT END-READ MOVE "N" TO LAST-RECORD PERFORM UNTIL LAST-RECORD = "Y" DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE "Y" TO LAST-RECORD END-READ IF CUST-NAME NOT = USER-INPUT MOVE "Y" TO LAST-RECORD END-IF END-PERFORM END-IF. IF INPUT-OK = "N" DISPLAY USER-INPUT " is not in correct format." END-IF. VERIFY-CUST-ID. MOVE "Y" TO INPUT-OK. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 8 IF USER-INPUT(K1:1) < "0" OR > "9" MOVE "N" TO INPUT-OK END-IF END-PERFORM. IF USER-INPUT(9:22) NOT = SPACES MOVE "N" TO INPUT-OK END-IF. VERIFY-CUST-EMAIL. MOVE "Y" TO INPUT-OK. MOVE 0 TO K1. INSPECT USER-INPUT TALLYING K1 FOR ALL "@". IF K1 NOT = 1 MOVE "N" TO INPUT-OK END-IF. VERIFY-CUST-NAME. MOVE "Y" TO INPUT-OK. UNSTRING USER-INPUT DELIMITED BY ALL SPACES INTO CUST-FNAME CUST-LNAME ON OVERFLOW MOVE "N" TO INPUT-OK. MOVE 0 TO K1. INSPECT CUST-FNAME TALLYING K1 FOR LEADING SPACES. IF K1 NOT = 0 THEN MOVE "N" TO INPUT-OK. MOVE 0 TO K1. INSPECT CUST-LNAME TALLYING K1 FOR LEADING SPACES. IF K1 NOT = 0 THEN MOVE "N" TO INPUT-OK. OPEN-FILES. OPEN INPUT CUST-FILE. PERFORM CUST-CHECK. CLOSE-FILES. CLOSE CUST-FILE. PERFORM CUST-CHECK. CUST-CHECK. IF CUST-STATUS NOT = "00" AND "10" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY : " CUST-STATUS DISPLAY "VSAM return code : " CUST-VSAMRC DISPLAY "VSAM function code: " CUST-VSAMFN DISPLAY "VSAM feedback code: " CUST-VSAMFB MOVE CUST-STATUS TO RETURN-CODE STOP RUN END-IF. //GO.CUST DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS //GO.CUST1 DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS.MAIL.PATH //GO.CUST2 DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS.NAME.PATH //GO.SYSIN DD * ...
Output:
Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer ID (8 digits): Checking ID: 00000002 00000002Hanna Panna your.bunny@fm.com 1999-01-302018-01-11D30 Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer ID (8 digits): Checking ID: 00000002D 00000002D is not in correct format. Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer ID (8 digits): Checking ID: 0000002 0000002 is not in correct format. Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer ID (8 digits): Checking ID: 00000001 00000001Mark Smith mark.smith@hell.com 1982-01-302018-02-18N00 Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer ID (8 digits): Checking ID: 00A00003 00A00003 is not in correct format. Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer E-mail address: Checking E-mail: letsfloat@fun.edu 00000003Pennywise - letsfloat@fun.edu 1911-07-102017-12-15D95 Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer E-mail address: Checking E-mail: @@ un.edu @@ un.edu is not in correct format. Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer E-mail address: Checking E-mail: letsfloat%fun.edu letsfloat%fun.edu is not in correct format. Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer name: Checking name: mRDISAIS mRDISAIS is not in correct format. Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer name: Checking name: S EIW }} S EIW }} is not in correct format. Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer name: Checking name: Pennywise - 00000003Pennywise - letsfloat@fun.edu 1911-07-102017-12-15D95 Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer name: Checking name: Mark Smith 00000001Mark Smith mark.smith@hell.com 1982-01-302018-02-18N00 00000007Mark Smith mark.smith321@gmail.com 1982-01-302018-02-18N00 00000017Mark Smith msmiththethird@hell.com 1982-01-302018-02-18N00 Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program Specify customer ID (8 digits): Checking ID: 00000005 00000005Ian Lobocetahi cob.ol.lol@yahoo.com 1982-01-302018-02-18I03 Which key would you like to use: - 1 - Customer ID - 2 - Customer E-mail - 3 - Customer full name - 0 - End the program
Comments: - To be able to use Alternate Indexes in COBOL you need basically three things: DDs that define them to COBOL program, ALTERNATE KEY clause in SELECT statement and KEY IS clause in READ statement. - Probably the hardest thing to figure out is how to define DDs that point to alternate indexes. ASSIGN clause should point to DD of the main Cluster. DD names for alternate indexes must have the same name followed by a sequence number. If Cluster DD name has 8 letter, the last one is replaced with a number. Example:
ASSIGN TO CUSTMERS ... IEC130I CUSTMERS DD STATEMENT MISSING IEC130I CUSTMER1 DD STATEMENT MISSING IEC130I CUSTMER2 DD STATEMENT MISSING
- One of the Alternate Indexes is non-unique which means there may be many records with people having the same name. - In COBOL, CONTINUE keyword is a NOP (no operation) you may use it whenever COBOL syntax requires a sentence but you don't want to do anything. - Whenever you code a production program, no matter if it accepts user input (which is extremely rare) or read the data from database/file you should always include some kind of data verification. You'll rarely be able to detect/fix all input errors but the more you'll do the better. - Notice how name processing is realized. The user is asked to enter the full name. Then, it is divided into two parts by the first encounter space. This solution will work only for two-part names such as "Mark Smith" or "Jenny Parker-Lee" and won't work for strings like "Sarah Michele Hammington". If this solution is correct depends on the data stored in the file, a solution that allows more flexibility would be to simply ask the user for names and then surnames, this would allow more flexibility in names syntax. - It's worth noticing how UNSTRING function is used. It provides an easy way of dividing one string into many variables.
Solution 8
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP708) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP708. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO CUST ORGANIZATION IS INDEXED ACCESS MODE IS DYNAMIC RECORD KEY IS CUST-ID ALTERNATE KEY IS CUST-EMAIL ALTERNATE KEY IS CUST-NAME WITH DUPLICATES FILE STATUS IS CUST-STATUS CUST-VSAMSTAT. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-NAME. 10 CUST-FNAME PIC X(20). 10 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). WORKING-STORAGE SECTION. 77 CUST-TEMP PIC X(101). 01 CUST-EOF PIC 9. 01 CUST-STATUS PIC X(2). 01 CUST-VSAMSTAT. 05 CUST-VSAMRC PIC 9(2) COMP. 05 CUST-VSAMFN PIC 9(2) COMP. 05 CUST-VSAMFB PIC 9(2) COMP. 77 OPT PIC X VALUE "X". 77 USER-INPUT PIC X(30) VALUE SPACES. 77 INPUT-OK PIC X VALUE "N". 77 LAST-RECORD PIC X VALUE "N". 77 WRITE-MODE PIC X(3). 77 K1 PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM DISPLAY-MAIN-MENU UNTIL OPT = "0". PERFORM CLOSE-FILES. STOP RUN. DISPLAY-MAIN-MENU. DISPLAY " ". DISPLAY "Which key would you like to use:". DISPLAY "- 1 - Display record by ID". DISPLAY "- 2 - Display record by E-mail". DISPLAY "- 3 - Display record by name". DISPLAY "- 4 - Display all records". DISPLAY "- 5 - Add customer". DISPLAY "- 6 - Update customer". DISPLAY "- 7 - Delete customer". DISPLAY "- 0 - End the program". MOVE "X" TO OPT. ACCEPT OPT. EVALUATE OPT WHEN "1" PERFORM DISPLAY-ID-PROMPT WHEN "2" PERFORM DISPLAY-EMAIL-PROMPT WHEN "3" PERFORM DISPLAY-NAME-PROMPT WHEN "4" PERFORM DISPLAY-ALL-RECORDS WHEN "5" PERFORM ADD-MENU WHEN "6" PERFORM UPDATE-MENU WHEN "7" PERFORM DELETE-MENU WHEN "0" DISPLAY "Good Bye" WHEN OTHER DISPLAY OPT " is an invalid option." END-EVALUATE. ADD-MENU. MOVE "ADD" TO WRITE-MODE. MOVE SPACES TO CUST-RECORD. MOVE FUNCTION CURRENT-DATE TO USER-INPUT. STRING USER-INPUT(1:4) "-" USER-INPUT(5:2) "-" USER-INPUT(7:2) DELIMITED BY SIZE INTO CUST-REG-DATE. MOVE "N" TO CUST-ACC-STATUS. MOVE 0 TO CUST-DISCOUNT. PERFORM ADD-UPDATE-MENU. UPDATE-MENU. MOVE "N" TO INPUT-OK. MOVE SPACES TO USER-INPUT. MOVE SPACES TO CUST-RECORD. PERFORM UNTIL INPUT-OK = "Y" OR USER-INPUT = "0" DISPLAY "Specify customer ID (8 digits) or '0' to cancel" MOVE SPACES TO USER-INPUT ACCEPT USER-INPUT PERFORM VERIFY-CUST-ID IF INPUT-OK = "Y" COMPUTE CUST-ID = FUNCTION NUMVAL(USER-INPUT) READ CUST-FILE INVALID KEY MOVE "N" TO INPUT-OK IF INPUT-OK = "N" DISPLAY "No such customer in the file" END-IF ELSE DISPLAY "Invalid syntax : " USER-INPUT END-IF END-PERFORM. IF INPUT-OK = "Y" MOVE "UPD" TO WRITE-MODE PERFORM ADD-UPDATE-MENU END-IF. DISPLAY-ALL-RECORDS. MOVE 0 TO CUST-EOF. MOVE SPACES TO CUST-RECORD. START CUST-FILE KEY NOT < CUST-ID INVALID KEY MOVE 1 TO CUST-EOF. IF CUST-EOF = 0 READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. DELETE-MENU. MOVE SPACES TO USER-INPUT. DISPLAY "Specify user ID to delte:" ACCEPT USER-INPUT. PERFORM VERIFY-CUST-ID. IF INPUT-OK = "N" DISPLAY "Incorrect customer ID format" ELSE MOVE USER-INPUT(1:8) TO CUST-ID DELETE CUST-FILE INVALID KEY DISPLAY "No such user found" END-DELETE IF CUST-STATUS = "00" DISPLAY "Record deleted successfully" END-IF END-IF. ADD-UPDATE-MENU. DISPLAY " ". PERFORM UNTIL OPT = "9" OR "0" IF WRITE-MODE = "ADD" DISPLAY "Add menu" END-IF IF WRITE-MODE = "UPD" DISPLAY "Update menu" END-IF IF WRITE-MODE = "ADD" DISPLAY "- 1 - Customer ID: " CUST-ID END-IF IF WRITE-MODE = "UPD" DISPLAY "- X - Customer ID: " CUST-ID END-IF DISPLAY "- 2 - Customer name: " CUST-FNAME " " CUST-LNAME DISPLAY "- 3 - Customer E-mail: " CUST-EMAIL DISPLAY "- 4 - Customer birth date: " CUST-BIRTH-DATE DISPLAY "- X - Registration date: " CUST-REG-DATE DISPLAY "- 6 - Account status: " CUST-ACC-STATUS DISPLAY "- 7 - Discount: " CUST-DISCOUNT DISPLAY "- 9 - Save customer" DISPLAY "- 0 - Cancel operation" MOVE "X" TO OPT ACCEPT OPT EVALUATE OPT WHEN "1" PERFORM UPDATE-ID WHEN "2" PERFORM UPDATE-NAME WHEN "3" PERFORM UPDATE-EMAIL WHEN "4" PERFORM UPDATE-BIRTH-DATE WHEN "6" PERFORM UPDATE-ACC-STATUS WHEN "7" PERFORM UPDATE-DISCOUNT WHEN "9" PERFORM SAVE-CHANGES WHEN "0" DISPLAY "Operation cancelled" WHEN OTHER DISPLAY "Invalid option" END-EVALUATE END-PERFORM. MOVE "X" TO OPT. UPDATE-ID. IF WRITE-MODE = "ADD" MOVE SPACES TO USER-INPUT DISPLAY "Specify ID:" ACCEPT USER-INPUT PERFORM VERIFY-CUST-ID IF INPUT-OK = "Y" COMPUTE CUST-ID = FUNCTION NUMVAL(USER-INPUT) ELSE DISPLAY "Invalid ID syntax: " USER-INPUT END-IF ELSE DISPLAY "You cannot modify customer ID" END-IF. UPDATE-NAME. MOVE SPACES TO USER-INPUT. IF WRITE-MODE = "UPD" MOVE CUST-NAME TO CUST-TEMP. DISPLAY "Specify full name:". ACCEPT USER-INPUT. PERFORM VERIFY-CUST-NAME. IF INPUT-OK = "N" IF WRITE-MODE = "UPD" MOVE CUST-TEMP(1:40) TO CUST-NAME ELSE MOVE SPACES TO CUST-NAME END-IF DISPLAY "Given name had incorrect format" END-IF. UPDATE-EMAIL. MOVE SPACES TO USER-INPUT. DISPLAY "Specify e-mail address:". ACCEPT USER-INPUT. PERFORM VERIFY-CUST-EMAIL. IF INPUT-OK = "Y" MOVE USER-INPUT TO CUST-EMAIL ELSE DISPLAY "Given e-mail address had incorrect format" END-IF. UPDATE-BIRTH-DATE. MOVE SPACES TO USER-INPUT. MOVE "Y" TO INPUT-OK. DISPLAY "Specify birth date:" ACCEPT USER-INPUT. IF USER-INPUT(11:20) NOT = SPACES MOVE "N" TO INPUT-OK. IF USER-INPUT(5:1) NOT = "-" OR USER-INPUT(8:1) NOT = "-" MOVE "N" TO INPUT-OK. IF USER-INPUT(1:4) < "1900" OR USER-INPUT(1:4) > "2200" MOVE "N" TO INPUT-OK. IF USER-INPUT(6:2) < "01" OR USER-INPUT(6:2) > "12" MOVE "N" TO INPUT-OK. IF USER-INPUT(9:2) < "01" OR USER-INPUT(9:2) > "31" MOVE "N" TO INPUT-OK. IF INPUT-OK = "Y" MOVE USER-INPUT TO CUST-BIRTH-DATE. IF INPUT-OK = "N" DISPLAY "Given date is in incorrect format". UPDATE-ACC-STATUS. MOVE SPACES TO USER-INPUT. DISPLAY "Specify account status:" ACCEPT USER-INPUT. IF USER-INPUT = "N" OR "D" OR "S" OR "I" MOVE USER-INPUT TO CUST-ACC-STATUS ELSE DISPLAY "Invalid status given" END-IF. UPDATE-DISCOUNT. MOVE SPACES TO USER-INPUT. DISPLAY "Specify discount [%]:" ACCEPT USER-INPUT. COMPUTE K1 = FUNCTION NUMVAL(USER-INPUT). IF K1 < 0 OR K1 > 99 DISPLAY "Invalid discount value" ELSE MOVE K1 TO CUST-DISCOUNT END-IF. SAVE-CHANGES. IF WRITE-MODE = "ADD" AND CUST-ID = SPACES PERFORM GENERATE-ID. MOVE "Y" TO INPUT-OK. IF CUST-ID = SPACES MOVE "N" TO INPUT-OK. IF CUST-FNAME = SPACES MOVE "N" TO INPUT-OK. IF CUST-LNAME = SPACES MOVE "N" TO INPUT-OK. IF CUST-EMAIL = SPACES MOVE "N" TO INPUT-OK. IF CUST-BIRTH-DATE = SPACES MOVE "N" TO INPUT-OK. IF CUST-REG-DATE = SPACES MOVE "N" TO INPUT-OK. IF CUST-ACC-STATUS = SPACES MOVE "N" TO INPUT-OK. IF CUST-DISCOUNT = SPACES MOVE "N" TO INPUT-OK. IF INPUT-OK = "N" DISPLAY "Not all fields are specified" MOVE "X" TO OPT END-IF. IF INPUT-OK = "Y" IF WRITE-MODE = "ADD" WRITE CUST-RECORD END-IF IF WRITE-MODE = "UPD" REWRITE CUST-RECORD END-IF IF CUST-STATUS NOT = "00" IF CUST-STATUS = "02" DISPLAY "Duplicated customer name" ELSE DISPLAY "I-O error " CUST-STATUS " occured" MOVE "X" TO OPT END-IF END-IF IF CUST-STATUS = "00" OR "02" DISPLAY "Customer saved successfully." END-IF END-IF. GENERATE-ID. MOVE "N" TO INPUT-OK. PERFORM VARYING K1 FROM 1 BY 1 UNTIL INPUT-OK = "Y" MOVE K1 TO CUST-ID START CUST-FILE KEY = CUST-ID INVALID KEY MOVE "Y" TO INPUT-OK END-START END-PERFORM. DISPLAY-ID-PROMPT. DISPLAY "Specify customer ID (8 digits):". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking ID: " USER-INPUT. PERFORM VERIFY-CUST-ID. IF INPUT-OK = "Y" COMPUTE CUST-ID = FUNCTION NUMVAL(USER-INPUT) READ CUST-FILE INVALID KEY DISPLAY CUST-ID " not found in the file." NOT INVALID KEY DISPLAY CUST-RECORD END-READ END-IF. IF INPUT-OK = "N" DISPLAY USER-INPUT " is not in correct format." END-IF. DISPLAY-EMAIL-PROMPT. DISPLAY "Specify customer E-mail address:". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking E-mail: " USER-INPUT. PERFORM VERIFY-CUST-EMAIL. IF INPUT-OK = "Y" MOVE USER-INPUT TO CUST-EMAIL READ CUST-FILE KEY IS CUST-EMAIL INVALID KEY DISPLAY CUST-EMAIL " not found in the file." NOT INVALID KEY DISPLAY CUST-RECORD END-READ END-IF. IF INPUT-OK = "N" DISPLAY USER-INPUT " is not in correct format." END-IF. DISPLAY-NAME-PROMPT. DISPLAY "Specify customer name:". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking name: " USER-INPUT. PERFORM VERIFY-CUST-NAME. IF INPUT-OK = "Y" READ CUST-FILE KEY IS CUST-NAME INVALID KEY MOVE "N" TO INPUT-OK NOT INVALID KEY MOVE CUST-NAME TO USER-INPUT END-READ IF INPUT-OK = "N" DISPLAY "Customer not found in the file" ELSE MOVE "N" TO LAST-RECORD PERFORM UNTIL LAST-RECORD = "Y" DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE "Y" TO LAST-RECORD END-READ IF CUST-NAME NOT = USER-INPUT MOVE "Y" TO LAST-RECORD END-IF END-PERFORM END-IF ELSE DISPLAY USER-INPUT " is not in correct format." END-IF. VERIFY-CUST-ID. MOVE "Y" TO INPUT-OK. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 8 IF USER-INPUT(K1:1) < "0" OR > "9" MOVE "N" TO INPUT-OK END-IF END-PERFORM. IF USER-INPUT(9:22) NOT = SPACES MOVE "N" TO INPUT-OK END-IF. VERIFY-CUST-EMAIL. MOVE "Y" TO INPUT-OK. MOVE 0 TO K1. INSPECT USER-INPUT TALLYING K1 FOR ALL "@". IF K1 NOT = 1 MOVE "N" TO INPUT-OK END-IF. VERIFY-CUST-NAME. MOVE "Y" TO INPUT-OK. UNSTRING USER-INPUT DELIMITED BY ALL SPACES INTO CUST-FNAME CUST-LNAME ON OVERFLOW MOVE "N" TO INPUT-OK. MOVE 0 TO K1. INSPECT CUST-FNAME TALLYING K1 FOR LEADING SPACES. IF K1 NOT = 0 THEN MOVE "N" TO INPUT-OK. MOVE 0 TO K1. INSPECT CUST-LNAME TALLYING K1 FOR LEADING SPACES. IF K1 NOT = 0 THEN MOVE "N" TO INPUT-OK. OPEN-FILES. OPEN I-O CUST-FILE. PERFORM CUST-CHECK. CLOSE-FILES. CLOSE CUST-FILE. PERFORM CUST-CHECK. CUST-CHECK. IF CUST-STATUS NOT = "00" AND "10" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY : " CUST-STATUS DISPLAY "VSAM return code : " CUST-VSAMRC DISPLAY "VSAM function code: " CUST-VSAMFN DISPLAY "VSAM feedback code: " CUST-VSAMFB MOVE CUST-STATUS TO RETURN-CODE STOP RUN END-IF. //GO.CUST DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS //GO.CUST1 DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS.MAIL.PATH //GO.CUST2 DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS.NAME.PATH //GO.SYSIN DD * 4 0
CLIST is the best way to run such program interactively:
PROC 0 CONTROL ASIS ALLOC DA(*) FI(SYSIN) REUSE ALLOC DA('JSADEK.CUSTOMER.KSDS') FI(CUST) SHR REUSE ALLOC DA('JSADEK.CUSTOMER.KSDS.MAIL.PATH') FI(CUST1) SHR REUSE ALLOC DA('JSADEK.CUSTOMER.KSDS.NAME.PATH') FI(CUST2) SHR REUSE CALL 'JSADEK.MY.COBOL.LINKLIB(MP608)' FREE FI(SYSIN) FREE FI(CUST) FREE FI(CUST1) FREE FI(CUST2) EXIT
Comments: - This is the biggest program so far, although previously we could do without any comments in the program of that complexity comments are mandatory, actually any program written for production no matter how small should contain extensive comments. - All file operations are used in this program: READ, WRITE, START, REWRITE, DELETE. - GENERATE-ID function uses START command to go sequentially through all records until a free key is found. Then it assigns it as the ID of a newly added customer. You can see here the main difference between READ & START command. START command does not copy record from the file to FD variables. In other words, CUST-RECORD is not rewritten by START command. Using READ function would erase data of the new customer specified by the user. - It's worth taking a look on two different approaches of input verification:
COMPUTE K1 = FUNCTION NUMVAL(USER-INPUT). IF K1 < 0 OR K1 > 99 DISPLAY "Invalid discount value" ELSE ... IF USER-INPUT(9:2) < "01" OR USER-INPUT(9:2) > "31" MOVE "N" TO INPUT-OK.
In first case, user-input was converted to numeric and then tested if it contains correct values. This approach gives you more flexibility since you now can perform all numeric operations on the input. A disadvantage is that if user input is not numeric NUMVAL function will abend the program, but you can also test for that using IS NUMERIC statement. The second approach compares input as a string. This is often used solution, it's easier to code, it won't abend your program and it works just as well as testing numerics, at least in this case.
Solution 9
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP709) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP709. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO CUST ORGANIZATION IS INDEXED ACCESS MODE IS DYNAMIC RECORD KEY IS CUST-ID ALTERNATE KEY IS CUST-EMAIL ALTERNATE KEY IS CUST-NAME WITH DUPLICATES FILE STATUS IS CUST-STATUS CUST-VSAMSTAT. SELECT OPTIONAL LOG-FILE ASSIGN TO LOG ACCESS MODE IS SEQUENTIAL FILE STATUS IS LOG-STATUS. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(8). 05 CUST-NAME. 10 CUST-FNAME PIC X(20). 10 CUST-LNAME PIC X(20). 05 CUST-EMAIL PIC X(30). 05 CUST-BIRTH-DATE PIC X(10). 05 CUST-REG-DATE PIC X(10). 05 CUST-ACC-STATUS PIC X. 05 CUST-DISCOUNT PIC 9(2). FD LOG-FILE RECORDING MODE F. 01 LOG-RECORD. 05 LOG-TIMESTAMP PIC X(21). 05 LOG-FIL1 PIC X. 05 LOG-OPERATION PIC X(3). 05 LOG-FIL2 PIC X. 05 LOG-CUSTOMER PIC X(101). WORKING-STORAGE SECTION. 77 CUST-TEMP-RECORD PIC X(101). 77 CUST-TEMP-NAME PIC X(40). 01 CUST-EOF PIC 9. 01 CUST-STATUS PIC X(2). 01 CUST-VSAMSTAT. 05 CUST-VSAMRC PIC 9(2) COMP. 05 CUST-VSAMFN PIC 9(2) COMP. 05 CUST-VSAMFB PIC 9(2) COMP. 01 LOG-STATUS PIC X(2). 01 LOG-ON PIC 9. 01 LOG-EOF PIC 9. 77 OPT PIC X VALUE "X". 77 USER-INPUT PIC X(30) VALUE SPACES. 77 INPUT-OK PIC X VALUE "N". 77 LAST-RECORD PIC X VALUE "N". 77 WRITE-MODE PIC X(3). 77 K1 PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM DISPLAY-MAIN-MENU UNTIL OPT = "0". PERFORM CLOSE-FILES. STOP RUN. DISPLAY-MAIN-MENU. DISPLAY " ". DISPLAY "Which key would you like to use:". DISPLAY "- 1 - Display record by ID". DISPLAY "- 2 - Display record by E-mail". DISPLAY "- 3 - Display record by name". DISPLAY "- 4 - Display all records". DISPLAY "- 5 - Add customer". DISPLAY "- 6 - Update customer". DISPLAY "- 7 - Delete customer". DISPLAY "- 0 - End the program". MOVE "X" TO OPT. ACCEPT OPT. EVALUATE OPT WHEN "1" PERFORM DISPLAY-ID-PROMPT WHEN "2" PERFORM DISPLAY-EMAIL-PROMPT WHEN "3" PERFORM DISPLAY-NAME-PROMPT WHEN "4" PERFORM DISPLAY-ALL-RECORDS WHEN "5" PERFORM ADD-MENU WHEN "6" PERFORM UPDATE-MENU WHEN "7" PERFORM DELETE-MENU WHEN "0" DISPLAY "Good Bye" WHEN OTHER DISPLAY OPT " is an invalid option." END-EVALUATE. ADD-MENU. MOVE "ADD" TO WRITE-MODE. MOVE SPACES TO CUST-RECORD. MOVE FUNCTION CURRENT-DATE TO USER-INPUT. STRING USER-INPUT(1:4) "-" USER-INPUT(5:2) "-" USER-INPUT(7:2) DELIMITED BY SIZE INTO CUST-REG-DATE. MOVE "N" TO CUST-ACC-STATUS. MOVE 0 TO CUST-DISCOUNT. PERFORM ADD-UPDATE-MENU. UPDATE-MENU. MOVE "N" TO INPUT-OK. MOVE SPACES TO USER-INPUT. MOVE SPACES TO CUST-RECORD. PERFORM UNTIL INPUT-OK = "Y" OR USER-INPUT = "0" DISPLAY "Specify customer ID (8 digits) or '0' to cancel" MOVE SPACES TO USER-INPUT ACCEPT USER-INPUT PERFORM VERIFY-CUST-ID IF INPUT-OK = "Y" COMPUTE CUST-ID = FUNCTION NUMVAL(USER-INPUT) READ CUST-FILE INVALID KEY MOVE "N" TO INPUT-OK IF INPUT-OK = "N" DISPLAY "No such customer in the file" END-IF ELSE DISPLAY "Invalid syntax : " USER-INPUT END-IF END-PERFORM. IF INPUT-OK = "Y" MOVE "UPD" TO WRITE-MODE MOVE CUST-RECORD TO CUST-TEMP-RECORD PERFORM ADD-UPDATE-MENU END-IF. DISPLAY-ALL-RECORDS. MOVE 0 TO CUST-EOF. MOVE SPACES TO CUST-RECORD. START CUST-FILE KEY NOT < CUST-ID INVALID KEY MOVE 1 TO CUST-EOF. IF CUST-EOF = 0 READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. DELETE-MENU. MOVE SPACES TO USER-INPUT. DISPLAY "Specify user ID to delte:" ACCEPT USER-INPUT. PERFORM VERIFY-CUST-ID. IF INPUT-OK = "N" DISPLAY "Incorrect customer ID format" ELSE MOVE USER-INPUT(1:8) TO CUST-ID IF LOG-ON = 1 READ CUST-FILE INVALID KEY DISPLAY "No such user found" END-READ MOVE "DEL" TO LOG-OPERATION PERFORM SAVE-TO-LOG END-IF DELETE CUST-FILE INVALID KEY DISPLAY "No such user found" END-DELETE IF CUST-STATUS = "00" DISPLAY "Record deleted successfully" END-IF END-IF. ADD-UPDATE-MENU. DISPLAY " ". PERFORM UNTIL OPT = "9" OR "0" IF WRITE-MODE = "ADD" DISPLAY "Add menu" END-IF IF WRITE-MODE = "UPD" DISPLAY "Update menu" END-IF IF WRITE-MODE = "ADD" DISPLAY "- 1 - Customer ID: " CUST-ID END-IF IF WRITE-MODE = "UPD" DISPLAY "- X - Customer ID: " CUST-ID END-IF DISPLAY "- 2 - Customer name: " CUST-FNAME " " CUST-LNAME DISPLAY "- 3 - Customer E-mail: " CUST-EMAIL DISPLAY "- 4 - Customer birth date: " CUST-BIRTH-DATE DISPLAY "- X - Registration date: " CUST-REG-DATE DISPLAY "- 6 - Account status: " CUST-ACC-STATUS DISPLAY "- 7 - Discount: " CUST-DISCOUNT DISPLAY "- 9 - Save customer" DISPLAY "- 0 - Cancel operation" MOVE "X" TO OPT ACCEPT OPT EVALUATE OPT WHEN "1" PERFORM UPDATE-ID WHEN "2" PERFORM UPDATE-NAME WHEN "3" PERFORM UPDATE-EMAIL WHEN "4" PERFORM UPDATE-BIRTH-DATE WHEN "6" PERFORM UPDATE-ACC-STATUS WHEN "7" PERFORM UPDATE-DISCOUNT WHEN "9" PERFORM SAVE-CHANGES WHEN "0" DISPLAY "Operation cancelled" WHEN OTHER DISPLAY "Invalid option" END-EVALUATE END-PERFORM. MOVE "X" TO OPT. UPDATE-ID. IF WRITE-MODE = "ADD" MOVE SPACES TO USER-INPUT DISPLAY "Specify ID:" ACCEPT USER-INPUT PERFORM VERIFY-CUST-ID IF INPUT-OK = "Y" COMPUTE CUST-ID = FUNCTION NUMVAL(USER-INPUT) ELSE DISPLAY "Invalid ID syntax: " USER-INPUT END-IF ELSE DISPLAY "You cannot modify customer ID" END-IF. UPDATE-NAME. MOVE SPACES TO USER-INPUT. IF WRITE-MODE = "UPD" MOVE CUST-NAME TO CUST-TEMP-NAME. DISPLAY "Specify full name:". ACCEPT USER-INPUT. PERFORM VERIFY-CUST-NAME. IF INPUT-OK = "N" IF WRITE-MODE = "UPD" MOVE CUST-TEMP-NAME TO CUST-NAME ELSE MOVE SPACES TO CUST-NAME END-IF DISPLAY "Given name had incorrect format" END-IF. UPDATE-EMAIL. MOVE SPACES TO USER-INPUT. DISPLAY "Specify e-mail address:". ACCEPT USER-INPUT. PERFORM VERIFY-CUST-EMAIL. IF INPUT-OK = "Y" MOVE USER-INPUT TO CUST-EMAIL ELSE DISPLAY "Given e-mail address had incorrect format" END-IF. UPDATE-BIRTH-DATE. MOVE SPACES TO USER-INPUT. MOVE "Y" TO INPUT-OK. DISPLAY "Specify birth date:" ACCEPT USER-INPUT. IF USER-INPUT(11:20) NOT = SPACES MOVE "N" TO INPUT-OK. IF USER-INPUT(5:1) NOT = "-" OR USER-INPUT(8:1) NOT = "-" MOVE "N" TO INPUT-OK. IF USER-INPUT(1:4) < "1900" OR USER-INPUT(1:4) > "2200" MOVE "N" TO INPUT-OK. IF USER-INPUT(6:2) < "01" OR USER-INPUT(6:2) > "12" MOVE "N" TO INPUT-OK. IF USER-INPUT(9:2) < "01" OR USER-INPUT(9:2) > "31" MOVE "N" TO INPUT-OK. IF INPUT-OK = "Y" MOVE USER-INPUT TO CUST-BIRTH-DATE. IF INPUT-OK = "N" DISPLAY "Given date is in incorrect format". UPDATE-ACC-STATUS. MOVE SPACES TO USER-INPUT. DISPLAY "Specify account status:" ACCEPT USER-INPUT. IF USER-INPUT = "N" OR "D" OR "S" OR "I" MOVE USER-INPUT TO CUST-ACC-STATUS ELSE DISPLAY "Invalid status given" END-IF. UPDATE-DISCOUNT. MOVE SPACES TO USER-INPUT. DISPLAY "Specify discount [%]:" ACCEPT USER-INPUT. COMPUTE K1 = FUNCTION NUMVAL(USER-INPUT). IF K1 < 0 OR K1 > 99 DISPLAY "Invalid discount value" ELSE MOVE K1 TO CUST-DISCOUNT END-IF. SAVE-CHANGES. IF WRITE-MODE = "ADD" AND CUST-ID = SPACES PERFORM GENERATE-ID. MOVE "Y" TO INPUT-OK. IF CUST-ID = SPACES MOVE "N" TO INPUT-OK. IF CUST-FNAME = SPACES MOVE "N" TO INPUT-OK. IF CUST-LNAME = SPACES MOVE "N" TO INPUT-OK. IF CUST-EMAIL = SPACES MOVE "N" TO INPUT-OK. IF CUST-BIRTH-DATE = SPACES MOVE "N" TO INPUT-OK. IF CUST-REG-DATE = SPACES MOVE "N" TO INPUT-OK. IF CUST-ACC-STATUS = SPACES MOVE "N" TO INPUT-OK. IF CUST-DISCOUNT = SPACES MOVE "N" TO INPUT-OK. IF INPUT-OK = "N" DISPLAY "Not all fields are specified" MOVE "X" TO OPT END-IF. IF INPUT-OK = "Y" IF WRITE-MODE = "ADD" WRITE CUST-RECORD IF LOG-ON = 1 MOVE "ADD" TO LOG-OPERATION PERFORM SAVE-TO-LOG END-IF END-IF IF WRITE-MODE = "UPD" REWRITE CUST-RECORD IF LOG-ON = 1 MOVE CUST-TEMP-RECORD TO CUST-RECORD MOVE "UPD" TO LOG-OPERATION PERFORM SAVE-TO-LOG END-IF END-IF IF CUST-STATUS NOT = "00" IF CUST-STATUS = "02" DISPLAY "Duplicated customer name" ELSE DISPLAY "I-O error " CUST-STATUS " occured" MOVE "X" TO OPT END-IF END-IF IF CUST-STATUS = "00" OR "02" DISPLAY "Customer saved successfully." END-IF END-IF. GENERATE-ID. MOVE "N" TO INPUT-OK. PERFORM VARYING K1 FROM 1 BY 1 UNTIL INPUT-OK = "Y" MOVE K1 TO CUST-ID START CUST-FILE KEY = CUST-ID INVALID KEY MOVE "Y" TO INPUT-OK END-START END-PERFORM. DISPLAY-ID-PROMPT. DISPLAY "Specify customer ID (8 digits):". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking ID: " USER-INPUT. PERFORM VERIFY-CUST-ID. IF INPUT-OK = "Y" COMPUTE CUST-ID = FUNCTION NUMVAL(USER-INPUT) READ CUST-FILE INVALID KEY DISPLAY CUST-ID " not found in the file." NOT INVALID KEY DISPLAY CUST-RECORD END-READ END-IF. IF INPUT-OK = "N" DISPLAY USER-INPUT " is not in correct format." END-IF. DISPLAY-EMAIL-PROMPT. DISPLAY "Specify customer E-mail address:". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking E-mail: " USER-INPUT. PERFORM VERIFY-CUST-EMAIL. IF INPUT-OK = "Y" MOVE USER-INPUT TO CUST-EMAIL READ CUST-FILE KEY IS CUST-EMAIL INVALID KEY DISPLAY CUST-EMAIL " not found in the file." NOT INVALID KEY DISPLAY CUST-RECORD END-READ END-IF. IF INPUT-OK = "N" DISPLAY USER-INPUT " is not in correct format." END-IF. DISPLAY-NAME-PROMPT. DISPLAY "Specify customer name:". MOVE SPACES TO CUST-RECORD. MOVE SPACES TO USER-INPUT. ACCEPT USER-INPUT. DISPLAY "Checking name: " USER-INPUT. PERFORM VERIFY-CUST-NAME. IF INPUT-OK = "Y" READ CUST-FILE KEY IS CUST-NAME INVALID KEY MOVE "N" TO INPUT-OK NOT INVALID KEY MOVE CUST-NAME TO USER-INPUT END-READ IF INPUT-OK = "N" DISPLAY "Customer not found in the file" ELSE MOVE "N" TO LAST-RECORD PERFORM UNTIL LAST-RECORD = "Y" DISPLAY CUST-RECORD READ CUST-FILE NEXT RECORD AT END MOVE "Y" TO LAST-RECORD END-READ IF CUST-NAME NOT = USER-INPUT MOVE "Y" TO LAST-RECORD END-IF END-PERFORM END-IF ELSE DISPLAY USER-INPUT " is not in correct format." END-IF. VERIFY-CUST-ID. MOVE "Y" TO INPUT-OK. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 8 IF USER-INPUT(K1:1) < "0" OR > "9" MOVE "N" TO INPUT-OK END-IF END-PERFORM. IF USER-INPUT(9:22) NOT = SPACES MOVE "N" TO INPUT-OK END-IF. VERIFY-CUST-EMAIL. MOVE "Y" TO INPUT-OK. MOVE 0 TO K1. INSPECT USER-INPUT TALLYING K1 FOR ALL "@". IF K1 NOT = 1 MOVE "N" TO INPUT-OK END-IF. VERIFY-CUST-NAME. MOVE "Y" TO INPUT-OK. UNSTRING USER-INPUT DELIMITED BY ALL SPACES INTO CUST-FNAME CUST-LNAME ON OVERFLOW MOVE "N" TO INPUT-OK. MOVE 0 TO K1. INSPECT CUST-FNAME TALLYING K1 FOR LEADING SPACES. IF K1 NOT = 0 THEN MOVE "N" TO INPUT-OK. MOVE 0 TO K1. INSPECT CUST-LNAME TALLYING K1 FOR LEADING SPACES. IF K1 NOT = 0 THEN MOVE "N" TO INPUT-OK. OPEN-FILES. OPEN I-O CUST-FILE. PERFORM CUST-CHECK. OPEN EXTEND LOG-FILE. PERFORM LOG-CHECK. CLOSE-FILES. CLOSE CUST-FILE. PERFORM CUST-CHECK. IF LOG-ON = 1 CLOSE LOG-FILE PERFORM LOG-CHECK END-IF. CUST-CHECK. IF CUST-STATUS NOT = "00" AND "10" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY : " CUST-STATUS DISPLAY "VSAM return code : " CUST-VSAMRC DISPLAY "VSAM function code: " CUST-VSAMFN DISPLAY "VSAM feedback code: " CUST-VSAMFB MOVE CUST-STATUS TO RETURN-CODE STOP RUN END-IF. LOG-CHECK. IF LOG-STATUS = "00" MOVE 1 TO LOG-ON END-IF. IF LOG-STATUS = "10" DISPLAY "Log data set not allocated" DISPLAY "Operations won't be logged" MOVE 0 TO LOG-ON END-IF. IF LOG-STATUS NOT = "00" AND "10" DISPLAY "Log file error. Error code: " LOG-STATUS DISPLAY "Log won't be used" MOVE 0 TO LOG-ON END-IF. SAVE-TO-LOG. MOVE ";" TO LOG-FIL1 LOG-FIL2. MOVE FUNCTION CURRENT-DATE TO LOG-TIMESTAMP. MOVE CUST-RECORD TO LOG-CUSTOMER. WRITE LOG-RECORD. //GO.CUST DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS //GO.CUST1 DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS.MAIL.PATH //GO.CUST2 DD DISP=SHR,DSN=JSADEK.CUSTOMER.KSDS.NAME.PATH //GO.LOG DD DSN=JSADEK.CUSTOMER.KSDS.LOG,DISP=(MOD,CATLG), // SPACE=(CYL,(1,5)),RECFM=FB,BLKSIZE=12700,LRECL=127 //GO.SYSIN DD * 4 0
Log:
2018030510142572+0200;UPD;00000011Micheal Campaniele mc2928@outlook.com 1951-03-102018-01-31D00 2018030510191044+0200;ADD;00000012SOME CUSTOMER MAIL@ADR.COM 1990-02-022018-03-05N00 2018030510193491+0200;UPD;00000012SOME CUSTOMER MAIL@ADR.COM 1990-02-022018-03-05D12 2018030510194639+0200;DEL;00000007Mark Smith mark.smith321@gmail.com 1982-01-302018-02-18N00 2018030510202033+0200;UPD;00000002Hanna Panna your.bunny@fm.com 1999-02-112018-01-11D30 2018030510202782+0200;DEL;00000014SOME GUY TEST@TEST3 2014-02-022018-03-02N00
Comments: - Logging file operations, or any operations your program performs is often a good idea. Especially if it modifies production data. - SELECT OPTIONAL clause is used for the definition of the file which doesn't have to exist for correct program execution. - When creating logs like that you need to answer one important question. Should you log data before modification, after modification, or to save two records showing the data before and after the operation. The last option will clearly show all the differences but it requires twice as space as other solutions. The first option is a best one. With it, you see data before modification which you can compare it with current data, or, if it was later modified, with the next record in the log. You'll have to spend a little more time to make the comparison but you'll have all the needed data to so it. The middle option, logging data after modification is the worst one because there are cases in which you won't be able to compare data before and after the change. - In this program, the first option was chosen. Modified records are copied before data update. That's why CUST-RECORD is copied into CUST-TEMP-RECORD at the beginning of the update operation. During update operation, user modifies customer data, but we don't yet know it will be finally saved into KSDS, if it is, CUST-TEMP-RECORD has the original data which is written to the log.
CALL statement
Introduction
CALL statement is used for executing other programs from your code. There are two ways in which you can execute programs, dynamically and statically. You'll learn about the differences between those two methods soon enough. You can CALL all kinds of programs, you're own compiled execs, language environment services, even Utilities like DFSORT, although executing Utilities this way is very problematic and therefore rarely used. Called programs are often referred to as sub-programs. In the upcoming Tasks, all sub-programs are prefixed with 'U' letter. In real environment load modules follow more complex naming convention. For example, XXXYYYNN, where: - XXX – three-letter prefix that indicates an application to which load module belongs. The application is a set of programs that toghether realize some functionality, for example, maintanance of customer data. - YYY – module name. - NN – a number which indicates different versions of similar programs. For example, you may have 3 modules for user creation that are executed depending on type of user that is created.
Tasks
![]() 1. Create a program that displays a single line "Welcome from the called program":
- Compile it.
- Create a second program that executes the first one.
- Test how the called program behaves if you end it with "STOP RUN", "EXIT PROGRAM", and "GOBACK" statements.
- Test how the calling program behaves if you end it with "STOP RUN", "EXIT PROGRAM" and "GOBACK" statements.
- For now, use the static call in this and upcoming tasks.
1. Create a program that displays a single line "Welcome from the called program":
- Compile it.
- Create a second program that executes the first one.
- Test how the called program behaves if you end it with "STOP RUN", "EXIT PROGRAM", and "GOBACK" statements.
- Test how the calling program behaves if you end it with "STOP RUN", "EXIT PROGRAM" and "GOBACK" statements.
- For now, use the static call in this and upcoming tasks.
![]() 2. Create a program called ULENGTH which accept a string from a calling program and returns the actual string length.
2. Create a program called ULENGTH which accept a string from a calling program and returns the actual string length.
![]() 3. Modify the calling program from Task#2:
- This time execute ULENGTH via dynamic call.
- What's the difference between static and dynamic call?
3. Modify the calling program from Task#2:
- This time execute ULENGTH via dynamic call.
- What's the difference between static and dynamic call?
![]() 4. Write another sub-program UCUBE that calculates the cube of given number.
- Inside UCUBE program work directly on the passed variable.
- Compare passing value by REFERENCE, CONTENT, and VALUE.
4. Write another sub-program UCUBE that calculates the cube of given number.
- Inside UCUBE program work directly on the passed variable.
- Compare passing value by REFERENCE, CONTENT, and VALUE.
![]() 5. Write three programs:
- Write a sub-program UTRIM that removes leading and trailing spaces from the string.
- Modify ULENGTH sub-program so it uses it.
- Write a program that uses both ULENGTH and UTRIM functions.
- Pass the string to ULENGTH function via reference.
- ULENGTH function should accept additional argument WORKMODE with one of three values: TRIM, LGT, TRIMLGT.
- If TRIM mode is used - string should be passed to UTRIM via reference, it should be trimmed and length of trimmed string should be returned.
- If LGT mode is used - string shouldn't be trimmed and the length should be calculated from the beginning of the string, even if it starts with spaces.
- If TRIMLGT mode is used - string shouldn't be trimmed but the returned length should be the length of the data only, so leading spaces should be also ignored.
5. Write three programs:
- Write a sub-program UTRIM that removes leading and trailing spaces from the string.
- Modify ULENGTH sub-program so it uses it.
- Write a program that uses both ULENGTH and UTRIM functions.
- Pass the string to ULENGTH function via reference.
- ULENGTH function should accept additional argument WORKMODE with one of three values: TRIM, LGT, TRIMLGT.
- If TRIM mode is used - string should be passed to UTRIM via reference, it should be trimmed and length of trimmed string should be returned.
- If LGT mode is used - string shouldn't be trimmed and the length should be calculated from the beginning of the string, even if it starts with spaces.
- If TRIMLGT mode is used - string shouldn't be trimmed but the returned length should be the length of the data only, so leading spaces should be also ignored.
![]() 6. Modify programs from Task#5:
- Define string as X(1000) in UTRIM & ULENGHT but as X(50) in the main program. What happens?
- Change passing mode to CONTENT and repeat the experiment.
6. Modify programs from Task#5:
- Define string as X(1000) in UTRIM & ULENGHT but as X(50) in the main program. What happens?
- Change passing mode to CONTENT and repeat the experiment.
![]() 7. Write a program UADD:
- It should have only two variables NUM1 and NUM2, where NUM2 is passed by calling program.
- Declare NUM1 in WORKING-STORAGE section.
- NUM1 should be calculated as follows: NUM1 = NUM1 + NUM2.
- Execute UADD from the main program three times.
Test the program in following conditions:
- Without NUM1 initialization.
- With NUM1 initialization via PIC clause.
- With NUM1 initialization via MOVE statement.
- In INITIAL mode & without NUM1 initialization.
- In INITIAL mode & with NUM1 initialization via PIC clause.
- Without NUM1 initialization & using CANCEL statement after each execution.
- With NUM1 initialization via PIC clause & using CANCEL statement after each execution.
7. Write a program UADD:
- It should have only two variables NUM1 and NUM2, where NUM2 is passed by calling program.
- Declare NUM1 in WORKING-STORAGE section.
- NUM1 should be calculated as follows: NUM1 = NUM1 + NUM2.
- Execute UADD from the main program three times.
Test the program in following conditions:
- Without NUM1 initialization.
- With NUM1 initialization via PIC clause.
- With NUM1 initialization via MOVE statement.
- In INITIAL mode & without NUM1 initialization.
- In INITIAL mode & with NUM1 initialization via PIC clause.
- Without NUM1 initialization & using CANCEL statement after each execution.
- With NUM1 initialization via PIC clause & using CANCEL statement after each execution.
![]() 8. Modify program UADD from Task#7. This time define NUM1 variable in LOCAL-STORAGE section. Test the program in following cases:
- Without NUM1 initialization.
- With NUM1 initialization via PIC clause.
8. Modify program UADD from Task#7. This time define NUM1 variable in LOCAL-STORAGE section. Test the program in following cases:
- Without NUM1 initialization.
- With NUM1 initialization via PIC clause.
![]() 9. Write a program UDATE which returns given date in the format specified by given string. For example:
- Input: 20120316, Edit string: YY.MM.DD, MM/DD/YYYY, YYYY-MM-DD, "DD.MM YYYY year", "YYYY B.C." and so on.
- UDATE should accept parameter as a structure containing: year, month, day, edit string, formatted date, return code.
9. Write a program UDATE which returns given date in the format specified by given string. For example:
- Input: 20120316, Edit string: YY.MM.DD, MM/DD/YYYY, YYYY-MM-DD, "DD.MM YYYY year", "YYYY B.C." and so on.
- UDATE should accept parameter as a structure containing: year, month, day, edit string, formatted date, return code.
![]() 10. Write a program UGETSIZE:
- The program should process a sequential file with LRECL=80.
- Its purpose is to calculate statistics for a data set: record count, full data set size in bytes (record count * 80), minimum data set size (sum of record lengths without leading and trailing spaces), average record size (sum of data size of each record / record count).
- Execution flow should look as follows: The main program executes UGETSIZE which executes ULENGTH in "TRIMLGT" mode which executes UTRIM.
- The main program should display statistics calculated by UGETSIZE and then display the data set content.
- Perform the same activity in Notepad++ manually and compare the results.
10. Write a program UGETSIZE:
- The program should process a sequential file with LRECL=80.
- Its purpose is to calculate statistics for a data set: record count, full data set size in bytes (record count * 80), minimum data set size (sum of record lengths without leading and trailing spaces), average record size (sum of data size of each record / record count).
- Execution flow should look as follows: The main program executes UGETSIZE which executes ULENGTH in "TRIMLGT" mode which executes UTRIM.
- The main program should display statistics calculated by UGETSIZE and then display the data set content.
- Perform the same activity in Notepad++ manually and compare the results.
Hint 1
Make sure that member name that contains sub-program and the program name in PROGRAM-ID clause match. To link two programs together you can use IGYWCLG procedure we're using since the beginning. Linked modules should be referenced by LKED.SYSIN DD statement.
Hint 2
You'll have to use USING & RETURNING keywords in CALL statement (calling program) and in the PROCEDURE DIVISION clause (called program). Check "Enterprise COBOL for z/OS: Language Reference" for more information.
Hint 10
Data set allocated by the main program will be also available for all sub-programs, but you need to make sure that OPEN and CLOSE instructions are executed within the program that uses data set. So if your main program processes data set first, you'll need to CLOSE it before the CALL and then OPEN again in the sub-program.
Solution 1
COBOL code for called program:
//RUNCOBOL EXEC IGYWCL //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(TESTFUN) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. TESTFUN. PROCEDURE DIVISION. DISPLAY "Welcome from the called program!". EXIT PROGRAM.
COBOL code for calling program:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP801) //LKED.SYSIN DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(TESTFUN) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP801. PROCEDURE DIVISION. MAIN-LOGIC. DISPLAY "Before the call.". CALL "TESTFUN". DISPLAY "After the call.". STOP RUN.
Comments: - Called program name (load module name) and the name given in the PROGRAM-ID clause must be always the same. - During execution of the called program calling program is frozen. No instruction is done until control is given back from the called program. - To run the program statically you must first link it to the main module. To do so reference it via LKED.SYSIN DD statement. Ending the sub-program: - EXIT PROGRAM and GOBACK statements work the same way. They both end the called program and give control back to the calling program. - STOP RUN statement ends the entire program. If it's executed from the called program it will also end the calling program. Ending the main program: - STOP RUN and GOBACK behave the same way. They end the program. - EXIT PROGRAM tries to give control back to the calling program but since there is no such program, an abend occurs. Conclusion: - If you're sure that your program will be always the first one in the execution flow, you can stick with STOP RUN keyword. - If you're not sure about that, use GOBACK keyword. It works fine in both cases. - Avoid using EXIT PROGRAM statement.
Solution 2
Code of the called program:
//RUNCOBOL EXEC IGYWCL //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(ULENGTH) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. ULENGTH. DATA DIVISION. LINKAGE SECTION. 01 PARM PIC X(1000). 01 STR-L PIC S9(4) COMP. PROCEDURE DIVISION USING PARM RETURNING STR-L. MAIN-LOGIC. PERFORM PARM-CHECK. MOVE 0 TO STR-L. INSPECT FUNCTION REVERSE(PARM) TALLYING STR-L FOR LEADING SPACES. COMPUTE STR-L = LENGTH OF PARM - STR-L. GOBACK. PARM-CHECK. IF PARM = LOW-VALUES MOVE -1 TO STR-L GOBACK END-IF.
Code of the main program:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP802) //LKED.SYSIN DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(ULENGTH) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP802. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 STR PIC X(1000). 01 STR-L PIC S9(4) COMP. 01 STR-EDI PIC -(4)9. PROCEDURE DIVISION. MAIN-LOGIC. DISPLAY "Specify the string:". ACCEPT STR. CALL "ULENGTH" USING BY REFERENCE STR RETURNING STR-L. IF STR-L = -1 DISPLAY "Empty string was given." ELSE MOVE STR-L TO STR-EDI DISPLAY STR-EDI END-IF. STOP RUN. //GO.SYSIN DD * CODE OR NOT TO CODE, THAT'S THE QUESTION...
Comments: - In this example, you can see how values are passed and returned from the called program. Variables that are passed between programs must be defined in LINKAGE SECTION of the called program and then referenced in PROCEDURE DIVISION clause by USING and RETURNING keywords. Calling program passes those variables with use of USING and RETURNING keywords of the CALL clause. - You may remember that when you pass the data from external source, for example via JCL PARM keyword or TSO command, the parameter has a structure of the variable-length record. The first 4 bytes work like RDW. With CALL, program parameter is passed as defined in COBOL, so if it's string the string is passed. If it's packed decimal number, it is passed in packed decimal representation. - If you write a program that's executed as a sub-program it's a bad habit to use DISPLAY command in it. Instead, communitate various conditions by returning a specific values. In this example, '-1' value is returned if an uninitialized variable is passed. - Programs such as ULENGTH that are often executed by other programs should have a clear documentation, especially regarding values that are received and returned by the program, here is an example of such documentation:
************************************************************************ BASIC INFO ************************************************************************ NAME: ULENGTH AUTHOR: JAN SADEK COMPILE DATE: 2018-03-16 COMPILER: ENTERPRISE COBOL 4.1 ************************************************************************ FUNCTIONALITY ************************************************************************ ULENGTH PROGRAM RETURNS THE LENGTH OF THE DATA IN THE GIVEN STRING. ************************************************************************ ARGUMENTS ************************************************************************ 1 ARGUMENT: TYPE: PIC X(1000). DESC: STRING WHICH LENGTH WILL BE CALCULTED. ************************************************************************ RETURNED VALUES ************************************************************************ TYPE: PIC S(9) COMP. DESC: LENGHT OF THE DATA IN THE STRING PASSED AS THE ARGUMENT. POSSIBLE VALUES: 1-1000 - LENGHT OF THE GIVEN STRING. 0 - IF EMPTY STRING IS PASSED. -1 - IF UNITILIZED (LOW-VALUES) STRING IS PASSED. ************************************************************************ KNOWN PROBLEMS ************************************************************************ IF DATA BEGINS WITH SPACES, FOR EXAMPLE " A STRING " LEADING SPACES ARE CONSIDERED PART OF THE STRING. IN THIS CASE RETURNED VALUE WOULD BE 12 INSTEAD OF 8.
Solution 3
Code for the main program:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP803) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP803. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 STR PIC X(1000). 01 STR-L PIC S9(4) COMP. 01 STR-EDI PIC -(4)9. 01 PROGNAME PIC X(8) VALUE "ULENGTH". PROCEDURE DIVISION. MAIN-LOGIC. DISPLAY "Specify the string:". ACCEPT STR. CALL PROGNAME USING BY REFERENCE STR RETURNING STR-L. IF STR-L = -1 DISPLAY "Empty string was given." ELSE MOVE STR-L TO STR-EDI DISPLAY STR-EDI END-IF. STOP RUN. //GO.STEPLIB DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB //GO.SYSIN DD * CODE OR NOT TO CODE, THAT'S THE QUESTION...
Comments: - The only difference in COBOL code is that now CALL function doesn't use literal 'ULENGHT' but a variable that contains the program name. - Now we don't reference ULENGHT module via LKED.SYSIN DD statement. When using dynamic call it won't be linked with the main program module. Instead, standard module search will be performed by the system. So you need to have ULENGTH module in STEPLIB, JOBLIB, LPA, or LNKLST. - The main difference between static and dynamic call is just that. With the static call, called program is linked with the main program. With the dynamic call, it is a standalone module that's loaded and executed when CALL statement is issued. - The static call is faster because called program doesn't have to be loaded from DASD into memory during program execution. - The dynamic call removes the need of recompiling the main program in case any changes to sub-program are made. - Also, with dynamic call load module of the main program is smaller because you avoid code duplication.
Name Prompt Alias-of Size MP802 000018F8 MP803 000013E8
- In decimal representation: MP802(6392 bytes), MP803(5096 bytes).
Solution 4
Code of called program:
IDENTIFICATION DIVISION. PROGRAM-ID. UCUBE. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 CUBE-EDI PIC -(12)9V9(3)E+99. LINKAGE SECTION. 01 CUBE COMP-2. PROCEDURE DIVISION USING CUBE. MAIN-LOGIC. COMPUTE CUBE = CUBE * CUBE * CUBE ON SIZE ERROR MOVE -2 TO CUBE. MOVE CUBE TO CUBE-EDI. DISPLAY "Inside subprogram: " CUBE-EDI. GOBACK.
Code of calling program:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP804) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP804. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM PIC 9(18). 01 NUM-CUBE COMP-2. 01 NUM-CUBE-EDI PIC -(12)9V9(3)E+99. 77 PROGNAME PIC X(8) VALUE "UCUBE". PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-NUM. CALL PROGNAME USING BY REFERENCE NUM-CUBE. PERFORM DISPLAY-NUM. STOP RUN. ACCEPT-NUM. ACCEPT NUM. MOVE NUM TO NUM-CUBE. DISPLAY NUM " accepted". DISPLAY-NUM. IF NUM-CUBE = -2 DISPLAY "Error while computing the cube of: " NUM ELSE MOVE NUM-CUBE TO NUM-CUBE-EDI DISPLAY "Cube of " NUM " = " NUM-CUBE-EDI END-IF. //GO.STEPLIB DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB //GO.SYSIN DD * 4
Comments: - In this case, we couldn't use -1 or 0 for indicating error conditions since both those numbers are valid results of cube operation. But -2 is not therefore it was used to indicate an error. There are better ways of solving such problems, you'll learn them in further tasks. - BY REFERENCE clause passes to the called program pointer to the variable. This means that any operations on it will be done on the original data. - BY CONTENT clause passes a copy of the variable so any operations on it doesn't affect the original variable. - BY VALUE works the same way as BY CONTENT. It's designed to be used with other programming languages like C or Java. To use it you must also specify BY VALUE clause in the USING clause in the called program. It's best to avoid using BY VALUE in COBOL to COBOL communication. Important: - Notice that you can you can achieve the same effect as with REFERENCE version by specifying input variable also on output:
CALL PROGNAME USING BY CONTENT NUM-CUBE RETURNING NUM-CUBE.
- This is often the best solution. It gives a programmer choice if he wants the original copy to be replaced or to copy results to another variable. - An exception to that rule may be a situation in which passed variable is fairly large. In such case, it may be better to pass it via reference.
Solution 5
Main program:
IDENTIFICATION DIVISION. PROGRAM-ID. MP805. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 STR PIC X(1000). 01 WORKMODE PIC X(7). 01 STR-LENGTH PIC S9(4) COMP. 01 STR-LENGTH-EDI PIC -(4)9. 01 PROGNAME PIC X(8) VALUE "ULENGTH". PROCEDURE DIVISION. MAIN-LOGIC. MOVE "TRIMLGT" TO WORKMODE. MOVE " MAINFRAME PLAYGROUND " TO STR. DISPLAY "STRING BEFORE >>" STR "<<". CALL PROGNAME USING BY REFERENCE STR BY CONTENT WORKMODE RETURNING STR-LENGTH. IF STR-LENGTH NOT < 0 MOVE STR-LENGTH TO STR-LENGTH-EDI DISPLAY "STRING LENGTH: " STR-LENGTH-EDI DISPLAY "STRING AFTER >>" STR "<<" ELSE MOVE STR-LENGTH TO STR-LENGTH-EDI MOVE 8 TO RETURN-CODE DISPLAY "ERROR " STR-LENGTH-EDI " OCCURED." END-IF. STOP RUN.
ULENGTH:
IDENTIFICATION DIVISION. PROGRAM-ID. ULENGTH. DATA DIVISION. WORKING-STORAGE SECTION. 01 TRIM-RC PIC S9(4) COMP VALUE 0. 01 PROGNAME PIC X(8) VALUE "UTRIM". 01 TEMP-STR PIC X(1000). LINKAGE SECTION. 01 PARM PIC X(1000). 01 STR-L PIC S9(4) COMP. 01 WORKMODE PIC X(7). PROCEDURE DIVISION USING PARM WORKMODE RETURNING STR-L. MAIN-LOGIC. PERFORM PARM-CHECK. MOVE 0 TO STR-L. IF WORKMODE = "TRIM" PERFORM MODE-TRIM. IF WORKMODE = "LGT" PERFORM MODE-LGT. IF WORKMODE = "TRIMLGT" PERFORM MODE-TRIMLGT. GOBACK. MODE-TRIMLGT. MOVE PARM TO TEMP-STR. CALL PROGNAME USING BY REFERENCE TEMP-STR RETURNING TRIM-RC. PERFORM TRIM-RC-CHECK. INSPECT FUNCTION REVERSE(TEMP-STR) TALLYING STR-L FOR LEADING SPACES. COMPUTE STR-L = LENGTH OF TEMP-STR – STR-L. MODE-LGT. INSPECT FUNCTION REVERSE(PARM) TALLYING STR-L FOR LEADING SPACES. COMPUTE STR-L = LENGTH OF PARM - STR-L. MODE-TRIM. CALL PROGNAME USING BY REFERENCE PARM RETURNING TRIM-RC. PERFORM TRIM-RC-CHECK. INSPECT FUNCTION REVERSE(PARM) TALLYING STR-L FOR LEADING SPACES. COMPUTE STR-L = LENGTH OF PARM - STR-L. PARM-CHECK. IF PARM = LOW-VALUES MOVE -1 TO STR-L GOBACK END-IF. IF WORKMODE NOT = "TRIM" AND "LGT" AND "TRIMLGT" MOVE -2 TO STR-L GOBACK END-IF. TRIM-RC-CHECK. IF TRIM-RC NOT = 0 MOVE -3 TO STR-L GOBACK END-IF.
UTRIM:
IDENTIFICATION DIVISION. PROGRAM-ID. UTRIM. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 LS PIC 9(4) COMP. 01 TS PIC 9(4) COMP. LINKAGE SECTION. 01 STR PIC X(1000). 01 RC PIC S9(4) COMP. PROCEDURE DIVISION USING STR RETURNING RC. MAIN-LOGIC. IF STR = SPACES MOVE 0 TO RC GOBACK. MOVE 0 TO LS TS RC. INSPECT STR TALLYING LS FOR LEADING SPACES. INSPECT FUNCTION REVERSE(STR) TALLYING TS FOR LEADING SPACES. IF LS > 999 OR STR = SPACES OR STR = LOW-VALUES MOVE -1 TO RC. IF RC = 0 AND LS NOT = 0 COMPUTE TS = LENGTH OF STR – TS - LS COMPUTE LS = LS + 1 MOVE STR(LS : TS) TO STR END-IF. GOBACK.
Comments: - As you can see in the main program, you can pass many arguments to the called program, some of them by REFERENCE and some by CONTENT. - When executing other programs from your code you must always test their return code. - In this program, the user decides how the length should be calculated, and also if the leading spaces from the given string should be removed or not. That's why STR variable is passed via reference to both ULENGTH and UTRIM functions. To avoid truncating string in TRIMLGT mode is it simply copied to temporary variable and passed to UTRIM function. This way the original string is kept intact but the length of the trimmed string is returned. - In COBOL RETURN-CODE variable can have only positive values. That's why in case of error the actual error code is display in output (-1 for example) but 8 is moved to RETURN-CODE. - Of course, programs cannot execute each other. For example UTRIM cannot execute ULENGTH because it is executed by ULENGTH. Such combinations only lead to problems and COBOL compiler won't allow it.
Solution 6
After changing STR definition to X(50) in the main program we get incorrect results: 'STRING LENGTH: 1000' After adding some debugging instruction we can view the content of the STR variable:
INSIDE MAIN: MAINFRAME PLAYGROUND INSIDE ULENGTH: MAINFRAME PLAYGROUND TRIMLGT ULENGTH $ m IGZSRTCD SYSOUT UTRIM INSIDE UTRIM: MAINFRAME PLAYGROUND TRIMLGT ULENGTH $ m IGZSRTCD SYSOUT UTRIM MAINFRAME PLAYGROUND TRIMLGT ULENGTH $ m IGZSRTCD SYSOUT UTRIM MAINFRAME PLAYGROUND TRIMLGT ULENGTH $ m IGZSRTCD SYSOUT UTRIM MAINFRAME PLAYGROUND TRIMLGT ULENGTH $ m IGZSRTCD STRING LENGTH: 1000 STRING AFTER >> MAINFRAME PLAYGROUND <<
Comments: - When passing value by REFERENCE you must be sure that variable definition in the called and calling program are identical. - In the above experiment, you can see risks of passing value via reference. COBOL doesn't recognize where the variable ends. ULENGHT program receives only the pointer to the beginning of STR variable while its length is taken from the variable definition in ULENGTH, so it's considered 1000 bytes long. - In the above output, you can see that ULENGHT accesses 1000 bytes from the data area of the entire program. You can see values of all variables in ULENGTH program. Similarly, in UTRIM you can see even more variables. In TRIMLGT mode we can even see TEMP-STR variable which is a copy of the STR. - Using BY CONTENT keyword in the main program and ULENGHT didn't help a bit:
INSIDE MAIN: MAINFRAME PLAYGROUND INSIDE ULENGTH: MAINFRAME PLAYGROUND TRIMLGT ULENGTH w 'H * h # &³ &³ @Y q h h # &³ ö & fÖ g { fY U D * * & UT D U ULENGTH ULENGTH a Dm MAINFRAME PLAYGROUND q * ³ % y * * q * * * y q &³ * &d * { * * D * Ö * f * * y y &³ Qd d \ fY h U & { d D &Wq INSIDE UTRIM: MAINFRAME PLAYGROUND TRIMLGT ULENGTH w 'H * h # &³ &³ @Y q h h # &³ ö & fÖ g { fY U D * * & UT D U ULENGTH ULENGTH a Dm MAINFRAME PLAYGROUND q * ³ % y * * q * * * y q &³ * &d * { * * D * Ö * * * y * f y &³ Qd d \ fY h U & { d D &Wq STRING LENGTH: 1000 STRING AFTER >> MAINFRAME PLAYGROUND <<
- Now instead of the data area, we can see a random junk. - This small experiment nicely shows how important variable definitions are and that you should be always very careful when passing values between programs. - Also, playing with those three modules shows the main advantage of dynamic calls. To make changes in one program you don't have to recompile programs that use it.
Solution 7
UADD code:
IDENTIFICATION DIVISION. PROGRAM-ID. UADD. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM1 PIC 9(8). LINKAGE SECTION. 01 NUM2 PIC 9(8). PROCEDURE DIVISION USING NUM2. MAIN-LOGIC. COMPUTE NUM1 = NUM1 + NUM2. DISPLAY "INSIDE UADD: " NUM1. GOBACK.
Main program code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP807. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM2 PIC 9(8). 77 PROGNAME PIC X(8) VALUE "UADD". PROCEDURE DIVISION. MAIN-LOGIC. MOVE 2 TO NUM2. CALL PROGNAME USING BY CONTENT NUM2. MOVE 3 TO NUM2. CALL PROGNAME USING BY CONTENT NUM2. MOVE 4 TO NUM2. CALL PROGNAME USING BY CONTENT NUM2. STOP RUN.
Results:
Without NUM1 initialization. INSIDE UADD: 00000002 INSIDE UADD: 00000005 INSIDE UADD: 00000009 **************************************** With NUM1 initialization via PIC clause. INSIDE UADD: 00000002 INSIDE UADD: 00000005 INSIDE UADD: 00000009 **************************************** With NUM1 initialization via MOVE statement. INSIDE UADD: 00000002 INSIDE UADD: 00000003 INSIDE UADD: 00000004 **************************************** In INITIAL mode & without NUM1 initialization. INSIDE UADD: 00000002 INSIDE UADD: 00000005 INSIDE UADD: 00000009 **************************************** In INITIAL mode & with NUM1 initialization via PIC clause. INSIDE UADD: 00000002 INSIDE UADD: 00000003 INSIDE UADD: 00000004 **************************************** Without NUM1 initialization & using CANCEL statement after each execution. INSIDE UADD: 00000002 INSIDE UADD: 00000005 INSIDE UADD: 00000009 **************************************** With NUM1 initialization via PIC clause & using CANCEL keyword after each execution. INSIDE UADD: 00000002 INSIDE UADD: 00000003 INSIDE UADD: 00000004
Comments: - The following test presents that sub-program variables are not automatically reinitialized when the sub-program is executed. Data area is the same for all executions of the called program, so if not reinitialized, it will contain the value from the previous execution. - To do it you can use INITIAL mode or CANCEL statement. With them variables are reinitialized with values specified in PIC clause. But remember that variables without PIC clause initialization still won't be initialized. - Statements in PROCEDURE DIVISION are executed each time so initializing variable via MOVE statement always work. Important: - If your goal is to run subprogram in its initial data state (which is most often the case) always code INIT paragraph in which you use MOVE or INITIALIZE statement for variable initialization. This way you don't have to worry about the INITIAL mode and using CANCEL statement.
Solution 8
UADD code:
IDENTIFICATION DIVISION. PROGRAM-ID. UADD. ENVIRONMENT DIVISION. DATA DIVISION. LOCAL-STORAGE SECTION. 01 NUM1 PIC 9(8) VALUE 0. LINKAGE SECTION. 01 NUM2 PIC 9(8). PROCEDURE DIVISION USING NUM2. MAIN-LOGIC. COMPUTE NUM1 = NUM1 + NUM2. DISPLAY "INSIDE UADD: " NUM1. GOBACK.
Results:
Without NUM1 initialization. CEE3207S The system detected a data exception (System Completion Code=0C7). **************************************** With NUM1 initialization via PIC clause. INSIDE UADD: 00000002 INSIDE UADD: 00000003 INSIDE UADD: 00000004 ****************************************
Comments: - LOCAL-STORAGE section is allocated at the start of a load module and freed when the load module returns control to the calling program. Thanks to that, when using LOCAL-STORAGE section you don't have to worry that any data from the previous run is still in the memory. - What you have to worry about is the proper initialization of all variables. Variables in WORKING-STORAGE section are automatically set to binary zeroes, which is not the case for the LOCAL-STORAGE section. That's why now program ends in S0C7 abend in the first test scenario. - Storage initialization also takes processing power, therefore, if a program uses a lot of large variables, using LOCAL-STORAGE section is a more optimal solution from the performance perspective.
Solution 9
Main program:
IDENTIFICATION DIVISION. PROGRAM-ID. MP809. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 PROGNAME PIC X(8) VALUE "UDATE". 01 D-STRUCT. 05 D-YEAR PIC 9(4). 05 D-MONTH PIC 9(2). 05 D-DAY PIC 9(2). 05 D-FORMAT PIC X(20). 05 D-RESULT PIC X(20). 05 D-RC PIC 9(2). PROCEDURE DIVISION. MAIN-LOGIC. MOVE 2013 TO D-YEAR. MOVE 3 TO D-MONTH. MOVE 16 TO D-DAY. MOVE "YYYY-MM-DD" TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 1012 TO D-YEAR. MOVE 5 TO D-MONTH. MOVE 11 TO D-DAY. MOVE "YYYY B.C." TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 1999 TO D-YEAR. MOVE 1 TO D-MONTH. MOVE 12 TO D-DAY. MOVE "MM/DD/YYYY" TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 1999 TO D-YEAR. MOVE 1 TO D-MONTH. MOVE 12 TO D-DAY. MOVE SPACES TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 1999 TO D-YEAR. MOVE 1 TO D-MONTH. MOVE 42 TO D-DAY. MOVE "YYYY-DD-MM" TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 2002 TO D-YEAR. MOVE 11 TO D-MONTH. MOVE 24 TO D-DAY. MOVE "YYMMDD" TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 2049 TO D-YEAR. MOVE 1 TO D-MONTH. MOVE 1 TO D-DAY. MOVE "YYYY in L.A." TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 1980 TO D-YEAR. MOVE 2 TO D-MONTH. MOVE 6 TO D-DAY. MOVE "YYYY M DD" TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE 2018 TO D-YEAR. MOVE 1 TO D-MONTH. MOVE 26 TO D-DAY. MOVE "DD-:-MM-:-YYYY" TO D-FORMAT. PERFORM DISPLAY-THE-DATE. MOVE "1X900326" TO D-STRUCT(1:8). MOVE "YYYY.MM.DD" TO D-FORMAT. PERFORM DISPLAY-THE-DATE. STOP RUN. DISPLAY-THE-DATE. DISPLAY "FORMAT: " D-FORMAT ", DATE: " D-STRUCT(1:8). CALL PROGNAME USING BY REFERENCE D-STRUCT. IF D-RC = 0 DISPLAY "FORMATTED DATE: " D-RESULT ELSE DISPLAY "ERROR '" D-RC "' OCCURED IN UDATE PROGRAM" END-IF. DISPLAY " ".
UDATE program:
IDENTIFICATION DIVISION. PROGRAM-ID. UDATE. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 K1 PIC 99. 77 D-FORMAT-LGT PIC 99. 77 TEMP-STR PIC X(4). 77 YEAR-MODE PIC 9. LINKAGE SECTION. 01 D-STRUCT. 05 D-YEAR PIC 9(4). 05 D-MONTH PIC 9(2). 05 D-DAY PIC 9(2). 05 D-FORMAT PIC X(20). 05 D-RESULT PIC X(20). 05 D-RC PIC 9(2). PROCEDURE DIVISION USING D-STRUCT. MAIN-LOGIC. PERFORM INIT. PERFORM DATE-CHECK. PERFORM FORMAT-CHECK. PERFORM GENERATE-FORMATTED-DATE. GOBACK. INIT. MOVE 0 TO D-RC. MOVE SPACES TO D-RESULT. MOVE 2 TO YEAR-MODE. DATE-CHECK. IF D-YEAR IS NOT NUMERIC OR D-MONTH IS NOT NUMERIC OR D-DAY IS NOT NUMERIC MOVE 16 TO D-RC GOBACK END-IF. IF D-MONTH < 1 OR D-MONTH > 12 OR D-DAY < 1 OR D-DAY > 31 MOVE 12 TO D-RC GOBACK END-IF. FORMAT-CHECK. MOVE 0 TO D-FORMAT-LGT. INSPECT FUNCTION REVERSE(D-FORMAT) TALLYING D-FORMAT-LGT FOR LEADING SPACES. COMPUTE D-FORMAT-LGT = LENGTH OF D-FORMAT - D-FORMAT-LGT. MOVE 0 TO K1. INSPECT D-FORMAT TALLYING K1 FOR ALL "YYYY" "YY" "MM" "DD". IF K1 = 0 MOVE 8 TO D-RC GOBACK. GENERATE-FORMATTED-DATE. MOVE D-FORMAT TO D-RESULT. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 = D-FORMAT-LGT IF D-FORMAT(K1:4) = "YYYY" MOVE 4 TO YEAR-MODE MOVE D-YEAR TO D-RESULT(K1:4) END-IF IF D-FORMAT(K1:2) = "YY" AND YEAR-MODE = 2 MOVE D-YEAR TO TEMP-STR MOVE TEMP-STR(3:2) TO D-RESULT(K1:2) END-IF IF D-FORMAT(K1:2) = "MM" MOVE D-MONTH TO D-RESULT(K1:2) END-IF IF D-FORMAT(K1:2) = "DD" MOVE D-DAY TO D-RESULT(K1:2) END-IF END-PERFORM.
Output:
FORMAT: YYYY-MM-DD , DATE: 20130316 FORMATTED DATE: 2013-03-16 FORMAT: YYYY B.C. , DATE: 10120511 FORMATTED DATE: 1012 B.C. FORMAT: MM/DD/YYYY , DATE: 19990112 FORMATTED DATE: 01/12/1999 FORMAT: , DATE: 19990112 ERROR '08' OCCURED IN UDATE PROGRAM FORMAT: YYYY-DD-MM , DATE: 19990142 ERROR '12' OCCURED IN UDATE PROGRAM FORMAT: YYMMDD , DATE: 20021124 FORMATTED DATE: 021124 FORMAT: YYYY in L.A. , DATE: 20490101 FORMATTED DATE: 2049 in L.A. FORMAT: YYYY M DD , DATE: 19800206 FORMATTED DATE: 1980 M 06 FORMAT: DD-:-MM-:-YYYY , DATE: 20180126 FORMATTED DATE: 26-:-01-:-2018 FORMAT: YYYY.MM.DD , DATE: 1X900326 ERROR '16' OCCURED IN UDATE PROGRAM
Not much new in this exercise. A few points are worth looking at: - Passing the structure as an argument. Remember that structure is nothing more than alphanumeric variable (string) so you can pass it as a single argument. Of course, the called program must be also aware of the structure definition. - Algorithm for generating the formatted date in GENERATE-FORMATTED-DATE paragraph. - Use of INSPECT functions in FORMAT-CHECK. - INIT paragraph in which variables are initialized. Thanks to it we don't have to worry that any variable will retain state from a previous program execution. - Error checking.
Solution 10
Main program code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP809) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP810. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT OPTIONAL FILE-SEQ ASSIGN TO INFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS FILE-SEQ-STAT. DATA DIVISION. FILE SECTION. FD FILE-SEQ RECORDING MODE F. 01 FILE-SEQ-REC PIC X(80). WORKING-STORAGE SECTION. 77 PROGNAME PIC X(8) VALUE "UGETSIZE". 77 NUM-EDI PIC Z(17)9. 77 FILE-SEQ-STAT PIC XX. 77 FILE-SEQ-EOF PIC 9. 01 FILE-STATS. 05 FILE-REC-CNT PIC 9(18) COMP. 05 FILE-FULL-SIZE PIC 9(18) COMP. 05 FILE-MIN-SIZE PIC 9(18) COMP. 05 FILE-AVG-LRECL PIC 9(4) COMP. 05 FILE-RC PIC XX. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM GET-FILE-STATS. PERFORM OPEN-FILE. PERFORM DISPLAY-FILE-STATS. PERFORM DISPLAY-THE-FILE. PERFORM CLOSE-FILE. STOP RUN. GET-FILE-STATS. CALL PROGNAME RETURNING FILE-STATS. IF FILE-RC NOT = 0 DISPLAY "ERROR " FILE-RC " OCCURED DURING FILE READ." MOVE FILE-RC TO RETURN-CODE STOP RUN END-IF. DISPLAY-FILE-STATS. DISPLAY "*********************************". DISPLAY "********** FILE STATISTICS ******". DISPLAY "*********************************". MOVE FILE-REC-CNT TO NUM-EDI. DISPLAY "RECORD COUNT: " NUM-EDI. MOVE FILE-FULL-SIZE TO NUM-EDI. DISPLAY "FULL SIZE : " NUM-EDI. MOVE FILE-MIN-SIZE TO NUM-EDI. DISPLAY "MIN SIZE : " NUM-EDI. MOVE FILE-AVG-LRECL TO NUM-EDI. DISPLAY "AVG REC LGT : " NUM-EDI. DISPLAY-THE-FILE. DISPLAY "*********************************". DISPLAY "********** FILE CONTENT *********". DISPLAY "*********************************". READ FILE-SEQ AT END MOVE 1 TO FILE-SEQ-EOF PERFORM FILE-CHECK. PERFORM UNTIL FILE-SEQ-EOF = 1 DISPLAY FILE-SEQ-REC READ FILE-SEQ AT END MOVE 1 TO FILE-SEQ-EOF END-READ END-PERFORM. DISPLAY "*********************************". DISPLAY "********** END OF FILE **********". DISPLAY "*********************************". OPEN-FILE. MOVE 0 TO FILE-SEQ-EOF. OPEN INPUT FILE-SEQ. PERFORM FILE-CHECK. CLOSE-FILE. CLOSE FILE-SEQ. PERFORM FILE-CHECK. FILE-CHECK. IF FILE-SEQ-STAT NOT = "00" DISPLAY FILE-SEQ-STAT " FILE ERROR OCCURED." CLOSE FILE-SEQ STOP RUN END-IF. //GO.STEPLIB DD DISP=SHR,DSN=JSADEK.MY.COBOL.LINKLIB //GO.INFILE DD DISP=SHR,DSN=JSADEK.MY.COBOL(MP709)
UGETSIZE code:
IDENTIFICATION DIVISION. PROGRAM-ID. UGETSIZE. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT OPTIONAL FILE-SEQ ASSIGN TO INFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS FILE-SEQ-STAT. DATA DIVISION. FILE SECTION. FD FILE-SEQ RECORDING MODE F. 01 FILE-SEQ-REC PIC X(80). WORKING-STORAGE SECTION. 77 FILE-SEQ-EOF PIC 9. 77 FILE-SEQ-STAT PIC XX. 77 TMP-STR PIC X(1000). 77 PROGNAME PIC X(8) VALUE "ULENGTH". 77 FILE-SEQ-RECLGT PIC S9(4) COMP. LINKAGE SECTION. 01 FILE-STATS. 05 FILE-REC-CNT PIC 9(18) COMP. 05 FILE-FULL-SIZE PIC 9(18) COMP. 05 FILE-MIN-SIZE PIC 9(18) COMP. 05 FILE-AVG-LRECL PIC 9(4) COMP. 05 FILE-RC PIC XX. PROCEDURE DIVISION RETURNING FILE-STATS. MAIN-LOGIC. PERFORM INIT. PERFORM READ-FILE. PERFORM CALCULATE-REMAINING-STATS. PERFORM CLEANUP. GOBACK. INIT. OPEN INPUT FILE-SEQ. PERFORM FILE-CHECK. MOVE 0 TO FILE-REC-CNT. MOVE 0 TO FILE-FULL-SIZE. MOVE 0 TO FILE-MIN-SIZE. MOVE 0 TO FILE-AVG-LRECL. MOVE 0 TO FILE-RC. MOVE 0 TO FILE-SEQ-EOF. CLEANUP. CLOSE FILE-SEQ. PERFORM FILE-CHECK. READ-FILE. READ FILE-SEQ AT END MOVE 1 TO FILE-SEQ-EOF PERFORM FILE-CHECK. PERFORM UNTIL FILE-SEQ-EOF = 1 ADD 1 TO FILE-REC-CNT PERFORM GET-TRIMMED-LENGTH READ FILE-SEQ AT END MOVE 1 TO FILE-SEQ-EOF END-READ END-PERFORM. GET-TRIMMED-LENGTH. MOVE FILE-SEQ-REC TO TMP-STR. CALL PROGNAME USING BY CONTENT TMP-STR "TRIMLGT" RETURNING FILE-SEQ-RECLGT. IF FILE-SEQ-RECLGT < 0 MOVE FILE-SEQ-RECLGT TO FILE-RC PERFORM CLEANUP GOBACK ELSE COMPUTE FILE-MIN-SIZE = FILE-MIN-SIZE + FILE-SEQ-RECLGT END-COMPUTE END-IF. CALCULATE-REMAINING-STATS. COMPUTE FILE-FULL-SIZE = FILE-REC-CNT * 80. COMPUTE FILE-AVG-LRECL ROUNDED = FILE-MIN-SIZE / FILE-REC-CNT. FILE-CHECK. IF FILE-SEQ-STAT NOT = "00" MOVE FILE-SEQ-STAT TO FILE-RC PERFORM CLEANUP GOBACK END-IF.
Output:
********************************* ********** FILE STATISTICS ****** ********************************* RECORD COUNT: 525 FULL SIZE : 42000 MIN SIZE : 11670 AVG REC LGT : 22 ********************************* ********** FILE CONTENT ********* ********************************* //RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP709) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP709. ...
In comparison, performing the same activity in Notepad++ gives: Lenght: 12718 (11670 was calculated by UGETSIZE). Seems like an error but it isn't. Notepad++ also counts CR+NL control characters. There are 525 records in the file from which 524 will have CR+NL characters (on Windows). 12718 – (524 * 2) = 11670. Comments: - Processing the same file from both main and called program is possible. DDs assigned to the main program are always available to the called programs. - Still, the OPEN and CLOSE instructions must be issued by each program separately. So all programs that use the file must have appropriate SELECT and FD statements. - As you can see, PDS members are processed in COBOL the same way as sequential data sets. - In UGETSIZE, CLEANUP paragraph is executed before each GOBACK instruction. In case of file processing, you must make sure that the file is closed if an error occurs. Leaving a VSAM file open may leave the file unavailable for other programs. It's usually not a problem with sequential files but you should always take care of handling various error conditions.
Error handling
Introduction
In this Assignment, you'll learn some basics regarding error handling and debugging in COBOL on z/OS. Error handling from the perspective of COBOL language, z/OS language environment, and good coding practices is a huge subject so treat this Assignments as a short introduction to it. One important topic not covered here is "IBM Debug for z Systems" tool, which is the most powerful debugging software. It's usually used in tandem with IBM Rational Developer which is also not covered by this course.
Tasks
![]() 1. Write a program that reads a file with two columns of numeric data:
- Data in the first column represents customer ID (12 digits). The second column stores account balance in '-99999999.99$' format.
- The program should calculate and add a yearly interest rate = 2.5%.
- Next program should write updated amounts to the output file.
- The input file should be a VSAM KSDS. The output file should be sequential.
- Use DECLARATIVES for file error handling.
1. Write a program that reads a file with two columns of numeric data:
- Data in the first column represents customer ID (12 digits). The second column stores account balance in '-99999999.99$' format.
- The program should calculate and add a yearly interest rate = 2.5%.
- Next program should write updated amounts to the output file.
- The input file should be a VSAM KSDS. The output file should be sequential.
- Use DECLARATIVES for file error handling.
![]() 2. Write a program that converts the text in a sequential file from EBCDIC to ASCII and UTF-16:
- Use debugging mode and code "debugging lines".
- In debugging mode, records should be displayed before and after conversions to ASCII and UTF-16.
- For file error handling use DECLARATIVES section as in the previous Task but use one paragraph for all file errors.
- After the program is done download the files, and open them in Notepad++ to confirm the conversion was done correctly.
2. Write a program that converts the text in a sequential file from EBCDIC to ASCII and UTF-16:
- Use debugging mode and code "debugging lines".
- In debugging mode, records should be displayed before and after conversions to ASCII and UTF-16.
- For file error handling use DECLARATIVES section as in the previous Task but use one paragraph for all file errors.
- After the program is done download the files, and open them in Notepad++ to confirm the conversion was done correctly.
![]() 3. Modify the program from Task#2:
- Replace debugging lines with debugging statements.
- Use DEBUG-ITEM special register as well.
3. Modify the program from Task#2:
- Replace debugging lines with debugging statements.
- Use DEBUG-ITEM special register as well.
![]() 4. Write a program that accepts two numbers A and B and divides A by B:
- Instead of checking user input prepare routine that will handle all abends in the program.
- Use Condition Handling (CEEHDLR and CEEHDLU services).
- Display information about the encountered abend and let the program to end in error.
4. Write a program that accepts two numbers A and B and divides A by B:
- Instead of checking user input prepare routine that will handle all abends in the program.
- Use Condition Handling (CEEHDLR and CEEHDLU services).
- Display information about the encountered abend and let the program to end in error.
![]() 5. Modify Program from Task#1.
- Modify some record in KSDS so it contains an invalid number so the program abends while calculating interest rate for this record.
- Write condition handling routine and set it up with CEEHDLR and CEEHDLU services.
- When a record with invalid numeric is encountered (when abend happens) the record should be skipped. Information about skipped record should be displayed and after the remaining records are processed the program should end with RC=4.
- If any other abend happens, the program should end in error as usual.
5. Modify Program from Task#1.
- Modify some record in KSDS so it contains an invalid number so the program abends while calculating interest rate for this record.
- Write condition handling routine and set it up with CEEHDLR and CEEHDLU services.
- When a record with invalid numeric is encountered (when abend happens) the record should be skipped. Information about skipped record should be displayed and after the remaining records are processed the program should end with RC=4.
- If any other abend happens, the program should end in error as usual.
![]() 6. Write a program that accepts an input string and displays its length using ULENGTH program from "CALL" assignment.
- Use ON EXCEPTION clause while calling ULENGTH.
- What's the purpose of this clause?
6. Write a program that accepts an input string and displays its length using ULENGTH program from "CALL" assignment.
- Use ON EXCEPTION clause while calling ULENGTH.
- What's the purpose of this clause?
Hint 1
Check "EXCEPTION/ERROR declarative" in "Enterprise COBOL for z/OS: Language Reference".
Hint 2
Conversion from EBCDIC to ASCII is done with the use of NATIONAL-OF and DISPLAY-OF functions. When doing such conversion for the entire record you must always remember to use CRLF characters to indicate the end of the line and use data set with VB record organization. "D" in column 7 indicates "debugging lines". See "Appendix D. Source language debugging" in "Enterprise COBOL for z/OS: Language Reference".
Hint 3
To be able to use debugging statement you also need to use DEBUG runtime options. You can check how to do that in "Overriding the default runtime options" topic in "z/OS Language Environment Programming Guide" and in "z/OS Language Environment Customization".
Hint 4
For more information about CEEHDLR and CEEHDLU see "z/OS Language Environment Programming Reference". Also, "z/OS Language Environment Runtime Messages" will be handy.
Hint 5
You'll need to use Cursor Resume, research CEE3SRP AND CEEMRCE services for more information.
Solution 1
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP901. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO INFILE ORGANIZATION IS INDEXED RECORD KEY IS CUST-ID ACCESS MODE IS DYNAMIC FILE STATUS IS CUST-STAT CUST-VSAMSTAT. SELECT OUT-FILE ASSIGN TO OUTFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS OUT-STAT. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(12). 05 CUST-BALANCE PIC -(8)9.99. 05 CUST-CURRENCY PIC X. FD OUT-FILE RECORDING MODE IS F. 01 OUT-RECORD. 05 OUT-ID PIC 9(12). 05 OUT-BALANCE PIC -(8)9.99. 05 OUT-CURRENCY PIC X. WORKING-STORAGE SECTION. 01 CUST-EOF PIC 9. 01 CUST-STAT PIC XX. 01 CUST-VSAMSTAT. 05 CUST-VSAMRC PIC 9(2) COMP. 05 CUST-VSAMFC PIC 9(2) COMP. 05 CUST-VSAMFB PIC 9(2) COMP. 01 OUT-STAT PIC XX. 77 TEMP-BALANCE PIC S9(8)V99 COMP. PROCEDURE DIVISION. DECLARATIVES. CUST-FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON CUST-FILE. DISPLAY "'INFILE' FILE ERROR OCCUREED:". DISPLAY "FILE STATUS: " CUST-STAT. DISPLAY "VSAM RETURN CODE : " CUST-VSAMRC. DISPLAY "VSAM FUNCTION CODE: " CUST-VSAMFC. DISPLAY "VSAM FEEDBACK CODE: " CUST-VSAMFB. DISPLAY "PROGRAM TERMINATES.". MOVE CUST-STAT TO RETURN-CODE. IF CUST-STAT NOT = "42" PERFORM CLOSE-FILES. STOP RUN. OUT-FILE-ERROS SECTION. USE AFTER ERROR PROCEDURE ON OUT-FILE. DISPLAY "'OUTFILE' FILE ERROR OCCUREED:". DISPLAY "FILE STATUS: " OUT-STAT. DISPLAY "PROGRAM TERMINATES.". MOVE OUT-STAT TO RETURN-CODE. IF CUST-STAT NOT = "42" PERFORM CLOSE-FILES. STOP RUN. END DECLARATIVES. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM CALCULATE-INTRESTS. PERFORM CLOSE-FILES. STOP RUN. CALCULATE-INTRESTS. READ CUST-FILE NEXT AT END MOVE 1 TO CUST-EOF. PERFORM UNTIL CUST-EOF = 1 DISPLAY CUST-RECORD " COPIED." MOVE CUST-RECORD TO OUT-RECORD MOVE CUST-BALANCE TO TEMP-BALANCE IF TEMP-BALANCE > 0 COMPUTE TEMP-BALANCE = TEMP-BALANCE * 1.025 MOVE TEMP-BALANCE TO OUT-BALANCE END-IF WRITE OUT-RECORD READ CUST-FILE NEXT AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. OPEN-FILES. MOVE 0 TO CUST-EOF. OPEN INPUT CUST-FILE. OPEN OUTPUT OUT-FILE. CLOSE-FILES. CLOSE CUST-FILE. CLOSE OUT-FILE.
Comments: - So far we've used FILE STATUS clause to test for file error conditions. However there is a better way to catch file errors. With DECLARATIVES you don't have to worry about performing file check after chosen file operations. DECLARATIVES catch all errors and abends related to files operations. - SECTIONS are usually used with DECLARATIVES but it's not a requirement. You can also code paragraphs, but using SECTIONS is a good idea if more than one paragraph is used for error handling. What really matters is the "USE" keyword. It defines which SECTIONS/PARAGRAPHS will be executed when an error condition happens. - USE AFTER ERROR and USE AFTER EXCEPTION are synonymous. - Consider following situation. Error happens during file open. DECLARATIVES section is triggered but we don't know if the file is in opened or closed status. If you try to close file in this section you can enter an infinite loop where CLOSE instruction generates error which triggers DECLARATIVE section which tries to close the file again. On the other hand, leaving VSAM file open may leave it unavailable for other programs. The easiest way to solve this conflict is to test FILE STATUS for code 42 "CLOSE operation has been tried on file that's already closed". Below you can see an output created by such situation:
IGZ0201W A file attribute mismatch was detected. File OUT-FILE in program MP901P2 had a record length of 24 and the file specified in the ASSIGN clause had a record length of 25. 'OUTFILE' FILE ERROR OCCUREED: FILE STATUS: 39 PROGRAM TERMINATES. 'OUTFILE' FILE ERROR OCCUREED: FILE STATUS: 42 PROGRAM TERMINATES. 'INFILE' FILE ERROR OCCUREED: FILE STATUS: 42 VSAM RETURN CODE : 04 VSAM FUNCTION CODE: 00 VSAM FEEDBACK CODE: 04 PROGRAM TERMINATES.
- As you can DECLARATIVES make file handling errors much easier. With them, you can catch more error conditions with less coding.
Solution 2
COBOL code:
//DELSTEP EXEC PGM=IEFBR14 //DELDD1 DD DSN=JSADEK.COBOL.MP902.ASCII, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //DELDD2 DD DSN=JSADEK.COBOL.MP902.UTF16, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP902) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP902. ENVIRONMENT DIVISION. CONFIGURATION SECTION. SOURCE-COMPUTER. MVSA WITH DEBUGGING MODE. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT EBC-FILE ASSIGN TO INEBCDIC ORGANIZATION IS SEQUENTIAL FILE STATUS IS EBC-STAT. SELECT ASC-FILE ASSIGN TO OUTASCII ORGANIZATION IS SEQUENTIAL FILE STATUS IS ASC-STAT. SELECT UTF-FILE ASSIGN TO OUTUTF16 ORGANIZATION IS SEQUENTIAL FILE STATUS IS UTF-STAT. DATA DIVISION. FILE SECTION. FD EBC-FILE RECORDING MODE IS F. 01 EBC-RECORD PIC X(80). FD ASC-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 82 CHARACTERS DEPENDING ON RECL. 01 ASC-RECORD PIC X(82). FD UTF-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 164 CHARACTERS DEPENDING ON RECL. 01 UTF-RECORD PIC N(82). WORKING-STORAGE SECTION. 01 EBC-EOF PIC 9. 01 EBC-STAT PIC XX. 01 ASC-STAT PIC XX. 01 UTF-STAT PIC XX. 01 ASCII-CRLF-STRUCT. 05 ASCII-CRLF PIC 9(4) COMP VALUE 3338. 01 UTF16-CRLF-STRUCT. 05 UTF16-CRLF1 PIC 9(4) COMP VALUE 10. 05 UTF16-CRLF2 PIC 9(4) COMP VALUE 13. 77 RECL PIC 9(4) COMP. 77 T1 PIC 9(4) COMP. PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON EBC-FILE ASC-FILE UTF-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'INEBCDIC' STATUS: " EBC-STAT. DISPLAY "'OUTASCII' STATUS: " ASC-STAT. DISPLAY "'OUTUTF16' STATUS: " UTF-STAT. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF EBC-STAT NOT = "42" CLOSE EBC-FILE. IF ASC-STAT NOT = "42" CLOSE ASC-FILE. IF UTF-STAT NOT = "42" CLOSE UTF-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC SECTION. PERFORM OPEN-FILES. PERFORM CONVERT-EBCDIC-FILE. PERFORM CLOSE-FILES. STOP RUN. CONVERT-EBCDIC-FILE. READ EBC-FILE AT END MOVE 1 TO EBC-EOF. PERFORM UNTIL EBC-EOF = 1 D DISPLAY "EBCDIC: " EBC-RECORD MOVE 0 TO RECL INSPECT FUNCTION REVERSE(EBC-RECORD) TALLYING RECL FOR LEADING SPACES COMPUTE RECL = LENGTH OF EBC-RECORD - RECL MOVE FUNCTION NATIONAL-OF(EBC-RECORD, 1140) TO UTF-RECORD MOVE FUNCTION DISPLAY-OF(UTF-RECORD, 819) TO ASC-RECORD COMPUTE T1 = RECL + 1 D DISPLAY "T1: " T1 MOVE ASCII-CRLF-STRUCT TO ASC-RECORD(T1 : 2) MOVE UTF16-CRLF-STRUCT TO UTF-RECORD(T1 : 2) ADD 2 TO RECL D DISPLAY "RECL: " RECL D DISPLAY "ASCII : " ASC-RECORD(1 : RECL) D DISPLAY "UTF-16: " UTF-RECORD(1 : RECL) WRITE ASC-RECORD COMPUTE RECL = RECL * 2 WRITE UTF-RECORD READ EBC-FILE AT END MOVE 1 TO EBC-EOF END-READ END-PERFORM. OPEN-FILES. MOVE 0 TO EBC-EOF. OPEN INPUT EBC-FILE. OPEN OUTPUT ASC-FILE. OPEN OUTPUT UTF-FILE. CLOSE-FILES. CLOSE EBC-FILE. CLOSE ASC-FILE. CLOSE UTF-FILE. //GO.INEBCDIC DD DISP=SHR,DSN=JSADEK.COBOL.MP902.EBCDIC //GO.OUTASCII DD DSN=JSADEK.COBOL.MP902.ASCII,DISP=(NEW,CATLG), // SPACE=(TRK,(1,15)),RECFM=VB,LRECL=86,BLKSIZE=27998 //GO.OUTUTF16 DD DSN=JSADEK.COBOL.MP902.UTF16,DISP=(NEW,CATLG), // SPACE=(TRK,(1,15)),RECFM=VB,LRECL=168,BLKSIZE=27998
Comments: - Notice "SOURCE-COMPUTER. MVSA WITH DEBUGGING MODE." line in CONFIGURATION SECTION. It defines that the program will be compiled and ran in debug mode. In this mode, except normal instructions, two additional instruction types are executed "debugging lines" and "debugging statements". In this program, we work with debugging lines. Those are all lines marked with "D" in column 7. They are executed only when program is compiled in "DEBUGGING MODE". - You can code debugging lines pretty much anywhere in your program. Thanks to that, you can have a set of variables and paragraphs that are used only in for debugging purposes. - You can use "USE AFTER ERROR" with INPUT, OUTPUT, I-O, and EXTEND options which make a particular section triggered by all files opened in given mode. Unfortunately, you cannot specify all those options at the same time so if you want to code an universal procedure for all file errors it's best to specify all file names in a single USE AFTER ERROR clause.
Solution 3
COBOL code:
//DELSTEP EXEC PGM=IEFBR14 //DELDD1 DD DSN=JSADEK.COBOL.MP902.ASCII, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //DELDD2 DD DSN=JSADEK.COBOL.MP902.UTF16, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //RUNCOBOL EXEC IGYWCLG,PARM.GO='/DEBUG' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP903) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP903. ENVIRONMENT DIVISION. CONFIGURATION SECTION. SOURCE-COMPUTER. MVSA WITH DEBUGGING MODE. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT EBC-FILE ASSIGN TO INEBCDIC ORGANIZATION IS SEQUENTIAL FILE STATUS IS EBC-STAT. SELECT ASC-FILE ASSIGN TO OUTASCII ORGANIZATION IS SEQUENTIAL FILE STATUS IS ASC-STAT. SELECT UTF-FILE ASSIGN TO OUTUTF16 ORGANIZATION IS SEQUENTIAL FILE STATUS IS UTF-STAT. DATA DIVISION. FILE SECTION. FD EBC-FILE RECORDING MODE IS F. 01 EBC-RECORD PIC X(80). FD ASC-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 82 CHARACTERS DEPENDING ON RECL. 01 ASC-RECORD PIC X(82). FD UTF-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 164 CHARACTERS DEPENDING ON RECL. 01 UTF-RECORD PIC N(82). WORKING-STORAGE SECTION. 01 EBC-EOF PIC 9. 01 EBC-STAT PIC XX. 01 ASC-STAT PIC XX. 01 UTF-STAT PIC XX. 01 ASCII-CRLF-STRUCT. 05 ASCII-CRLF PIC 9(4) COMP VALUE 3338. 01 UTF16-CRLF-STRUCT. 05 UTF16-CRLF1 PIC 9(4) COMP VALUE 10. 05 UTF16-CRLF2 PIC 9(4) COMP VALUE 13. 77 RECL PIC 9(4) COMP. 77 T1 PIC 9(4) COMP. D77 RECNUM PIC 9(8) COMP VALUE 0. PROCEDURE DIVISION. DECLARATIVES. DEBUG-RECORD SECTION. USE FOR DEBUGGING ON WRITE-A-RECORD. DEBUG-A-RECORD. DISPLAY "DEBUG LINE: " DEBUG-LINE. DISPLAY "DEBUG NAME: " DEBUG-NAME. DISPLAY "DEBUG CONTENTS: " DEBUG-CONTENTS. DISPLAY "PROCESSING " RECNUM " RECORD.". DISPLAY "RECORD LENGTH: " RECL. DISPLAY "EBCDIC: " EBC-RECORD. DISPLAY "ASCII : " ASC-RECORD(1 : RECL). DISPLAY "UTF-16: " UTF-RECORD(1 : RECL). DISPLAY " ". FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON EBC-FILE ASC-FILE UTF-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'INEBCDIC' STATUS: " EBC-STAT. DISPLAY "'OUTASCII' STATUS: " ASC-STAT. DISPLAY "'OUTUTF16' STATUS: " UTF-STAT. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF EBC-STAT NOT = "42" CLOSE EBC-FILE. IF ASC-STAT NOT = "42" CLOSE ASC-FILE. IF UTF-STAT NOT = "42" CLOSE UTF-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC SECTION. PERFORM OPEN-FILES. PERFORM CONVERT-EBCDIC-FILE. PERFORM CLOSE-FILES. D DISPLAY RECNUM " RECORDS WERE PROCESSED.". STOP RUN. CONVERT-EBCDIC-FILE. READ EBC-FILE AT END MOVE 1 TO EBC-EOF. PERFORM UNTIL EBC-EOF = 1 PERFORM CONVERT-A-RECORD PERFORM WRITE-A-RECORD READ EBC-FILE AT END MOVE 1 TO EBC-EOF END-READ END-PERFORM. CONVERT-A-RECORD. MOVE 0 TO RECL. INSPECT FUNCTION REVERSE(EBC-RECORD) TALLYING RECL FOR LEADING SPACES. COMPUTE RECL = LENGTH OF EBC-RECORD - RECL. MOVE FUNCTION NATIONAL-OF(EBC-RECORD, 1140) TO UTF-RECORD. MOVE FUNCTION DISPLAY-OF(UTF-RECORD, 819) TO ASC-RECORD. D ADD 1 TO RECNUM. WRITE-A-RECORD. COMPUTE T1 = RECL + 1. MOVE ASCII-CRLF-STRUCT TO ASC-RECORD(T1 : 2). MOVE UTF16-CRLF-STRUCT TO UTF-RECORD(T1 : 2). ADD 2 TO RECL. WRITE ASC-RECORD. COMPUTE RECL = RECL * 2. WRITE UTF-RECORD. OPEN-FILES. MOVE 0 TO EBC-EOF. OPEN INPUT EBC-FILE. OPEN OUTPUT ASC-FILE. OPEN OUTPUT UTF-FILE. CLOSE-FILES. CLOSE EBC-FILE. CLOSE ASC-FILE. CLOSE UTF-FILE. //GO.INEBCDIC DD DISP=SHR,DSN=JSADEK.COBOL.MP902.EBCDIC //GO.OUTASCII DD DSN=JSADEK.COBOL.MP902.ASCII,DISP=(NEW,CATLG), // SPACE=(TRK,(1,15)),RECFM=VB,LRECL=86,BLKSIZE=27998 //GO.OUTUTF16 DD DSN=JSADEK.COBOL.MP902.UTF16,DISP=(NEW,CATLG), // SPACE=(TRK,(1,15)),RECFM=VB,LRECL=168,BLKSIZE=27998
Comments: - Debugging statements are paragraphs defined as DECLARATIVES which are executed only in debugging mode. They are executed before execution of selected paragraph, in the above example before WRITE-A-RECORD. - You can also decide to execute a general debugging section before executing all paragraphs. It may be a useful thing to do to track variable changes throughout the program. - To use debugging statements you need to specify two things: Compile-time switch "SOURCE-COMPUTER. MVSA WITH DEBUGGING MODE." and Object-time switch "PARM.GO='/DEBUG'". - Debugging statements are always executed before a specific or every procedure is executed. This limits their use. In this example, we had to create an additional paragraph WRITE-A-RECORD to be able to see variable content in the desired point in the program.
Solution 4
Main program:
//RUNCOBOL EXEC IGYWCLG,PARM.COBOL='LIB',PARM.GO='/ERRCOUNT(5)' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //COBOL.SYSLIB DD DISP=SHR,DSN=CEE.SCEESAMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP904) //LKED.SYSIN DD DISP=SHR,DSN=JSADEK.MY.COBOL.LINKLIB(MP904HDL) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP904. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 A PIC S9(8) COMP. 01 A-EDI PIC -(7)9. 01 B PIC S9(8) COMP. 01 B-EDI PIC -(7)9. 01 C PIC S9(8)V9(3) COMP. 01 C-EDI PIC -(7)9.9(3). 01 A-STR PIC X(20). 01 B-STR PIC X(20). 01 INDATA PIC X(20). 01 CEEHDLR PIC X(8) VALUE "CEEHDLR". 01 CEEHDLU PIC X(8) VALUE "CEEHDLU". * CONDITION HANDLER VARIABLES 01 ROUTINE PROCEDURE-POINTER. 01 TOKEN PIC S9(9) COMP VALUE 0. 01 RESULT PIC S9(9) COMP. 88 RESUME VALUE 10. 88 PERCOLATE VALUE 20. 88 PERCOLATE-SF VALUE 21. 88 PROMOTE VALUE 30. 88 PROMOTE-SF VALUE 31. 01 FEEDBACK. 02 CONDITION-TOKEN-VALUE. COPY CEEIGZCT. 03 CASE-1-CONDITION-ID. 04 SEVERITY PIC S9(4) COMP. 04 MSG-NO PIC S9(4) COMP. 03 CASE-2-CONDITION-ID REDEFINES CASE-1-CONDITION-ID. 04 CLASS-CODE PIC S9(4) COMP. 04 CAUSE-CODE PIC S9(4) COMP. 03 CASE-SEV-CTL PIC X. 03 FACILITY-ID PIC XXX. 02 I-S-INFO PIC S9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM REG-HANDLER. PERFORM CALCULATE-RESULTS. PERFORM UNREG-HANDLER. STOP RUN. CALCULATE-RESULTS. PERFORM ACCEPT-INPUT. PERFORM UNTIL INDATA = LOW-VALUES OR SPACES PERFORM CONVERT-INPUT-TO-NUMS COMPUTE C ROUNDED = A / B MOVE C TO C-EDI DISPLAY "RESULTS: " A-EDI " / " B-EDI " = " C-EDI PERFORM ACCEPT-INPUT END-PERFORM. ACCEPT-INPUT. MOVE SPACES TO INDATA. ACCEPT INDATA. CONVERT-INPUT-TO-NUMS. UNSTRING INDATA DELIMITED BY ALL SPACES INTO A-STR B-STR ON OVERFLOW PERFORM OVERFLOW-END. COMPUTE A = FUNCTION NUMVAL(A-STR). COMPUTE B = FUNCTION NUMVAL(B-STR). MOVE A TO A-EDI. MOVE B TO B-EDI. OVERFLOW-END. DISPLAY "DATA OVERFLOW WHILE PROCESSING: " INDATA. MOVE 8 TO RETURN-CODE. STOP RUN. REG-HANDLER. SET ROUTINE TO ENTRY "MP904HDL". CALL CEEHDLR USING ROUTINE TOKEN FEEDBACK. IF NOT CEE000 DISPLAY "CEEHDLR FAILED." DISPLAY "MSG NO: " MSG-NO STOP RUN END-IF. UNREG-HANDLER. CALL CEEHDLU USING ROUTINE TOKEN FEEDBACK. IF NOT CEE000 DISPLAY "CEEHDLU FAILED." DISPLAY "MSG NO: " MSG-NO STOP RUN END-IF. //GO.SYSIN DD * 3 2 32888 129 -322 329 387273 0039 233 -282 36662 -33 972839 83992 X 392 0
Condition handler:
//RUNCOBOL EXEC IGYWCL,PARM.COBOL='LIB' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //COBOL.SYSLIB DD DISP=SHR,DSN=CEE.SCEESAMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP904HDL) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP904HDL ENVIRONMENT DIVISION. DATA DIVISION. LINKAGE SECTION. 01 TOKEN PIC S9(9) COMP. 01 RESULT PIC S9(9) COMP. 88 RESUME VALUE 10. 88 PERCOLATE VALUE 20. 88 PERCOLATE-SF VALUE 21. 88 PROMOTE VALUE 30. 88 PROMOTE-SF VALUE 31. 01 CONDITION. 02 CONDITION-TOKEN-VALUE. COPY CEEIGZCT. 03 CASE-1-CONDITION-ID. 04 SEVERITY PIC S9(4) COMP. 04 MSG-NO PIC S9(4) COMP. 03 CASE-2-CONDITION-ID REDEFINES CASE-1-CONDITION-ID. 04 CLASS-CODE PIC S9(4) COMP. 04 CAUSE-CODE PIC S9(4) COMP. 03 CASE-SEV-CTL PIC X. 03 FACILITY-ID PIC XXX. 02 I-S-INFO PIC S9(4) COMP. PROCEDURE DIVISION USING CONDITION TOKEN RESULT. MAIN-LOGIC. DISPLAY "COND HANDLER: ABEND CAUGHT". DISPLAY "COND HANDLER: ABEND ID: " FACILITY-ID MSG-NO. DISPLAY "COND HANDLER: PROGRAM TERMINATES". GOBACK.
Comments: - CEEHDLR and CEEHDLU are z/OS Language Environment services. You can see LE as a layer between z/OS system all the software that runs on it. Software written in all kinds of languages, COBOL, PL/1, Assembler, C++, etc. communicates with LE and uses LE services. - Thanks to CEEHDLR and CEEHDLU services we are able to respond to an abend. We can execute user-written sub-program or resume an abended program from a different point. Basically, we can recover our program from an abend. - The above program presents the simplest use of abend handling provided in LE. Actually, the abend isn't really handled here, it's just caught and information about it is written to the output. - There are three main variables needed by condition handler. TOKEN is an integer variable available for the use of a programmer. RESULT specifies what action will LE take in response to the abend. In this example, no action is taken so LE continues with standard abend handling. CONDITION is a structure that stores information about the encountered abend. - It's worth looking into PARM.GO parameter. Language Environment parameters can be passed to the program at execution time. Slash ('/') must proceed LE parameters, this way LE recognizes which parameters should be passed to the program and which are LE runtime options. - In this case, ERRCOUNT(5) was specified. Normally program terminates after the first abend, now 5 abends can occur before it terminates. - Notice 'COPY CEEIGZCT'. COPY statement is a compiler directive that works as JCL INCLUDE statement, in its place a content of CEEIGZCT member is substituted. The library with this member must be specified in COBOL.SYSLIB DD statement. Additionally 'LIB' parameter must be specified. - CEEIGZCT is optional. It's just a set of predefined values that can exist in 'FEEDBACK' structure. Thanks to it we could make tests like "IF NOT CEE000". The full list of codes available in this member and the related messages are available in "z/OS Language Environment Runtime Messages", check "Symbolic Feedback Code" phrase for those codes.
Solution 5
Main program:
//DELSTEP EXEC PGM=IEFBR14 //DELDD DD DSN=JSADEK.CUSTOMER.MP901.OUT, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //RUNCOBOL EXEC IGYWCLG,PARM.GO='/ERRCOUNT(0)' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //COBOL.SYSLIB DD DISP=SHR,DSN=CEE.SCEESAMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP905) //LKED.SYSIN DD DISP=SHR,DSN=JSADEK.MY.COBOL.LINKLIB(MP905HDL) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP905. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CUST-FILE ASSIGN TO INFILE ORGANIZATION IS INDEXED RECORD KEY IS CUST-ID ACCESS MODE IS DYNAMIC FILE STATUS IS CUST-STAT CUST-VSAMSTAT. SELECT OUT-FILE ASSIGN TO OUTFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS OUT-STAT. DATA DIVISION. FILE SECTION. FD CUST-FILE. 01 CUST-RECORD. 05 CUST-ID PIC 9(12). 05 CUST-BALANCE PIC -(8)9.99. 05 CUST-CURRENCY PIC X. FD OUT-FILE RECORDING MODE IS F. 01 OUT-RECORD. 05 OUT-ID PIC 9(12). 05 OUT-BALANCE PIC -(8)9.99. 05 OUT-CURRENCY PIC X. WORKING-STORAGE SECTION. 01 CUST-EOF PIC 9. 01 CUST-STAT PIC XX. 01 CUST-VSAMSTAT. 05 CUST-VSAMRC PIC 9(2) COMP. 05 CUST-VSAMFC PIC 9(2) COMP. 05 CUST-VSAMFB PIC 9(2) COMP. 01 OUT-STAT PIC XX. 77 TEMP-BALANCE PIC S9(8)V99 COMP. 01 CEEHDLR PIC X(8) VALUE "CEEHDLR". 01 CEEHDLU PIC X(8) VALUE "CEEHDLU". 01 CEE3SRP PIC X(8) VALUE "CEE3SRP". * CONDITION HANDLER VARIABLES 01 ROUTINE PROCEDURE-POINTER. 01 TOKEN PIC S9(9) COMP VALUE 0. 01 FEEDBACK. 02 CONDITION-TOKEN-VALUE. 03 CASE-1-CONDITION-ID. 04 SEVERITY PIC S9(4) COMP. 04 MSG-NO PIC S9(4) COMP. 03 CASE-2-CONDITION-ID REDEFINES CASE-1-CONDITION-ID. 04 CLASS-CODE PIC S9(4) COMP. 04 CAUSE-CODE PIC S9(4) COMP. 03 CASE-SEV-CTL PIC X. 03 FACILITY-ID PIC XXX. 02 I-S-INFO PIC S9(4) COMP. 01 RESUME-AREA EXTERNAL. 05 RESUME-POINT POINTER. 05 INVREC-ABEND PIC 9. 01 RESUME-SETUP PIC 9 VALUE 1. 01 INVREC-FLAG PIC 9 VALUE 0. PROCEDURE DIVISION. DECLARATIVES. CUST-FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON CUST-FILE. CUST-FILE-ERROR. DISPLAY "'INFILE' FILE ERROR OCCUREED:". DISPLAY "FILE STATUS: " CUST-STAT. DISPLAY "VSAM RETURN CODE : " CUST-VSAMRC. DISPLAY "VSAM FUNCTION CODE: " CUST-VSAMFC. DISPLAY "VSAM FEEDBACK CODE: " CUST-VSAMFB. DISPLAY "PROGRAM TERMINATES.". MOVE CUST-STAT TO RETURN-CODE. IF CUST-STAT NOT = "42" PERFORM CLOSE-FILES. STOP RUN. OUT-FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON OUT-FILE. OUT-FILE-ERROR. DISPLAY "'OUTFILE' FILE ERROR OCCUREED:". DISPLAY "FILE STATUS: " OUT-STAT. DISPLAY "PROGRAM TERMINATES.". MOVE OUT-STAT TO RETURN-CODE. IF CUST-STAT NOT = "42" PERFORM CLOSE-FILES. STOP RUN. END DECLARATIVES. MAIN-LOGIC SECTION. PERFORM OPEN-FILES. PERFORM REG-HANDLER. PERFORM CALCULATE-INTRESTS. PERFORM UNREG-HANDLER. PERFORM CLOSE-FILES. IF INVREC-FLAG = 1 MOVE 4 TO RETURN-CODE. STOP RUN. REG-HANDLER. SET ROUTINE TO ENTRY "MP905HDL". CALL CEEHDLR USING ROUTINE TOKEN FEEDBACK. IF FEEDBACK NOT = LOW-VALUES DISPLAY "CEEHDLR FAILED." DISPLAY "ERROR: " FACILITY-ID MSG-NO STOP RUN ELSE DISPLAY "CEEHDLR SUCCESSFUL." END-IF. UNREG-HANDLER. CALL CEEHDLU USING ROUTINE TOKEN FEEDBACK. IF FEEDBACK NOT = LOW-VALUES DISPLAY "CEEHDLU FAILED." DISPLAY "ERROR: " FACILITY-ID MSG-NO STOP RUN ELSE DISPLAY "CEEHDLU SUCCESSFUL." END-IF. CALCULATE-INTRESTS. PERFORM UNTIL CUST-EOF = 1 IF RESUME-SETUP = 0 PERFORM SAVE-UPDATED-RECORD ELSE CALL CEE3SRP USING RESUME-POINT FEEDBACK SERVICE LABEL PERFORM VERIFY-RESUME-POINT END-IF IF INVREC-ABEND = 1 DISPLAY "ERROR: '" CUST-RECORD "' RECORD IS INVALID AND WILL BE DISCARDED." MOVE 0 TO INVREC-ABEND MOVE 1 TO INVREC-FLAG END-IF READ CUST-FILE NEXT AT END MOVE 1 TO CUST-EOF END-READ END-PERFORM. SAVE-UPDATED-RECORD. MOVE CUST-RECORD TO OUT-RECORD. MOVE CUST-BALANCE TO TEMP-BALANCE. IF TEMP-BALANCE > 0 COMPUTE TEMP-BALANCE = TEMP-BALANCE * 1.025 MOVE TEMP-BALANCE TO OUT-BALANCE END-IF. WRITE OUT-RECORD. DISPLAY "RECORD: '" CUST-RECORD "' WRITTEN.". VERIFY-RESUME-POINT. IF RESUME-SETUP = 1 MOVE 0 TO RESUME-SETUP IF FEEDBACK = LOW-VALUES DISPLAY "RESUME POINT SET SUCCESSFULLY" ELSE DISPLAY "FAILED TO SET RESUME POINT" DISPLAY "ERROR: " FACILITY-ID MSG-NO STOP RUN END-IF END-IF. OPEN-FILES. MOVE 0 TO CUST-EOF. OPEN INPUT CUST-FILE. OPEN OUTPUT OUT-FILE. CLOSE-FILES. CLOSE CUST-FILE. CLOSE OUT-FILE. //GO.INFILE DD DISP=SHR,DSN=JSADEK.CUSTOMER.MP901 //GO.OUTFILE DD DSN=JSADEK.CUSTOMER.MP901.OUT,BLKSIZE=5000, // SPACE=(TRK,(1,1)),DISP=(NEW,CATLG),RECFM=FB,LRECL=25
Condition handler:
//RUNCOBOL EXEC IGYWCL //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP905HDL) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP905HDL ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 CEEMRCE PIC X(8) VALUE "CEEMRCE ". 01 MSG-NO-EDI PIC 9(4). 01 TEMP-MSG PIC X(7). 01 RESUME-AREA EXTERNAL. 05 RESUME-POINT POINTER. 05 INVREC-ABEND PIC 9. 01 FEEDBACK PIC X(12). LINKAGE SECTION. 01 TOKEN PIC S9(9) COMP. 01 RESULT PIC S9(9) COMP. 88 RESUME VALUE 10. 88 PERCOLATE VALUE 20. 88 PERCOLATE-SF VALUE 21. 88 PROMOTE VALUE 30. 88 PROMOTE-SF VALUE 31. 01 CONDITION. 02 CONDITION-TOKEN-VALUE. 03 CASE-1-CONDITION-ID. 04 SEVERITY PIC S9(4) COMP. 04 MSG-NO PIC S9(4) COMP. 03 CASE-2-CONDITION-ID REDEFINES CASE-1-CONDITION-ID. 04 CLASS-CODE PIC S9(4) COMP. 04 CAUSE-CODE PIC S9(4) COMP. 03 CASE-SEV-CTL PIC X. 03 FACILITY-ID PIC XXX. 02 I-S-INFO PIC S9(4) COMP. PROCEDURE DIVISION USING CONDITION TOKEN RESULT. MAIN-LOGIC. MOVE MSG-NO TO MSG-NO-EDI. STRING FACILITY-ID DELIMITED BY SIZE MSG-NO-EDI DELIMITED BY SIZE INTO TEMP-MSG. IF TEMP-MSG = "IGZ0063" MOVE 1 TO INVREC-ABEND PERFORM RESUME-FLOW ELSE DISPLAY "COND HANDLER: " FACILITY-ID MSG-NO " ABEND CAUGHT. PROGRAM TERMINATES." SET PERCOLATE TO TRUE END-IF. GOBACK. RESUME-FLOW. DISPLAY "COND HANDLER: " FACILITY-ID MSG-NO " ABEND CAUGHT. TRYING TO RESUME.". CALL CEEMRCE USING RESUME-POINT FEEDBACK. IF FEEDBACK = LOW-VALUES DISPLAY "COND HANDLER: PROGRAM RESUMED TO: " RESUME-POINT " BLOCK." SET RESUME TO TRUE ELSE DISPLAY "COND HANDLER: PROGRAM RESUME UNSUCCESSFUL." END-IF.
Output:
CEEHDLR SUCCESSFUL. RESUME POINT SET SUCCESSFULLY RECORD: '000000000001 -3214.51$' WRITTEN. RECORD: '000000000002 32444211.29$' WRITTEN. RECORD: '000000000007 -11192.32$' WRITTEN. RECORD: '000000000011 -134.11$' WRITTEN. RECORD: '000000000012 -3922.39$' WRITTEN. RECORD: '000000000031 8172.11$' WRITTEN. RECORD: '000000000073 28371991.39$' WRITTEN. COND HANDLER: IGZ0063 ABEND CAUGHT. TRYING TO RESUME. COND HANDLER: PROGRAM RESUMED TO: 0511279520 BLOCK. ERROR: '000000000099 DUPA82.11$' RECORD IS INVALID AND WILL BE DISCARDED. RECORD: '000000000422 1291391.11$' WRITTEN. RECORD: '000000021212 -1000.00$' WRITTEN. CEEHDLU SUCCESSFUL.
Comments: - If you want to resume program from a specific point, you need to use CEE3SRP and CEEMRCE services. - First you must setup resume point with CEE3SRP and SERVICE LABEL directive. FEEDBACK stores output from this service so you can use it to see if it executed correctly. RESUME-POINT variable stores an address from which execution flow will be resumed in case of abend. It must be passed to condition handler, therefore EXTERNAL keyword is used here. - INVREC-ABEND is not part of CEE3SRP service, it's an additional variable that enables us to inform user about invalid record. - In condition handler MP906HDL, CEEMRCE service is used to set up execution flow back to the value stored in RESUME-POINT variable. Next RESUME variable must be set to '10' which indicates that resume operation. After GOBACK instruction, the main program will start executing from RESUME-POINT. - Percolate means that Condition Handler is not prepared for the particular abend and it should be handled normally. In this example, we perform recovery action only in case of IGZ0063 abend. - Since you usually test only for CEE000 you can skip 'COPY CEEIGZCT' and instead test for LOW-VALUES. - ERRCOUNT defines number of unhandled abend allowed in the program (0 by default). If the program is RESUMED after the abend it isn't considered as an abend by this option (ERRCOUNT is not incremented). Important: - After control is returned to the resume point, the program "forgets" about the main execution flow. In the above example, running CEE3SRP from inside VERIFY-RESUME-POINT would result in control getting back to VERIFY-RESUME-POINT paragraph but then it won't come back to the file processing loop. Instead, the next paragraph, OPEN-FILES, will be executed.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP906. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 LGT PIC S9(4) COMP. 77 LGT-EDI PIC -(3)9. 77 LGT-MODE PIC X(7) VALUE "TRIMLGT". 77 ULENGTH PIC X(8) VALUE "ULENGTH". 77 INDATA PIC X(80). 77 TEMP-STR PIC X(1000). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM CHECK-THE-LENGTH. STOP RUN. CHECK-THE-LENGTH. PERFORM ACCEPT-INPUT. PERFORM UNTIL INDATA = LOW-VALUES MOVE INDATA TO TEMP-STR CALL ULENGTH USING TEMP-STR LGT-MODE RETURNING LGT ON EXCEPTION PERFORM ULENGTH-EXCP END-CALL MOVE LGT TO LGT-EDI DISPLAY "LENGTH: " LGT-EDI ", DATA: " INDATA PERFORM ACCEPT-INPUT END-PERFORM. ACCEPT-INPUT. MOVE LOW-VALUES TO INDATA. ACCEPT INDATA. ULENGTH-EXCP. DISPLAY "CONTROL COULDN'T BE PASSED TO 'ULENGTH'.". MOVE 12 TO RETURN-CODE. STOP RUN.
Comments: - Unfortunately ON EXCEPTION cannot be used for checking for errors or abends in the called program. It has only one use, to check if the control is correctly passed to the called program. Which in most cases means that it simply checks if the program is found. - So the main use of this clause is to check if the invoked program is found. It may be useful in a situation in which the called program is not critical to the main program functionality and you don't want to abend it because of the failed CALL instruction.
Standard functions
Introduction
There are two types of functions in COBOL. Standard functions which are part of the language for years and years, such as MOVE, STRING, INSPECT, DISPLAY etc. And Intrinsic functions which are a "newer" addition to COBOL language and which are much more similar to functions from other programming languages like C++ or Java. In this assignment, we'll focus on standard functions which were not fully covered in other Assignments. Also, SORT & MERGE functions are skipped here because they'll be covered in later Assignment.
Tasks
![]() 1. Write a program that accepts any type of data as an input and:
- If the data is numeric, it displays it in (-)999 999 999.999 format.
- If the data is alphabetic, it is converted to upper-case and displayed.
1. Write a program that accepts any type of data as an input and:
- If the data is numeric, it displays it in (-)999 999 999.999 format.
- If the data is alphabetic, it is converted to upper-case and displayed.
![]() 2. Write a program that uses COMPUTE statement to perform multiplication and division operation. Use ON SIZE ERROR clause and test program in following conditions:
- Dividing by zero.
- Data overflow.
- One number is a character 'X'.
2. Write a program that uses COMPUTE statement to perform multiplication and division operation. Use ON SIZE ERROR clause and test program in following conditions:
- Dividing by zero.
- Data overflow.
- One number is a character 'X'.
![]() 3. Write a program that:
- Accepts from input 0 to 10 numbers and saves them in the array.
- Displays the entire table but with use of a pointer, not a subscript.
3. Write a program that:
- Accepts from input 0 to 10 numbers and saves them in the array.
- Displays the entire table but with use of a pointer, not a subscript.
![]() 4. Modify program from Task#3:
- Now it should execute a sub-program ENTRYTST which accepts three arguments: Table pointer, Table size, Multiplier.
- First, ENTRYTST multiplies each value in the table by the multiplier.
- Next, it displays multiplied table.
- At last, it sums up all values and displays the sum.
- Use ENTRY statement to code an alternative entry point. Running the program from this entry point should skip table multiplication and display so only the sum is calculated.
- CALL ENTRYTST from the beginning and from an alternative entry point.
4. Modify program from Task#3:
- Now it should execute a sub-program ENTRYTST which accepts three arguments: Table pointer, Table size, Multiplier.
- First, ENTRYTST multiplies each value in the table by the multiplier.
- Next, it displays multiplied table.
- At last, it sums up all values and displays the sum.
- Use ENTRY statement to code an alternative entry point. Running the program from this entry point should skip table multiplication and display so only the sum is calculated.
- CALL ENTRYTST from the beginning and from an alternative entry point.
![]() 5. Define a structure with FILLERs, NUMERIC, BINARY, NUMERIC-EDITED, ALPHANUMERIC, NATIONAL and DBCS fields:
- Display the entire uninitialized structure.
- Use INITIALIZE function to initialize the structure with default values and display the structure again.
- Use INITIALIZE again, this time with FILLER option and display the structure again.
- Use INITIALIZE again, this time with REPLACING/DATA BY option and display the structure again.
5. Define a structure with FILLERs, NUMERIC, BINARY, NUMERIC-EDITED, ALPHANUMERIC, NATIONAL and DBCS fields:
- Display the entire uninitialized structure.
- Use INITIALIZE function to initialize the structure with default values and display the structure again.
- Use INITIALIZE again, this time with FILLER option and display the structure again.
- Use INITIALIZE again, this time with REPLACING/DATA BY option and display the structure again.
![]() 6. Perform following INSPECT function actions on the ""Whether you think you can, or you think you can't - you're right" - Henry Ford (1863.07.30 - 1947.04.07)" string:
- Calculate the length of the entire string.
- Calculate the length of the string inside quotes. Assume you don't know the contents of the string, only that quotes ("") are there.
- Count how many non-space characters are in the string.
- Replace double-quotes with single-quotes and "." with "/".
- Convert lower-case letters to upper-case letters.
- Replace all numbers with 'X' counting how many numbers were replaced.
6. Perform following INSPECT function actions on the ""Whether you think you can, or you think you can't - you're right" - Henry Ford (1863.07.30 - 1947.04.07)" string:
- Calculate the length of the entire string.
- Calculate the length of the string inside quotes. Assume you don't know the contents of the string, only that quotes ("") are there.
- Count how many non-space characters are in the string.
- Replace double-quotes with single-quotes and "." with "/".
- Convert lower-case letters to upper-case letters.
- Replace all numbers with 'X' counting how many numbers were replaced.
![]() 7. Perform following STRING function actions on "Whether you think you can", ", or you think you can't", and " - you're right." strings:
- Join three string into one.
- Join string multiple times to cause overflow condition twice. Once with coded ON EXCEPTION clause and once without it. What's the difference?
- Use STRING/POINTER, and OCCURS/TIMES/DEPENDING clauses to join all those strings into one and save its length so only the data is displayed, not the entire variable.
7. Perform following STRING function actions on "Whether you think you can", ", or you think you can't", and " - you're right." strings:
- Join three string into one.
- Join string multiple times to cause overflow condition twice. Once with coded ON EXCEPTION clause and once without it. What's the difference?
- Use STRING/POINTER, and OCCURS/TIMES/DEPENDING clauses to join all those strings into one and save its length so only the data is displayed, not the entire variable.
![]() 8. Perform following UNSTRING function actions on "Whether you think you can, or you think you can't - you're right." string:
- Split the string into sub-strings defined by ',' and '-' characters.
- Cause overflow condition in two cases. With ON OVERFLOW clause coded and without it.
- Next, define two tables, one that will store each word in the above string, and one that stores the length of the words in the first table. Use UNSTRING function to split the input string into separate words, and populate both tables.
8. Perform following UNSTRING function actions on "Whether you think you can, or you think you can't - you're right." string:
- Split the string into sub-strings defined by ',' and '-' characters.
- Cause overflow condition in two cases. With ON OVERFLOW clause coded and without it.
- Next, define two tables, one that will store each word in the above string, and one that stores the length of the words in the first table. Use UNSTRING function to split the input string into separate words, and populate both tables.
![]() 9. Use ACCEPT statement to get following data:
- Current data.
- Current time.
- Day of the year.
- Day of the current week.
- Next, display the date in YYYY-MM-DD format and time in HH:MM:SS.III format where 'I' means milliseconds.
9. Use ACCEPT statement to get following data:
- Current data.
- Current time.
- Day of the year.
- Day of the current week.
- Next, display the date in YYYY-MM-DD format and time in HH:MM:SS.III format where 'I' means milliseconds.
![]() 10. Define a ten element table with three fields: Transaction ID, Purchase date, and Transaction Amount.
- Populate the table with test data. Transactions are written in purchase date order so Transaction ID and Purchase Date fields should be in ascending order.
- Perform serial search and use subscript during the search.
- Search for the transaction with a specific ID.
- Next, search for the first transaction larger than 10 dollars after a specific date.
- Next, search for the last transaction in a given day.
10. Define a ten element table with three fields: Transaction ID, Purchase date, and Transaction Amount.
- Populate the table with test data. Transactions are written in purchase date order so Transaction ID and Purchase Date fields should be in ascending order.
- Perform serial search and use subscript during the search.
- Search for the transaction with a specific ID.
- Next, search for the first transaction larger than 10 dollars after a specific date.
- Next, search for the last transaction in a given day.
![]() 11. Modify program from Task#10:
- Perform the binary search.
- Search for the transaction with a specific ID.
- Try to search for the transaction done at a specific timestamp. What's the problem here?
11. Modify program from Task#10:
- Perform the binary search.
- Search for the transaction with a specific ID.
- Try to search for the transaction done at a specific timestamp. What's the problem here?
Hint 3
You cannot access the data area reference by the pointer directly. Rather, you must define an appropriate variable in LINKAGE section and then set its address to the pointer value.
Solution 1
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1001. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 INDATA PIC X(80). 77 TEMP-NUM-TEST PIC X(80). 77 NUM-COMP PIC S9(15)V9(3). 77 NUM-EDI PIC -(3)B-(3)B-(3)B-(3)B-(2)9.9(3). 77 T1 PIC 9(4) COMP. 77 T2 PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM CHECK-THE-LENGTH. STOP RUN. CHECK-THE-LENGTH. PERFORM ACCEPT-INPUT. PERFORM UNTIL INDATA = LOW-VALUES PERFORM NUM-TEST EVALUATE TRUE WHEN TEMP-NUM-TEST IS NUMERIC PERFORM NUMERIC-ACTION WHEN INDATA IS ALPHABETIC-UPPER PERFORM UPPER-CASE-ACTION WHEN INDATA IS ALPHABETIC-LOWER PERFORM LOWER-CASE-ACTION WHEN OTHER PERFORM MIXED-CASE-ACTION END-EVALUATE PERFORM ACCEPT-INPUT END-PERFORM. NUMERIC-ACTION. COMPUTE NUM-COMP = FUNCTION NUMVAL(INDATA). MOVE NUM-COMP TO NUM-EDI. DISPLAY "CONVERTED TO A DESIRED NUMBER FORMATTING:" DISPLAY ">>>" NUM-EDI "<<<". UPPER-CASE-ACTION. DISPLAY "ALREADY IN UPPER-CASE. NO ACTION TAKEN:". DISPLAY ">>>" INDATA "<<<". LOWER-CASE-ACTION. MOVE FUNCTION UPPER-CASE(INDATA) TO INDATA. DISPLAY "CONVERTED FROM LOWER TO UPPER CASE:". DISPLAY ">>>" INDATA "<<<". MIXED-CASE-ACTION. MOVE FUNCTION UPPER-CASE(INDATA) TO INDATA. DISPLAY "CONVERTED FROM MIXED TO UPPER CASE:". DISPLAY ">>>" INDATA "<<<". NUM-TEST. MOVE 0 TO T1 T2. MOVE INDATA TO TEMP-NUM-TEST. INSPECT TEMP-NUM-TEST TALLYING T1 FOR ALL "." REPLACING ALL "." BY ZEROS. INSPECT TEMP-NUM-TEST TALLYING T2 FOR ALL "-" REPLACING ALL "-" BY ZEROS. IF T1 < 2 AND T2 < 2 PERFORM CHECK-NUM-LENGTH INSPECT TEMP-NUM-TEST REPLACING ALL SPACES BY ZEROS IF T1 > 18 AND TEMP-NUM-TEST IS NUMERIC DISPLAY "ERROR: NUMERIC '" INDATA(1 : T1) "' HAS MORE THA - "HAN 18 CHARACTERS AND WILL BE TREATED AS A STRING." MOVE INDATA TO TEMP-NUM-TEST END-IF END-IF. CHECK-NUM-LENGTH. MOVE 0 TO T1. INSPECT FUNCTION REVERSE(TEMP-NUM-TEST) TALLYING T1 FOR LEADING SPACES. COMPUTE T1 = LENGTH OF TEMP-NUM-TEST - T1. ACCEPT-INPUT. MOVE LOW-VALUES TO INDATA. ACCEPT INDATA. //GO.SYSIN DD * 32.1 some lower letter stuff SOME UPPER LETTER STUFF some lower-letter stuff??? 9382717 9392233101019328823.232 -1833.22 OmG iT's CoBoL!!!
Output:
CONVERTED TO A DESIRED NUMBER FORMATTING: >>> 32.100<<< CONVERTED FROM LOWER TO UPPER CASE: >>> SOME LOWER LETTER STUFF <<< ALREADY IN UPPER-CASE. NO ACTION TAKEN: >>> SOME UPPER LETTER STUFF <<< CONVERTED FROM MIXED TO UPPER CASE: >>> SOME LOWER-LETTER STUFF??? <<< CONVERTED TO A DESIRED NUMBER FORMATTING: >>> 9 382 717.000<<< ERROR: NUMERIC ' 9392233101019328823.232' HAS MORE THAHAN 18 CHARACTERS AND WILL BE TREATED AS A STRING. CONVERTED FROM MIXED TO UPPER CASE: >>> 9392233101019328823.232 <<< CONVERTED TO A DESIRED NUMBER FORMATTING: >>> -1 833.220<<< CONVERTED FROM MIXED TO UPPER CASE: >>> OMG IT'S COBOL!!! <<<
Comments: - This task presents how you can test what data is stored in an alphanumeric item. IS NUMERIC/ALPHABETIC/ALPHABETIC-UPPER/ALPHABETIC-LOWER/DBCS/KENJII functions can be used here. - Still, all those options have their limitations. For example, DBCS will recognize "-1833.22" item as DBCS. This isn't an error, the hexadecimal representation of this number is a correct for DBCS string. You should be aware that when testing for DBCS data the tested variable may be "misinterpreted" that way. - Also, IS NUMERIC function is problematic. It works fine only for the NUMERIC data type, while most often we need to test if alphanumeric data contains a number. If the string contains any character other than 0-9, even '.' or space the data is recognized as non-numeric. That's why NUM-TEST paragraph is coded. It makes more tests to recognize if the data is indeed numeric or not. - When it comes to NUMVAL intrinsic function, it correctly reads '-' and '.', but it will abend if given numeric larger than 18 digits. That's why an additional test is for data length is coded in NUM-TEST paragraph. - UPPER and LOWER-CASE functions work somewhat better but you should also get familiar with them. For example, '-' character is not recognized as alphabetic so if a string contains '-' or other special characters the entire string is not recognized as either upper or lower case.
Solution 2
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1002. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 A-STRUCT. 05 A PIC 999V99. 01 B PIC 999V99. 01 C PIC 999V99. 01 A-EDI PIC -(3)9.99. 01 B-EDI PIC -(3)9.99. 01 C-EDI PIC -(3)9.99. PROCEDURE DIVISION. MAIN-LOGIC. MOVE 232.2 TO A. MOVE 12.5 TO B. PERFORM COMPUTE-STUFF. MOVE 32.2 TO A. MOVE 0 TO B. PERFORM COMPUTE-STUFF. MOVE 700 TO A. MOVE 42 TO B. PERFORM COMPUTE-STUFF. MOVE "X" TO A-STRUCT. MOVE 42 TO B. PERFORM COMPUTE-STUFF. STOP RUN. COMPUTE-STUFF. COMPUTE C = A * B ON SIZE ERROR PERFORM ERROR-MULTI-MSG NOT ON SIZE ERROR PERFORM CORRECT-MULTI-MSG. COMPUTE C = A / B ON SIZE ERROR PERFORM ERROR-DIV-MSG NOT ON SIZE ERROR PERFORM CORRECT-DIV-MSG. ERROR-MULTI-MSG. MOVE A TO A-EDI. MOVE B TO B-EDI. MOVE C TO C-EDI. DISPLAY A-EDI " * " B-EDI " = ERROR". ERROR-DIV-MSG. MOVE A TO A-EDI. MOVE B TO B-EDI. MOVE C TO C-EDI. DISPLAY A-EDI " / " B-EDI " = ERROR". CORRECT-MULTI-MSG. MOVE A TO A-EDI. MOVE B TO B-EDI. MOVE C TO C-EDI. DISPLAY A-EDI " * " B-EDI " = " C-EDI. CORRECT-DIV-MSG. MOVE A TO A-EDI. MOVE B TO B-EDI. MOVE C TO C-EDI. DISPLAY A-EDI " / " B-EDI " = " C-EDI.
Output:
232.20 * 12.50 = ERROR 232.20 / 12.50 = 18.57 32.20 * 0.00 = 0.00 32.20 / 0.00 = ERROR 700.00 * 42.00 = ERROR 700.00 / 42.00 = 16.66 700.00 * 42.00 = ERROR CEE3207S The system detected a data exception (System Completion Code=0C7).
Comments: - ON SIZE ERROR is a very useful COMPUTE option. But you cannot depend on it in case of all errors. ON SIZE ERRORS catches three types of error: overflow, division by zero, and exponent related errors. It won't catch an error when multiplying "X" character by 42. "X" is recognized as 700 during multiplication operation but causes an abend during division operation. - Instead of COMPUTE you can use ADD, SUBTRACT, MULTIPLY, and DIVIDE functions but COMPUTE allows much more flexibility, and you can always use it in place of the above functions. - Also, remember about the ROUNDED keyword. It wasn't needed in this Task but when working on decimal numbers we usually prefer the result to be rounder rather than trimmed.
Solution 3
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1003. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 TAB-SIZE PIC 9(2) VALUE 0. 77 K1 PIC 9(4) COMP. 77 INDATA PIC X(10). 77 TEMP-NUM PIC S9(6)V99. 77 TAB-PTR POINTER. 77 TAB-PTR-CALC REDEFINES TAB-PTR PIC S9(9) COMP. 01 NUM-TAB. 05 NUM OCCURS 0 TO 10 TIMES DEPENDING ON TAB-SIZE PIC -(6)9.99. LINKAGE SECTION. 77 TEMP-NUM-PTR PIC -(6)9.99. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-NUM-TAB. PERFORM DISPLAY-THE-TABLE. STOP RUN. ACCEPT-NUM-TAB. PERFORM ACCEPT-INPUT. PERFORM UNTIL INDATA = LOW-VALUES ADD 1 TO TAB-SIZE COMPUTE TEMP-NUM = FUNCTION NUMVAL(INDATA) MOVE TEMP-NUM TO NUM(TAB-SIZE) PERFORM ACCEPT-INPUT END-PERFORM. ACCEPT-INPUT. MOVE LOW-VALUES TO INDATA. ACCEPT INDATA. DISPLAY-THE-TABLE. DISPLAY ">" NUM-TAB "<". SET TAB-PTR TO ADDRESS OF NUM-TAB. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > TAB-SIZE SET ADDRESS OF TEMP-NUM-PTR TO TAB-PTR DISPLAY "ITEM " K1 ": " TEMP-NUM-PTR ADD 10 TO TAB-PTR-CALC END-PERFORM.
Comments: - This small program presents how pointers can be used in COBOL. - TAB-PTR pointer is used during data display. We move it by 10 bytes so with each iteration it points to the subsequent table element. - Unfortunately, COMPUTE, MOVE or ADD statements does not work on pointers, and SET statement doesn't provide any way to add a particular value to the pointer. In the above example, we could simply SET it to the address of the next table element "SET TAB-PTR-TEMP TO ADDRESS OF NUM(K1)" but that's too easy, and in this Task, we aren't supposed to use subscript. - Instead, a workaround of this limitations is presented. You can use REDEFINES clause to make pointer recognized as an integer (pointers are 4 byte long binary data so PIC S9(9) COMP). Now we can do whatever we want with this pointer. Of course, now you must be especially careful not to access storage areas outside of variables you're working on. - To access the data pointed out by the pointer you must define an appropriate variable in LINKAGE SECTION and set its address to the one stored in the pointer. That's the purpose of TEMP-NUM-PTR variable.
Solution 4
Main program:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1004. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 TAB-SIZE PIC 9(2) COMP VALUE 0. 77 K1 PIC 9(4) COMP. 77 INDATA PIC X(10). 77 TEMP-NUM PIC S9(6)V99. 01 NUM-TAB. 05 NUM OCCURS 0 TO 10 TIMES DEPENDING ON TAB-SIZE PIC -(6)9.99. 77 TAB-START-PTR POINTER. 77 MULTIPLIER PIC S99V99 COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-NUM-TAB. PERFORM CALL-FROM-ENTRY-POINT. PERFORM CALL-FROM-START. PERFORM CALL-FROM-ENTRY-POINT. STOP RUN. CALL-FROM-START. DISPLAY "****** STANDARD CALL ******". MOVE 1.2 TO MULTIPLIER. SET TAB-START-PTR TO ADDRESS OF NUM-TAB. CALL "ENTRYTST" USING TAB-START-PTR TAB-SIZE MULTIPLIER ON EXCEPTION PERFORM ENTRYTST-NOT-FOUND. CALL-FROM-ENTRY-POINT. DISPLAY "****** CALL FROM ENTRY POINT ******". SET TAB-START-PTR TO ADDRESS OF NUM-TAB. CALL "ENTRYSUM" USING TAB-START-PTR TAB-SIZE ON EXCEPTION PERFORM ENTRYTST-NOT-FOUND. ACCEPT-NUM-TAB. PERFORM ACCEPT-INPUT. PERFORM UNTIL INDATA = LOW-VALUES ADD 1 TO TAB-SIZE COMPUTE TEMP-NUM = FUNCTION NUMVAL(INDATA) MOVE TEMP-NUM TO NUM(TAB-SIZE) PERFORM ACCEPT-INPUT END-PERFORM. ACCEPT-INPUT. MOVE LOW-VALUES TO INDATA. ACCEPT INDATA. ENTRYTST-NOT-FOUND. DISPLAY "CONTROL COULDN'T BE PASSED TO 'ENTRYTST'.". DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. STOP RUN.
ENTRYTST program:
IDENTIFICATION DIVISION. PROGRAM-ID. ENTRYTST. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 TAB-PTR POINTER. 77 TAB-PTR-CALC REDEFINES TAB-PTR PIC 9(9) COMP. 77 K1 PIC 9(4) COMP. 77 COMP-NUM PIC S9(6)V99. 77 TAB-SUM PIC S9(7)V99. 77 TAB-SUM-EDI PIC -(7)9.99. LINKAGE SECTION. 77 TAB-START-PTR POINTER. 77 TAB-SIZE PIC 9(2) COMP. 77 MULTIPLIER PIC S99V99 COMP. 77 TEMP-NUM PIC -(6)9.99. PROCEDURE DIVISION USING TAB-START-PTR TAB-SIZE MULTIPLIER. MAIN-LOGIC. PERFORM MULTIPLY-THE-TABLE. PERFORM DISPLAY-THE-TABLE. ENTRY "ENTRYSUM" USING TAB-START-PTR TAB-SIZE. PERFORM SUM-THE-TABLE. GOBACK. MULTIPLY-THE-TABLE. SET TAB-PTR TO TAB-START-PTR. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > TAB-SIZE SET ADDRESS OF TEMP-NUM TO TAB-PTR MOVE TEMP-NUM TO COMP-NUM COMPUTE COMP-NUM = COMP-NUM * MULTIPLIER MOVE COMP-NUM TO TEMP-NUM ADD 10 TO TAB-PTR-CALC END-PERFORM. DISPLAY-THE-TABLE. DISPLAY "**** TABLE AFTER MULTIPLICATION ****". SET TAB-PTR TO TAB-START-PTR. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > TAB-SIZE SET ADDRESS OF TEMP-NUM TO TAB-PTR DISPLAY "ITEM " K1 ": " TEMP-NUM ADD 10 TO TAB-PTR-CALC END-PERFORM. SUM-THE-TABLE. DISPLAY "**** SUMMED TABLE ****". SET TAB-PTR TO TAB-START-PTR. MOVE 0 TO TAB-SUM. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > TAB-SIZE SET ADDRESS OF TEMP-NUM TO TAB-PTR MOVE TEMP-NUM TO COMP-NUM COMPUTE TAB-SUM = TAB-SUM + COMP-NUM ADD 10 TO TAB-PTR-CALC END-PERFORM. MOVE TAB-SUM TO TAB-SUM-EDI. DISPLAY "SUM: " TAB-SUM-EDI.
Output:
****** CALL FROM ENTRY POINT ****** **** SUMMED TABLE **** SUM: -24621.88 ****** STANDARD CALL ****** **** TABLE AFTER MULTIPLICATION **** ITEM 0001: -74786.55 ITEM 0002: 4713.60 ITEM 0003: 39332.40 ITEM 0004: -1.20 ITEM 0005: 28.02 ITEM 0006: 1167.48 **** SUMMED TABLE **** SUM: -29546.25 ****** CALL FROM ENTRY POINT ****** **** SUMMED TABLE **** SUM: -29546.25
Comments: - ENTRY point is simply an alternative start for a called program. When you execute sub-program from entry point the execution starts from the instruction following ENTRY statement. - ENTRY points are rarely used for one simple reason, you can select subprogram mode with conditional expressions and pass the mode as an argument. This is simpler and recommended approach for coding modules with many run modes. - Additional limitation of ENTRY points is that program that uses them cannot return value (cannot use RETURNING clause) which additionally limits your flexibility. - Still, you should remember about ENTRY statement. It may be useful for error or abend handling. You can use it with CEE3SRP and CEEMRCE for more complex abend handling.
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1005. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 RANDOM-STRUCT. 05 S-ALPHA PIC X(10). 05 FILLER PIC X VALUE "/". 05 S-NUM PIC 9(4). 05 FILLER PIC X VALUE "/". 05 S-NUM-COMP PIC 9(4) COMP. 05 FILLER PIC X VALUE "/". 05 S-NUM-EDI PIC -(3)9.99. 05 FILLER PIC X VALUE "/". 05 S-DBCS PIC G(6) DISPLAY-1. 05 FILLER PIC X VALUE "/". 05 S-NATIONAL PIC N(6). PROCEDURE DIVISION. MAIN-LOGIC. DISPLAY ">>" RANDOM-STRUCT "<<". INITIALIZE RANDOM-STRUCT. DISPLAY ">>" RANDOM-STRUCT "<<". * FILLER OPTION AVAILABLE SINCE ENT. COBOL 6.1 * INITIALIZE RANDOM-STRUCT WITH FILLER. * DISPLAY ">>" RANDOM-STRUCT "<<". INITIALIZE RANDOM-STRUCT REPLACING ALPHANUMERIC DATA BY "__" NUMERIC-EDITED DATA BY "9999" NATIONAL DATA BY LOW-VALUES. DISPLAY ">>" RANDOM-STRUCT "<<". STOP RUN.
Output with HEX ON:
>> / / / / / << 66000000000060000600600000006000000000000600000000000044 EE0000000000100001001000000010000000000001000000000000CC -------------------------------------------------------- >> /0000/ / 0.00/ / << 6644444444446FFFF6006444F4FF6444444444444602020202020244 EE00000000001000010010000B0010000000000001000000000000CC -------------------------------------------------------- >>__ /0000/ / 999.00/ / << 6666444444446FFFF60064FFF4FF6444444444444600000000000044 EEDD000000001000010010999B0010000000000001000000000000CC
Comments: - INITIALIZE is basically a set of MOVE statements so the standard rules for copying data also apply here. With it, you can easily initialize specific fields or entire structures/arrays to their default values. - As you can see, uninitialized fields of all types have LOW-VALUES (X'00') by default. But after initialization, they're filled with appropriate data depending on the data type as shown in the output. Using MOVE statement for the same task would take much more time.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1006. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 HF-QUOTE PIC X(200). 77 T1 PIC 9(4). 77 T2 PIC 9(4). 77 LOWER-CASE PIC X(26) VALUE "abcdefghijklmnopqrstuvwxyz". 77 UPPER-CASE PIC X(26) VALUE "ABCDEFGHIJKLMNOPQRSTUVWXYZ". PROCEDURE DIVISION. MAIN-LOGIC. MOVE """Whether you think you can, or you think you can't - y - "ou're right"" - Henry Ford (1863.07.30 - 1947.04.07)" TO HF-QUOTE. DISPLAY "Quote: " HF-QUOTE. MOVE 0 TO T1. INSPECT FUNCTION REVERSE(HF-QUOTE) TALLYING T1 FOR LEADING SPACES. COMPUTE T1 = LENGTH OF HF-QUOTE - T1. DISPLAY "String length: " T1. MOVE 0 TO T1 T2. INSPECT HF-QUOTE TALLYING T1 FOR CHARACTERS BEFORE """". INSPECT FUNCTION REVERSE(HF-QUOTE) TALLYING T2 FOR CHARACTERS BEFORE """". COMPUTE T1 = LENGTH OF HF-QUOTE - T1 - T2 - 2. DISPLAY "Quote length: " T1. MOVE 0 TO T1. INSPECT HF-QUOTE TALLYING T1 FOR ALL SPACES. COMPUTE T1 = LENGTH OF HF-QUOTE - T1. DISPLAY "Non-space characters: " T1. INSPECT HF-QUOTE REPLACING ALL """" BY "'" ALL "." BY "/". DISPLAY "Modified quote: " HF-QUOTE. INSPECT HF-QUOTE CONVERTING LOWER-CASE TO UPPER-CASE. DISPLAY "Upper-case quote: " HF-QUOTE. MOVE 0 TO T1. INSPECT HF-QUOTE TALLYING T1 FOR ALL "0" "1" "2" "3" "4" "5" "6" "7" "8" "9" REPLACING ALL "0" BY "X" "1" BY "X" "2" BY "X" "3" BY "X" "4" BY "X" "5" BY "X" "6" BY "X" "7" BY "X" "8" BY "X" "9" BY "X". DISPLAY "Quote with hidden numbers: " HF-QUOTE. DISPLAY "Numbers hidden: " T1. STOP RUN.
Comments: - INSPECT function gives you a lot of string manipulation possibilities, therefore it's often used and you should be familiar with all its possible applications. - You should remember to always initialize variable used for TALLYING before executing INSPECT. It's not done automatically and without it, you'll get unpredictable but predictably wrong results. - Converting the lower to the upper-case letter was a common use of INSPECT in the old days. So it's good to know how to do that but nowadays there is an intrinsic function for that named UPPER-CASE.
Solution 7
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1007. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 STR1 PIC X(40). 77 STR2 PIC X(40). 77 STR3 PIC X(40). 77 OUTSTR PIC X(120). 77 PTR PIC 9(4). 01 VARSTR-LEN PIC 9(4) COMP. 01 VARSTR. 05 VARSTR-DATA OCCURS 1 TO 500 TIMES DEPENDING ON VARSTR-LEN PIC X. PROCEDURE DIVISION. MAIN-LOGIC. MOVE "Whether you think you can" TO STR1. MOVE ", or you think you can't" TO STR2. MOVE " - you're right." TO STR3. PERFORM SIMPLE-JOIN. PERFORM EXCEPTION-TEST. PERFORM VARIABLE-LENGTH-STRING. STOP RUN. SIMPLE-JOIN. INITIALIZE OUTSTR. STRING STR1 STR2 STR3 DELIMITED BY " " INTO OUTSTR. DISPLAY "Joined strings >>>" OUTSTR "<<<". EXCEPTION-TEST. INITIALIZE OUTSTR. STRING STR1 STR2 STR3 "////" STR1 STR2 STR3 DELIMITED BY " " INTO OUTSTR. DISPLAY "Overflow not checked >>>" OUTSTR "<<<". INITIALIZE OUTSTR. STRING STR1 STR2 STR3 "////" STR1 STR2 STR3 DELIMITED BY " " INTO OUTSTR ON OVERFLOW PERFORM STRING-OVERFLOW. DISPLAY "Overflow checked >>>" OUTSTR "<<<". VARIABLE-LENGTH-STRING. MOVE 500 TO VARSTR-LEN. MOVE SPACES TO VARSTR. MOVE 1 TO PTR. STRING STR1 STR2 STR3 DELIMITED BY " " INTO VARSTR POINTER PTR ON OVERFLOW PERFORM STRING-OVERFLOW. COMPUTE VARSTR-LEN = PTR - 1. DISPLAY "Data only >>>" VARSTR "<<<". STRING-OVERFLOW. DISPLAY "Overflow occured".
Comments: - Using DELIMITED BY SIZE will result with in joining the entire string, including all trailing spaces. If you want to join the data without blanks at the end, you can delimit string by a few spaces like in the first STRING statement here. - Unlike MOVE, STRING statement does not initialize the string, so if it's not initialized it will have LOW-VALUES at the end even if after STRING statement. You should remember about that when testing for SPACES or LOW-VALUES. - The output of STRING function stays modified even if overflow occurs. If you want to clear it instead of having incomplete results in case of overflow, you must take care of it manually. - The last string statement presents how you can work with variable-length strings. You may want such structure to display only the data inside the string, without the trailing blanks. To realize that you need a structure like VARSTR, then you can use STRING/POINTER (or INSPECT) statement to detect the end of the data and save it in VARSTR-LEN. In such activity, it is important that VARSTR-LEN is already set up, otherwise, STRING will try to move data to the string with length = 0 so no data will be moved. To avoid that mistake we can simply set it to the max size.
Solution 8
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1008. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 WORD-NUM PIC 9(4) COMP. 01 WORD-NUM-TEMP PIC 9(4) COMP. 01 WORD-TAB. 05 WORD OCCURS 1 TO 30 TIMES DEPENDING ON WORD-NUM PIC X(30). 01 WORD-LEN-TAB. 05 WORD-LEN OCCURS 1 TO 30 TIMES DEPENDING ON WORD-NUM PIC 9(4) COMP. 77 IN-STR PIC X(120). 77 IN-PTR PIC 9(4). 77 IN-LEN PIC 9(4). 77 K1 PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. MOVE "Whether you think you can, or you think you can't - you - "'re right." TO IN-STR. PERFORM COMMA-SPLIT. PERFORM EXCEPTION-TEST. PERFORM SPLIT-WORDS. PERFORM DISPLAY-THE-TABLE. MOVE "It takes considerable knowledge just to realise the ext - "end of your own ignorance. - Thomas Sowell" TO IN-STR. PERFORM SPLIT-WORDS. PERFORM DISPLAY-THE-TABLE. STOP RUN. COMMA-SPLIT. MOVE SPACES TO WORD-TAB. UNSTRING IN-STR DELIMITED BY ALL "," OR ALL "-" INTO WORD(1) WORD(2) WORD(3). DISPLAY "SPLIT INTO THREE PARTS:". DISPLAY "PART 1: " WORD(1). DISPLAY "PART 2: " WORD(2). DISPLAY "PART 3: " WORD(3). DISPLAY " ". EXCEPTION-TEST. MOVE SPACES TO WORD-TAB. UNSTRING IN-STR DELIMITED BY ALL " " INTO WORD(1) ON OVERFLOW PERFORM STRING-OVERFLOW. DISPLAY "OUTPUT AFTER OVERFLOW DETECTED >>>" WORD(1) "<<<". MOVE SPACES TO WORD-TAB. UNSTRING IN-STR DELIMITED BY ALL " " INTO WORD(1). DISPLAY "OUTPUT AFTER OVERFLOW NOT DETECTED >>>" WORD(1) "<<<". DISPLAY " ". SPLIT-WORDS. DISPLAY "SPLITTING INPUT INTO WORDS:". MOVE SPACES TO WORD-TAB. MOVE LOW-VALUES TO WORD-LEN-TAB. MOVE 30 TO WORD-NUM. MOVE 1 TO IN-PTR. MOVE 0 TO IN-LEN. MOVE 0 TO WORD-NUM-TEMP. INSPECT FUNCTION REVERSE(IN-STR) TALLYING IN-LEN FOR LEADING SPACES. COMPUTE IN-LEN = LENGTH OF IN-STR - IN-LEN. PERFORM VARYING K1 FROM 1 BY 1 UNTIL IN-PTR > IN-LEN UNSTRING IN-STR DELIMITED BY ALL SPACES INTO WORD(K1) COUNT WORD-LEN(K1) POINTER IN-PTR TALLYING WORD-NUM-TEMP END-UNSTRING DISPLAY "ITERATION: " K1 ", IN-PTR: " IN-PTR ", WORD-NUM: " WORD-NUM-TEMP ", WORD-LEN: " WORD-LEN(K1) ", WORD: " WORD(K1) END-PERFORM. MOVE WORD-NUM-TEMP TO WORD-NUM. DISPLAY " ". DISPLAY-THE-TABLE. DISPLAY "WORD SPLIT RESULT TABLE:". PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > WORD-NUM DISPLAY "WORD " K1 " (" WORD(K1) (1 : WORD-LEN(K1)) ")" END-PERFORM. DISPLAY " ". STRING-OVERFLOW. DISPLAY "Overflow occured".
Output:
SPLIT INTO THREE PARTS: PART 1: Whether you think you can PART 2: or you think you can't PART 3: you're right. Overflow occured OUTPUT AFTER OVERFLOW DETECTED >>>Whether you think you can, or <<< OUTPUT AFTER OVERFLOW NOT DETECTED >>>Whether you think you can, or <<< SPLITTING INPUT INTO WORDS: ITERATION: 0001, IN-PTR: 0009, WORD-NUM: 0001, WORD-LEN: 0007, WORD: Whether ITERATION: 0002, IN-PTR: 0013, WORD-NUM: 0002, WORD-LEN: 0003, WORD: you ITERATION: 0003, IN-PTR: 0019, WORD-NUM: 0003, WORD-LEN: 0005, WORD: think ITERATION: 0004, IN-PTR: 0023, WORD-NUM: 0004, WORD-LEN: 0003, WORD: you ITERATION: 0005, IN-PTR: 0028, WORD-NUM: 0005, WORD-LEN: 0004, WORD: can, ITERATION: 0006, IN-PTR: 0031, WORD-NUM: 0006, WORD-LEN: 0002, WORD: or ITERATION: 0007, IN-PTR: 0035, WORD-NUM: 0007, WORD-LEN: 0003, WORD: you ITERATION: 0008, IN-PTR: 0041, WORD-NUM: 0008, WORD-LEN: 0005, WORD: think ITERATION: 0009, IN-PTR: 0045, WORD-NUM: 0009, WORD-LEN: 0003, WORD: you ITERATION: 0010, IN-PTR: 0051, WORD-NUM: 0010, WORD-LEN: 0005, WORD: can't ITERATION: 0011, IN-PTR: 0053, WORD-NUM: 0011, WORD-LEN: 0001, WORD: - ITERATION: 0012, IN-PTR: 0060, WORD-NUM: 0012, WORD-LEN: 0006, WORD: you're ITERATION: 0013, IN-PTR: 0121, WORD-NUM: 0013, WORD-LEN: 0006, WORD: right. WORD SPLIT RESULT TABLE: WORD 0001 (Whether) WORD 0002 (you) WORD 0003 (think) WORD 0004 (you) WORD 0005 (can,) WORD 0006 (or) WORD 0007 (you) WORD 0008 (think) WORD 0009 (you) WORD 0010 (can't) WORD 0011 (-) WORD 0012 (you're) WORD 0013 (right.) ...
Comments: - UNSTRING function is used for splitting a string into many parts. It's somewhat similar to sub-string functions in other languages but in COBOL it has more functionality. - Similarly to STRING function, during overflow data is kept in the output variables, both with and without ON OVERFLOW clause. - SPLIT-WORDS is the most interesting paragraph, it uses almost all available functionality of UNSTRING in a loop. With this method you can process any string or table no matter how large it is. - ON OVERFLOW is also triggered when there are not enough receiving fields. In SPLIT-WORDS paragraph we copy one word at a time so OVERFLOW condition occurs in all interactions except the last one.
Solution 9
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1009. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 LONG-DATE PIC 9(8). 77 SHORT-DATE PIC 9(6). 77 DAY-OF-YEAR PIC 9(5). 77 CURRENT-TIME PIC 9(8). 01 WEEKDAY PIC 9. 88 MONDAY VALUE 1. 88 TUESDAY VALUE 2. 88 WEDNESDAY VALUE 3. 88 THURSDAY VALUE 4. 88 FRIDAY VALUE 5. 88 SATURDAY VALUE 6. 88 SUNDAY VALUE 7. 01 DATE-STRUCT. 05 D-YEAR PIC X(4). 05 D-SEP1 PIC X VALUE "-". 05 D-MONTH PIC X(2). 05 D-SEP2 PIC X VALUE "-". 05 D-DAY PIC X(2). 01 TIME-STRUCT. 05 T-HOUR PIC X(2). 05 T-SEP1 PIC X VALUE ":". 05 T-MIN PIC X(2). 05 T-SEP2 PIC X VALUE ":". 05 T-SEC PIC X(2). 05 T-SEP3 PIC X VALUE ".". 05 T-MSEC PIC X(3). PROCEDURE DIVISION. MAIN-LOGIC. ACCEPT SHORT-DATE FROM DATE. ACCEPT LONG-DATE FROM DATE YYYYMMDD. ACCEPT DAY-OF-YEAR FROM DAY. ACCEPT WEEKDAY FROM DAY-OF-WEEK. ACCEPT CURRENT-TIME FROM TIME. DISPLAY "SHORT DATE : " SHORT-DATE. DISPLAY "LONG DATE : " LONG-DATE. DISPLAY "DAY OF YEAR : " DAY-OF-YEAR. DISPLAY "CURRENT TIME : " CURRENT-TIME. DISPLAY "WEEKDAY : " WEEKDAY. PERFORM COPY-DATE-TO-STRUCT. PERFORM COPY-TIME-TO-STRUCT. DISPLAY "FORMATTED DATE: " DATE-STRUCT. DISPLAY "FORMATTED TIME: " TIME-STRUCT. IF FRIDAY DISPLAY "FRIDAY! - NO MORE COBOL THIS WEEK!!!". STOP RUN. COPY-DATE-TO-STRUCT. MOVE LONG-DATE(1 : 4) TO D-YEAR. MOVE LONG-DATE(5 : 2) TO D-MONTH. MOVE LONG-DATE(7 : 2) TO D-DAY. COPY-TIME-TO-STRUCT. MOVE CURRENT-TIME(1 : 2) TO T-HOUR. MOVE CURRENT-TIME(3 : 2) TO T-MIN. MOVE CURRENT-TIME(5 : 2) TO T-SEC. MOVE CURRENT-TIME(7 : 2) TO T-MSEC(1 : 2). MOVE "0" TO T-MSEC(3 : 1).
Comments: - ACCEPT statement also enables you to get some data from the system. You've already used it for issuing WTORs. You can also get information about current date and time. - ACCEPT is an easy way to get the current date and time, but whenever you need to perform any date or time-related operation, intrinsic functions give you much more possibilities.
Solution 10
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1010. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 TRAN-TAB. 05 TRAN-REC OCCURS 1 TO 100 TIMES DEPENDING ON TRAN-NUM INDEXED BY TRAN-TAB-IX. 10 TRAN-ID PIC 9(8). 10 TRAN-TIME. 15 TRAN-YEAR PIC X(4). 15 FILLER PIC X. 15 TRAN-MONTH PIC X(2). 15 FILLER PIC X. 15 TRAN-DAY PIC X(2). 15 FILLER PIC X. 15 TRAN-HOUR PIC X(2). 15 FILLER PIC X. 15 TRAN-MINUTE PIC X(2). 15 FILLER PIC X. 15 TRAN-SECOND PIC X(2). 10 TRAN-AMOUNT PIC -(5)9.99. 77 TRAN-NUM PIC 9(4) COMP. 77 TRAN-FOUND PIC 9. 77 K1 PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM POPULATE-THE-TABLE. * PERFORM DISPLAY-THE-TABLE. PERFORM SEARCH-FOR-TRAN0009. PERFORM SEARCH-FIRST-AFTER-THE-DATE. PERFORM SEARCH-LAST-TRAN-OF-A-DAY. STOP RUN. DISPLAY-THE-TABLE. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > TRAN-NUM DISPLAY "ID : " TRAN-ID(K1) DISPLAY "TIME: " TRAN-TIME(K1) DISPLAY "AMNT: " TRAN-AMOUNT(K1) DISPLAY " " END-PERFORM. SEARCH-FOR-TRAN0009. DISPLAY "SEARCHING FOR TRANSACTION WITH ID=9". MOVE 1 TO K1. SEARCH TRAN-REC VARYING K1 AT END DISPLAY "NO TRANSACTION WITH ID=9 EXISTS" WHEN TRAN-ID(K1) = 9 PERFORM TRANSACTION-FOUND. SEARCH-FIRST-AFTER-THE-DATE. DISPLAY "SEARCHING FOR THE FIRST 10$ TRANSACTION SINCE 2018-0 - "4-01". MOVE 1 TO K1. SET TRAN-TAB-IX TO 1. SEARCH TRAN-REC VARYING K1 AT END DISPLAY "NO 10$ OR LARGER TRANSACTION SINCE 2018-04-01" WHEN TRAN-TIME(K1)(1 : 10) NOT < "2018-04-01" AND FUNCTION NUMVAL(TRAN-AMOUNT(K1)) NOT < 10 PERFORM TRANSACTION-FOUND. SEARCH-LAST-TRAN-OF-A-DAY. DISPLAY "SEARCHING FOR THE LAST TRANSACTION ON 2018-03-01" MOVE 1 TO K1. SET TRAN-TAB-IX TO 1. SEARCH TRAN-REC VARYING K1 AT END MOVE 0 TO TRAN-FOUND WHEN TRAN-TIME(K1)(1 : 10) = "2018-03-01" MOVE 1 TO TRAN-FOUND. IF TRAN-FOUND = 1 SEARCH TRAN-REC VARYING K1 AT END COMPUTE K1 = K1 - 1 PERFORM TRANSACTION-FOUND WHEN TRAN-TIME(K1)(1 : 10) > "2018-03-01" COMPUTE K1 = K1 - 1 PERFORM TRANSACTION-FOUND END-SEARCH ELSE DISPLAY "NO TRANSACTIONS ON 2018-03-01" END-IF. TRANSACTION-FOUND. DISPLAY "TRANSACTION FOUND:". DISPLAY "- ID: " TRAN-ID(K1) ", DATE: " TRAN-TIME(K1)(1 : 10) ", TIME: " TRAN-TIME(K1)(12 : 8) ", AMOUNT: " TRAN-AMOUNT(K1). DISPLAY " ". POPULATE-THE-TABLE. MOVE 10 TO TRAN-NUM. MOVE 1 TO TRAN-ID(1). MOVE '2018-03-01/12:33:12' TO TRAN-TIME(1). MOVE 23.2 TO TRAN-AMOUNT(1). MOVE 2 TO TRAN-ID(2). MOVE '2018-03-01/17:13:22' TO TRAN-TIME(2). MOVE 0.3 TO TRAN-AMOUNT(2). MOVE 3 TO TRAN-ID(3). MOVE '2018-03-01/20:32:44' TO TRAN-TIME(3). MOVE 1.99 TO TRAN-AMOUNT(3). MOVE 9 TO TRAN-ID(4). MOVE '2018-03-03/07:33:11' TO TRAN-TIME(4). MOVE 99.10 TO TRAN-AMOUNT(4). MOVE 12 TO TRAN-ID(5). MOVE '2018-03-04/23:15:54' TO TRAN-TIME(5). MOVE 321.09 TO TRAN-AMOUNT(5). MOVE 32 TO TRAN-ID(6). MOVE '2018-03-05/12:11:23' TO TRAN-TIME(6). MOVE 43211 TO TRAN-AMOUNT(6). MOVE 55 TO TRAN-ID(7). MOVE '2018-03-05/12:12:12' TO TRAN-TIME(7). MOVE 540.5 TO TRAN-AMOUNT(7). MOVE 56 TO TRAN-ID(8). MOVE '2018-04-12/10:26:52' TO TRAN-TIME(8). MOVE 5.99 TO TRAN-AMOUNT(8). MOVE 60 TO TRAN-ID(9). MOVE '2018-04-14/16:00:02' TO TRAN-TIME(9). MOVE 42.33 TO TRAN-AMOUNT(9). MOVE 67 TO TRAN-ID(10). MOVE '2018-04-16/11:12:51' TO TRAN-TIME(10). MOVE 13.7 TO TRAN-AMOUNT(10).
Comments: - SEARCH and SEARCH ALL functions search the table until the first occurrence that meets search criteria is found. If you want to find all records with given characteristic you must search for them manually with the use of the loop. - To use SEARCH functions you must define an index for the table. You can use it to later reference the element which was found, or you can choose to use a normal subscript. Either way, you must always reinitialize the index before search – see "Important" paragraph below. - Also, when you use subscript such as K1 during the search, you must set it to the first searched element before executing SEARCH function. - TRAN-AMOUNT is NUMERIC-EDITED type. This type is treated by comparison operators as a string so if to test it against a numeric you need to use NUMVAL function. - Sometimes you don't want to start the search from the beginning. In SEARCH-LAST-TRAN-OF-A-DAY before the second SEARCH index and subscript K1 is not reinitialized so the search will begin from an element on which it ended in the previous SEARCH. Important: - The table index is not reinitialized before SEARCH statement. You must remember to do it manually. In this example, the transaction with ID = 9 is 4th table element. The problem is that END clause is triggered the moment index reaches the end of the table. In this example after 7 iterations. In other words, we test for TRAN-TIME(1) when index points to the 4th element. When index reaches the end TRAN-TIME(7) is tested, so all subsequent elements are skipped. - It's also a reason why it's better to use index instead of subscript in SEARCH statements.
Solution 11
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1011. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 TRAN-TAB. 05 TRAN-REC OCCURS 1 TO 100 TIMES DEPENDING ON TRAN-NUM ASCENDING KEY IS TRAN-ID ASCENDING KEY IS TRAN-TIME INDEXED BY TRAN-IX. 10 TRAN-ID PIC 9(8). 10 TRAN-TIME. 15 TRAN-YEAR PIC X(4). 15 FILLER PIC X. 15 TRAN-MONTH PIC X(2). 15 FILLER PIC X. 15 TRAN-DAY PIC X(2). 15 FILLER PIC X. 15 TRAN-HOUR PIC X(2). 15 FILLER PIC X. 15 TRAN-MINUTE PIC X(2). 15 FILLER PIC X. 15 TRAN-SECOND PIC X(2). 10 TRAN-AMOUNT PIC -(5)9.99. 77 TRAN-NUM PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM POPULATE-THE-TABLE. PERFORM SEARCH-FOR-TRAN0009. PERFORM SEARCH-FOR-TIMESTAMP. STOP RUN. SEARCH-FOR-TRAN0009. DISPLAY "SEARCHING FOR TRANSACTION WITH ID=9". SEARCH ALL TRAN-REC AT END DISPLAY "NO TRANSACTION WITH ID=9 EXISTS" WHEN TRAN-ID(TRAN-IX) = 9 PERFORM TRANSACTION-FOUND. SEARCH-FOR-TIMESTAMP. DISPLAY "SEARCHING FOR TRANSACTION AT 2018-03-01/20:32:44". SEARCH ALL TRAN-REC AT END DISPLAY "NO TRANSACTION DONE AT '2018-03-01/20:32:44'" WHEN TRAN-TIME(TRAN-IX) = "2018-03-01/20:32:44" AND TRAN-ID(TRAN-IX) = 3 PERFORM TRANSACTION-FOUND. TRANSACTION-FOUND. DISPLAY "TRANSACTION FOUND:". DISPLAY "- ID: " TRAN-ID(TRAN-IX) ", DATE: " TRAN-TIME(TRAN-IX)(1 : 10) ", TIME: " TRAN-TIME(TRAN-IX)(12 : 8) ", AMOUNT: " TRAN-AMOUNT(TRAN-IX). DISPLAY " ". POPULATE-THE-TABLE. MOVE 10 TO TRAN-NUM. MOVE 1 TO TRAN-ID(1). MOVE '2018-03-01/12:33:12' TO TRAN-TIME(1). MOVE 23.2 TO TRAN-AMOUNT(1). MOVE 2 TO TRAN-ID(2). MOVE '2018-03-01/17:13:22' TO TRAN-TIME(2). MOVE 0.3 TO TRAN-AMOUNT(2). MOVE 3 TO TRAN-ID(3). MOVE '2018-03-01/20:32:44' TO TRAN-TIME(3). MOVE 1.99 TO TRAN-AMOUNT(3). MOVE 9 TO TRAN-ID(4). MOVE '2018-03-03/07:33:11' TO TRAN-TIME(4). MOVE 99.10 TO TRAN-AMOUNT(4). MOVE 12 TO TRAN-ID(5). MOVE '2018-03-04/23:15:54' TO TRAN-TIME(5). MOVE 321.09 TO TRAN-AMOUNT(5). MOVE 32 TO TRAN-ID(6). MOVE '2018-03-05/12:11:23' TO TRAN-TIME(6). MOVE 43211 TO TRAN-AMOUNT(6). MOVE 55 TO TRAN-ID(7). MOVE '2018-03-05/12:12:12' TO TRAN-TIME(7). MOVE 540.5 TO TRAN-AMOUNT(7). MOVE 56 TO TRAN-ID(8). MOVE '2018-04-12/10:26:52' TO TRAN-TIME(8). MOVE 5.99 TO TRAN-AMOUNT(8). MOVE 60 TO TRAN-ID(9). MOVE '2018-04-14/16:00:02' TO TRAN-TIME(9). MOVE 42.33 TO TRAN-AMOUNT(9). MOVE 67 TO TRAN-ID(10). MOVE '2018-04-16/11:12:51' TO TRAN-TIME(10). MOVE 13.7 TO TRAN-AMOUNT(10).
Comments: - Binary search works correctly only on ordered columns. - To use binary search you must include KEY IS clause in the table definition. - Unlike serial SEARCH, binary SEARCH does not need index reinitialization. Important: - Binary search is always done via Primary Key so the data item specified first in the KEY IS phrase. That's why even if you search for the secondary keys you need to also test for the primary key. Only after the first condition is meet (TRAN-ID), the second condition (TRAN-TIME) is tested. If the second condition is also true WHEN instructions are executed. If the second condition is false the search is NOT continued and AT END instructions are executed. - This means that in our example search via secondary key is useless because we need to know TRAN-ID anyway. But this option may be useful in a situation where the primary key is non-unique.
SORT & MERGE statements
Introduction
There are two special functions in COBOL, SORT & MERGE. Special because they actually invoke DFSORT Utility. Unfortunately, functionality of those two instructions in nowhere close to standalone DFSORT so there are cases in which you'll have to use DFSORT to process input or output of your program. Actually, if a program requires sorted data, it's recommended to do a pre-sort in the preceding step. This solution has better performance and allows you to simplify the program little bit. Still, it's not always possible, in such cases you'll need to know how to use SORT and MERGE instructions.
Tasks
![]() 1. Copy the following file:
1. Copy the following file:
ITEM NAME |DATE |PRICE |VT Porche Carrera |2018-02-12|234060.00$|23 z14 |2016-01-22|OVERFLOW | 5 LG Q7 |2000-11-21| 230.00$|23 Bread |1999-04-30| 0.69$|23 10 eggs |2008-12-04| 3.29$|23 Horse |2006-01-01| 5500.00$|23 Pink carpet |2017-06-02| 199.99$| 8 XXL pants |2018-11-23| 20.90$| 5 Horse |2014-02-21| 110.12$|23 Thinkpad T580 |2003-02-11| 1840.50$|23 2 IMAX tickets |2018-05-21| 39.80$| 0 33 spiders |2011-04-27| 990.00$| 5 Aquarium |2018-02-08| 99.99$|23 Bonsai tree |2003-02-11| 5500.00$| 4 2 helicopters |1997-08-01|864000.00$|23 Skyscraper |1999-03-01|OVERFLOW | 0 Horse |2014-02-06| 341.10$|23 Katana |2018-12-06| 42400.00$|23 Pencil |2015-11-09| 0.80$| 4 Porche Carrera |2018-12-06|214020.00$|23
- Write a program that sorts it by the date in descending order.
- List and describe all SORT special registers.
![]() 2. Modify program from Task#1:
- Use INPUT and OUTPUT PROCEDURE.
- Exclude header from sorting, simply copy it.
- Omit records with "OVERFLOW" price.
- Convert currency from USD to EUR. Exchange rate should be passed as the parameter.
2. Modify program from Task#1:
- Use INPUT and OUTPUT PROCEDURE.
- Exclude header from sorting, simply copy it.
- Omit records with "OVERFLOW" price.
- Convert currency from USD to EUR. Exchange rate should be passed as the parameter.
![]() 3. Modify the program from Task#2:
- Split input file into two separate outputs. History and current files, where history file stores items bought before 2016-01-01 and current file stores all the other items.
- Both files should have headers.
- Sort the data by price (ascending order) and then by VAT (descending order).
3. Modify the program from Task#2:
- Split input file into two separate outputs. History and current files, where history file stores items bought before 2016-01-01 and current file stores all the other items.
- Both files should have headers.
- Sort the data by price (ascending order) and then by VAT (descending order).
![]() 4. Modify the program from Task#1 again:
- Sort the file via item name.
- Then modify sorting sequence in the following order: numbers, upper-case letters, lower-case letters, space and '-' character, and run the program again.
4. Modify the program from Task#1 again:
- Sort the file via item name.
- Then modify sorting sequence in the following order: numbers, upper-case letters, lower-case letters, space and '-' character, and run the program again.
![]() 5. Write a program that merges three files, two outputs from Task#3 and the following file:
5. Write a program that merges three files, two outputs from Task#3 and the following file:
ITEM NAME |DATE |PRICE |VT Ice cream |2011-11-23| 1.21E| 0 USB adapter |2018-04-13| 5.50E|23 Computer mouse |2013-01-21| 12.99E| 5 Jacket |1999-12-06| 69.05E| 8 Door |2018-05-28| 180.00E|23 LG Q7 |2000-11-21| 189.87E|23 Bicycle |2014-04-11| 245.00E|23 Plane ticket |2017-06-29| 499.99E|23 Bonsai tree |2003-02-11| 4540.52E| 4
- Use MERGE statement.
- Output should contain a single header.
![]() 6. Modify the program from Task#5:
- Skip duplicated records.
- Add a new column named "VAT VALUE" to the output file. It should contain VAT calculated from the full price.
- Re-sort records by the date in ascending order.
6. Modify the program from Task#5:
- Skip duplicated records.
- Add a new column named "VAT VALUE" to the output file. It should contain VAT calculated from the full price.
- Re-sort records by the date in ascending order.
Hint 4
You'll have to define non-standard alphabet. See "ALPHABET clause" topic in "Enterprise COBOL for z/OS: Language Reference".
Hint 5
MERGE statement requires input file to be sorted accordingly to the column specified in MERGE statement. Without that condition, MERGE operation won't work as intended. In this example, purchases are sorted correctly but headers are not. SPACES are before letters in standard sort order. Also, MERGE doesn't have INPUT PROCEDURE through which we could exclude headers from processing like in case of SORT. There are two solutions to this problem. First is to merge the files using SORT keyword with INPUT and OUTPUT PROCEDURE defined. The second one is to use ALPHABET clause to change the default collating sequence.
Solution 1
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1101) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1101. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT ITEM-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS ITEM-FS. SELECT ITEMOUT-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS ITEMOUT-FS. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. FD ITEM-FILE RECORDING MODE F. 01 ITEM-RECORD. 05 ITEM-NAME PIC X(15). 05 FILLER PIC X. 05 ITEM-DATE PIC X(10). 05 FILLER PIC X. 05 ITEM-PRICE PIC X(10). 05 FILLER PIC X. 05 ITEM-VAT PIC X(2). FD ITEMOUT-FILE RECORDING MODE F. 01 ITEMOUT-RECORD. 05 ITEMOUT-NAME PIC X(15). 05 FILLER PIC X. 05 ITEMOUT-DATE PIC X(10). 05 FILLER PIC X. 05 ITEMOUT-PRICE PIC X(10). 05 FILLER PIC X. 05 ITEMOUT-VAT PIC X(2). SD SORTWRK-FILE. 01 SORTWRK-RECORD. 05 SORTWRK-NAME PIC X(15). 05 FILLER PIC X. 05 SORTWRK-DATE PIC X(10). 05 FILLER PIC X. 05 SORTWRK-PRICE PIC X(10). 05 FILLER PIC X. 05 SORTWRK-VAT PIC X(2). WORKING-STORAGE SECTION. 77 ITEM-FS PIC X(2). 77 ITEMOUT-FS PIC X(2). PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON ITEM-FILE ITEMOUT-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'IN1' STATUS: " ITEM-FS. DISPLAY "'OUT1' STATUS: " ITEMOUT-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF ITEM-FS NOT = "42" CLOSE ITEM-FILE. IF ITEMOUT-FS NOT = "42" CLOSE ITEMOUT-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. PERFORM SORT-RECORDS. STOP RUN. SORT-RECORDS. SORT SORTWRK-FILE DESCENDING KEY SORTWRK-DATE USING ITEM-FILE GIVING ITEMOUT-FILE. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.SORTED,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=27960,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
Comments: - SORT statement executes DFSORT. Because of that, you don't have to worry about opening or closing files. It's managed by DFSORT, but you need to define file structure (at least the key used for sorting) and allocate them. - SD file definition is used for defining sort work file. It should have the same characteristics as the input file. - Since Enterprise COBOL 5.2 you can also use SORT statement against tables, not only files. - If the sorted file includes header it will stay at the top only if you sort by numeric column in ascending order. In other cases, you need to exclude it from sorting, the next Task presents how you can easily to that. - For code simplicity FILE STATUS and DECLARATIVES are not used here and in the upcoming tasks for checking file errors but in normal programming assignment, you should always use them. SORT special registers: - SORT-CORE-SIZE – You can use it to specify the number of bytes available for sorting. - SORT-FILE-SIZE – You can use it to specify the number of records in the input file. - SORT-MODE-SIZE – Useful only for sorting variable records. You can use it to specify record length that occurs most frequently in the input file. - SORT-CONTROL – "IGZSRTCD" by default. It defines DD name for the additional control statements for DFSORT. - SORT-MESSAGE – "SYSOUT" by default. It defines DD statement to which DFSORT messages will be written. - SORT-RETURN – It contains return code from SORT operation (0 is successful and 16 if unsuccessful).
Solution 2
COBOL code:
//RUNCOBOL EXEC IGYWCLG,PARM.GO='0.82555' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1102) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1102. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT ITEM-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS ITEM-FS. SELECT ITEMOUT-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS ITEMOUT-FS. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. FD ITEM-FILE RECORDING MODE F. 01 ITEM-RECORD. 05 ITEM-NAME PIC X(15). 05 FILLER PIC X. 05 ITEM-DATE PIC X(10). 05 FILLER PIC X. 05 ITEM-PRICE PIC X(9). 05 ITEM-CURRENCY PIC X. 05 FILLER PIC X. 05 ITEM-VAT PIC X(2). FD ITEMOUT-FILE RECORDING MODE F. 01 ITEMOUT-RECORD. 05 ITEMOUT-NAME PIC X(15). 05 FILLER PIC X. 05 ITEMOUT-DATE PIC X(10). 05 FILLER PIC X. 05 ITEMOUT-PRICE PIC X(9). 05 ITEMOUT-CURRENCY PIC X. 05 FILLER PIC X. 05 ITEMOUT-VAT PIC X(2). SD SORTWRK-FILE. 01 SORTWRK-RECORD. 05 SORTWRK-NAME PIC X(15). 05 FILLER PIC X. 05 SORTWRK-DATE PIC X(10). 05 FILLER PIC X. 05 SORTWRK-PRICE PIC X(9). 05 SORTWRK-CURRENCY PIC X. 05 FILLER PIC X. 05 SORTWRK-VAT PIC X(2). WORKING-STORAGE SECTION. 77 ITEM-FS PIC X(2). 77 ITEMOUT-FS PIC X(2). 77 ITEM-EOF PIC 9 VALUE 0. 77 SORTWRK-EOF PIC 9 VALUE 0. 77 EXCHANGE-RATE PIC 9(4)V9(5). 77 TEMP-NUM PIC 9(13)V9(5). 77 TEMP-NUM-EDI PIC Z(5)9.99. 77 HEADER PIC X(40). LINKAGE SECTION. 01 PARMDATA. 05 PARM-L PIC 9(4) COMP. 05 PARM PIC X(10). PROCEDURE DIVISION USING PARMDATA. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON ITEM-FILE ITEMOUT-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'IN1' STATUS: " ITEM-FS. DISPLAY "'OUT1' STATUS: " ITEMOUT-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF ITEM-FS NOT = "42" CLOSE ITEM-FILE. IF ITEMOUT-FS NOT = "42" CLOSE ITEMOUT-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. PERFORM VERIFY-PARM. PERFORM OPEN-FILES. PERFORM COPY-HEADER. PERFORM SORT-RECORDS. PERFORM CLOSE-FILES. STOP RUN. VERIFY-PARM. DISPLAY PARM. COMPUTE EXCHANGE-RATE = FUNCTION NUMVAL(PARM(1 : PARM-L)). OPEN-FILES. OPEN INPUT ITEM-FILE. OPEN OUTPUT ITEMOUT-FILE. CLOSE-FILES. CLOSE ITEM-FILE. CLOSE ITEMOUT-FILE. SORT-RECORDS. SORT SORTWRK-FILE DESCENDING KEY SORTWRK-DATE INPUT PROCEDURE PRE-SORT-PROC OUTPUT PROCEDURE POST-SORT-PROC. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. COPY-HEADER. READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. IF ITEM-EOF = 0 MOVE ITEM-RECORD TO HEADER ELSE DISPLAY "INPUT FILE IS EMPTY." MOVE 8 TO RETURN-CODE STOP RUN END-IF. PRE-SORT-PROC. READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. PERFORM UNTIL ITEM-EOF = 1 IF ITEM-PRICE NOT = "OVERFLOW" RELEASE SORTWRK-RECORD FROM ITEM-RECORD END-IF READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF END-READ END-PERFORM. POST-SORT-PROC. MOVE HEADER TO ITEMOUT-RECORD. PERFORM UPDATE-AND-SAVE-OUTREC. PERFORM UNTIL SORTWRK-EOF = 1 PERFORM EXCHANGE-CURRENCY PERFORM UPDATE-AND-SAVE-OUTREC END-PERFORM. UPDATE-AND-SAVE-OUTREC. WRITE ITEMOUT-RECORD. RETURN SORTWRK-FILE RECORD INTO ITEMOUT-RECORD AT END MOVE 1 TO SORTWRK-EOF. EXCHANGE-CURRENCY. COMPUTE TEMP-NUM = FUNCTION NUMVAL(SORTWRK-PRICE). COMPUTE TEMP-NUM = EXCHANGE-RATE * TEMP-NUM. MOVE TEMP-NUM TO TEMP-NUM-EDI. MOVE TEMP-NUM-EDI TO ITEMOUT-PRICE. MOVE "E" TO ITEMOUT-CURRENCY. //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.SORTED,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=27960,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
Comments: - INPUT and OUTPUT PROCEDURE statements enable the programmer to process records just before or straight after SORT is done. - When you use INPUT and OUTPUT PROCEDURE, file opening and closure must be done manually. DFSORT receives data for sorting via RELEASE statement, and you can read SORT file with use of RETURN statement which works the same way as READ. - For simplification E letter was used instead of Euro sign. Euro sign in unavailable in the default EBCDIC character set but there are many CCSIDs, including some EBCDIC CCSIDs which contain this character.
Solution 3
COBOL code:
//RUNCOBOL EXEC IGYWCLG,PARM.GO='0.82555' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1103) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1103. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT ITEM-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL. SELECT ITEMOUT1-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL. SELECT ITEMOUT2-FILE ASSIGN TO OUT2 ORGANIZATION IS SEQUENTIAL. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. FD ITEM-FILE RECORDING MODE F. 01 ITEM-RECORD. 05 ITEM-NAME PIC X(15). 05 FILLER PIC X. 05 ITEM-DATE PIC X(10). 05 FILLER PIC X. 05 ITEM-PRICE PIC X(9). 05 ITEM-CURRENCY PIC X. 05 FILLER PIC X. 05 ITEM-VAT PIC X(2). FD ITEMOUT1-FILE RECORDING MODE F. 01 ITEMOUT1-RECORD. 05 ITEMOUT1-NAME PIC X(15). 05 FILLER PIC X. 05 ITEMOUT1-DATE PIC X(10). 05 FILLER PIC X. 05 ITEMOUT1-PRICE PIC X(9). 05 ITEMOUT1-CURRENCY PIC X. 05 FILLER PIC X. 05 ITEMOUT1-VAT PIC X(2). FD ITEMOUT2-FILE RECORDING MODE F. 01 ITEMOUT2-RECORD. 05 ITEMOUT2-NAME PIC X(15). 05 FILLER PIC X. 05 ITEMOUT2-DATE PIC X(10). 05 FILLER PIC X. 05 ITEMOUT2-PRICE PIC X(9). 05 ITEMOUT2-CURRENCY PIC X. 05 FILLER PIC X. 05 ITEMOUT2-VAT PIC X(2). SD SORTWRK-FILE. 01 SORTWRK-RECORD. 05 SORTWRK-NAME PIC X(15). 05 FILLER PIC X. 05 SORTWRK-DATE PIC X(10). 05 FILLER PIC X. 05 SORTWRK-PRICE PIC X(9). 05 SORTWRK-CURRENCY PIC X. 05 FILLER PIC X. 05 SORTWRK-VAT PIC X(2). WORKING-STORAGE SECTION. 77 ITEM-FS PIC X(2). 77 ITEMOUT1-FS PIC X(2). 77 ITEMOUT2-FS PIC X(2). 77 ITEM-EOF PIC 9 VALUE 0. 77 SORTWRK-EOF PIC 9 VALUE 0. 77 EXCHANGE-RATE PIC 9(4)V9(5). 77 TEMP-NUM PIC 9(13)V9(5). 77 TEMP-NUM-EDI PIC Z(5)9.99. 77 HEADER PIC X(40). LINKAGE SECTION. 01 PARMDATA. 05 PARM-L PIC 9(4) COMP. 05 PARM PIC X(10). PROCEDURE DIVISION USING PARMDATA. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON ITEM-FILE ITEMOUT1-FILE ITEMOUT2-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'IN1' STATUS: " ITEM-FS. DISPLAY "'OUT1' STATUS: " ITEMOUT1-FS. DISPLAY "'OUT2' STATUS: " ITEMOUT2-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF ITEM-FS NOT = "42" CLOSE ITEM-FILE. IF ITEMOUT1-FS NOT = "42" CLOSE ITEMOUT1-FILE. IF ITEMOUT2-FS NOT = "42" CLOSE ITEMOUT2-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. PERFORM VERIFY-PARM. PERFORM OPEN-FILES. PERFORM COPY-HEADER. PERFORM SORT-RECORDS. PERFORM CLOSE-FILES. STOP RUN. VERIFY-PARM. DISPLAY PARM. COMPUTE EXCHANGE-RATE = FUNCTION NUMVAL(PARM(1 : PARM-L)). OPEN-FILES. OPEN INPUT ITEM-FILE. OPEN OUTPUT ITEMOUT1-FILE. OPEN OUTPUT ITEMOUT2-FILE. CLOSE-FILES. CLOSE ITEM-FILE. CLOSE ITEMOUT1-FILE. CLOSE ITEMOUT2-FILE. SORT-RECORDS. SORT SORTWRK-FILE ASCENDING KEY SORTWRK-PRICE DESCENDING KEY SORTWRK-VAT INPUT PROCEDURE PRE-SORT-PROC OUTPUT PROCEDURE POST-SORT-PROC. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. COPY-HEADER. READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. IF ITEM-EOF = 0 MOVE ITEM-RECORD TO HEADER ELSE DISPLAY "INPUT FILE IS EMPTY." MOVE 8 TO RETURN-CODE STOP RUN END-IF. PRE-SORT-PROC. READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. PERFORM UNTIL ITEM-EOF = 1 IF ITEM-PRICE NOT = "OVERFLOW" RELEASE SORTWRK-RECORD FROM ITEM-RECORD END-IF READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF END-READ END-PERFORM. POST-SORT-PROC. MOVE HEADER TO ITEMOUT1-RECORD. MOVE HEADER TO ITEMOUT2-RECORD. WRITE ITEMOUT1-RECORD. WRITE ITEMOUT2-RECORD. RETURN SORTWRK-FILE RECORD INTO ITEMOUT1-RECORD AT END MOVE 1 TO SORTWRK-EOF. PERFORM UNTIL SORTWRK-EOF = 1 PERFORM EXCHANGE-CURRENCY PERFORM UPDATE-AND-SAVE-OUTREC END-PERFORM. UPDATE-AND-SAVE-OUTREC. IF ITEMOUT1-DATE(1:4) < "2016" WRITE ITEMOUT1-RECORD ELSE MOVE ITEMOUT1-RECORD TO ITEMOUT2-RECORD WRITE ITEMOUT2-RECORD END-IF. RETURN SORTWRK-FILE RECORD INTO ITEMOUT1-RECORD AT END MOVE 1 TO SORTWRK-EOF. EXCHANGE-CURRENCY. COMPUTE TEMP-NUM = FUNCTION NUMVAL(SORTWRK-PRICE). COMPUTE TEMP-NUM = EXCHANGE-RATE * TEMP-NUM. MOVE TEMP-NUM TO TEMP-NUM-EDI. MOVE TEMP-NUM-EDI TO ITEMOUT1-PRICE. MOVE "E" TO ITEMOUT1-CURRENCY. //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.HISTORY,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=27960,RECFM=FB //GO.OUT2 DD DSN=JSADEK.COBOL.SHOPPING.CURRENT,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=27960,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
Comments: - In this example, you can see how you can easily use OUTPUT PROCEDURE to split data after the sort. - Thanks to EBCDIC collating sequence we can successfully sort numbers as a string, assuming that numbers are justified to the right.
Solution 4
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1104) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1104. ENVIRONMENT DIVISION. CONFIGURATION SECTION. SPECIAL-NAMES. ALPHABET MY-ALPHABET IS "0" THROUGH "9" "A" THROUGH "Z" "a" THROUGH "z" SPACE "-". INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT ITEM-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS ITEM-FS. SELECT ITEMOUT-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS ITEMOUT-FS. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. FD ITEM-FILE RECORDING MODE F. 01 ITEM-RECORD. 05 ITEM-NAME PIC X(15). 05 FILLER PIC X. 05 ITEM-DATE PIC X(10). 05 FILLER PIC X. 05 ITEM-PRICE PIC X(9). 05 ITEM-CURRENCY PIC X. 05 FILLER PIC X. 05 ITEM-VAT PIC X(2). FD ITEMOUT-FILE RECORDING MODE F. 01 ITEMOUT-RECORD. 05 ITEMOUT-NAME PIC X(15). 05 FILLER PIC X. 05 ITEMOUT-DATE PIC X(10). 05 FILLER PIC X. 05 ITEMOUT-PRICE PIC X(9). 05 ITEMOUT-CURRENCY PIC X. 05 FILLER PIC X. 05 ITEMOUT-VAT PIC X(2). SD SORTWRK-FILE. 01 SORTWRK-RECORD. 05 SORTWRK-NAME PIC X(15). 05 FILLER PIC X. 05 SORTWRK-DATE PIC X(10). 05 FILLER PIC X. 05 SORTWRK-PRICE PIC X(9). 05 SORTWRK-CURRENCY PIC X. 05 FILLER PIC X. 05 SORTWRK-VAT PIC X(2). WORKING-STORAGE SECTION. 77 ITEM-FS PIC X(2). 77 ITEMOUT-FS PIC X(2). 77 ITEM-EOF PIC 9 VALUE 0. 77 SORTWRK-EOF PIC 9 VALUE 0. 77 HEADER PIC X(40). PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON ITEM-FILE ITEMOUT-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'IN1' STATUS: " ITEM-FS. DISPLAY "'OUT1' STATUS: " ITEMOUT-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF ITEM-FS NOT = "42" CLOSE ITEM-FILE. IF ITEMOUT-FS NOT = "42" CLOSE ITEMOUT-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM COPY-HEADER. PERFORM SORT-RECORDS. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT ITEM-FILE. OPEN OUTPUT ITEMOUT-FILE. CLOSE-FILES. CLOSE ITEM-FILE. CLOSE ITEMOUT-FILE. SORT-RECORDS. SORT SORTWRK-FILE ASCENDING KEY SORTWRK-NAME COLLATING SEQUENCE IS MY-ALPHABET INPUT PROCEDURE PRE-SORT-PROC OUTPUT PROCEDURE POST-SORT-PROC. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. COPY-HEADER. READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. IF ITEM-EOF = 0 MOVE ITEM-RECORD TO HEADER ELSE DISPLAY "INPUT FILE IS EMPTY." MOVE 8 TO RETURN-CODE STOP RUN END-IF. PRE-SORT-PROC. READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. PERFORM UNTIL ITEM-EOF = 1 RELEASE SORTWRK-RECORD FROM ITEM-RECORD READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF END-READ END-PERFORM. POST-SORT-PROC. MOVE HEADER TO ITEMOUT-RECORD. PERFORM UPDATE-AND-SAVE-OUTREC. PERFORM UNTIL SORTWRK-EOF = 1 PERFORM UPDATE-AND-SAVE-OUTREC END-PERFORM. UPDATE-AND-SAVE-OUTREC. WRITE ITEMOUT-RECORD. RETURN SORTWRK-FILE RECORD INTO ITEMOUT-RECORD AT END MOVE 1 TO SORTWRK-EOF. //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.SORTED,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=27960,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
Output:
STANDARD ORDER |MY-ALPHABET ORDER z14 |10 eggs Aquarium |2 IMAX tickets Bonsai tree |2 helicopters Bread |33 spiders Horse |Aquarium Horse |Bonsai tree Horse |Bread Katana |Horse Pencil |Horse Pink carpet |Horse Porche Carrera |Katana Porche Carrera |Pencil \G Q7 |Pink carpet Skyscraper |Porche Carrera Thinkpad T580 |Porche Carrera XXL pants |\G Q7 10 eggs |Skyscraper 2 helicopters |Thinkpad T580 2 IMAX tickets |XXL pants 33 spiders |z14
Comments: - Standard collating sequence (sort order) in COBOL goes more or less as follows: space, special characters (%$#" etc.), lower-case letters, upper-case letters, and numbers. But there are some exceptions, for example, backslash "\" is between "R" and "S". - You may use your own collating sequence to define unusual sorting order or even if you don't like that characters like backslash are positioned in the middle of the alphabet. - When user collating sequence is defined, characters defined there are considered as the first in the collating sequence. In other words, by defining "A" THROUGH "Z" in the ALPHABET clause, we also moved those letters before all characters that are not mentioned in the ALPHABET clause in the collating sequence. - In result, MY-ALPHABET defines sort order as follows: numbers, upper-case letters, lower-case letters, space, "-", all the other characters in their usual order. - You can use THROUGH word to define array of characters, or ALSO word to define characters considered "equal" in sort order.
Solution 5
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1105) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1105. ENVIRONMENT DIVISION. CONFIGURATION SECTION. SPECIAL-NAMES. ALPHABET MY-ALPHABET IS "a" THROUGH "z" "A" THROUGH "Z". INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT INPUT1-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS INPUT1-FS. SELECT INPUT2-FILE ASSIGN TO IN2 ORGANIZATION IS SEQUENTIAL FILE STATUS IS INPUT2-FS. SELECT INPUT3-FILE ASSIGN TO IN3 ORGANIZATION IS SEQUENTIAL FILE STATUS IS INPUT3-FS. SELECT OUTPUT1-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS OUTPUT1-FS. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. FD INPUT1-FILE RECORDING MODE F. 01 INPUT1-RECORD. 05 INPUT1-NAME PIC X(15). 05 FILLER PIC X. 05 INPUT1-DATE PIC X(10). 05 FILLER PIC X. 05 INPUT1-PRICE PIC X(9). 05 INPUT1-CURRENCY PIC X. 05 FILLER PIC X. 05 INPUT1-VAT PIC X(2). FD INPUT2-FILE RECORDING MODE F. 01 INPUT2-RECORD. 05 INPUT2-NAME PIC X(15). 05 FILLER PIC X. 05 INPUT2-DATE PIC X(10). 05 FILLER PIC X. 05 INPUT2-PRICE PIC X(9). 05 INPUT2-CURRENCY PIC X. 05 FILLER PIC X. 05 INPUT2-VAT PIC X(2). FD INPUT3-FILE RECORDING MODE F. 01 INPUT3-RECORD. 05 INPUT3-NAME PIC X(15). 05 FILLER PIC X. 05 INPUT3-DATE PIC X(10). 05 FILLER PIC X. 05 INPUT3-PRICE PIC X(9). 05 INPUT3-CURRENCY PIC X. 05 FILLER PIC X. 05 INPUT3-VAT PIC X(2). FD OUTPUT1-FILE RECORDING MODE F. 01 OUTPUT1-RECORD. 05 OUTPUT1-NAME PIC X(15). 05 FILLER PIC X. 05 OUTPUT1-DATE PIC X(10). 05 FILLER PIC X. 05 OUTPUT1-PRICE PIC X(9). 05 OUTPUT1-CURRENCY PIC X. 05 FILLER PIC X. 05 OUTPUT1-VAT PIC X(2). SD SORTWRK-FILE. 01 SORTWRK-RECORD. 05 SORTWRK-NAME PIC X(15). 05 FILLER PIC X. 05 SORTWRK-DATE PIC X(10). 05 FILLER PIC X. 05 SORTWRK-PRICE PIC X(9). 05 SORTWRK-CURRENCY PIC X. 05 FILLER PIC X. 05 SORTWRK-VAT PIC X(2). WORKING-STORAGE SECTION. 77 INPUT1-FS PIC X(2). 77 INPUT2-FS PIC X(2). 77 INPUT3-FS PIC X(2). 77 OUTPUT1-FS PIC X(2). 77 SORTWRK-EOF PIC 9 VALUE 0. PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON INPUT1-FILE INPUT2-FILE INPUT3-FILE OUTPUT1-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'IN1' STATUS: " INPUT1-FS. DISPLAY "'IN2' STATUS: " INPUT2-FS. DISPLAY "'IN3' STATUS: " INPUT3-FS. DISPLAY "'OUT1' STATUS: " OUTPUT1-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF INPUT1-FS NOT = "42" CLOSE INPUT1-FILE. IF INPUT2-FS NOT = "42" CLOSE INPUT2-FILE. IF INPUT3-FS NOT = "42" CLOSE INPUT3-FILE. IF OUTPUT1-FS NOT = "42" CLOSE OUTPUT1-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM MERGE-RECORDS. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN OUTPUT OUTPUT1-FILE. CLOSE-FILES. CLOSE OUTPUT1-FILE. MERGE-RECORDS. MERGE SORTWRK-FILE ASCENDING KEY SORTWRK-PRICE COLLATING SEQUENCE IS MY-ALPHABET USING INPUT1-FILE INPUT2-FILE INPUT3-FILE OUTPUT PROCEDURE POST-MERGE-PROC. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. POST-MERGE-PROC. RETURN SORTWRK-FILE AT END MOVE 1 TO SORTWRK-EOF. RETURN SORTWRK-FILE AT END MOVE 1 TO SORTWRK-EOF. RETURN SORTWRK-FILE RECORD INTO OUTPUT1-RECORD AT END MOVE 1 TO SORTWRK-EOF. PERFORM COPY-OUTREC. PERFORM UNTIL SORTWRK-EOF = 1 PERFORM COPY-OUTREC END-PERFORM. COPY-OUTREC. WRITE OUTPUT1-RECORD. RETURN SORTWRK-FILE RECORD INTO OUTPUT1-RECORD AT END MOVE 1 TO SORTWRK-EOF. //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING.HISTORY //GO.IN2 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING.CURRENT //GO.IN3 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING.NEW //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.MERGED,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=27960,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
Output:
ITEM NAME |DATE |PRICE |VT Bread |1999-04-30| 0.56E|23 Pencil |2015-11-09| 0.66E| 4 Ice cream |2011-11-23| 1.21E| 0 10 eggs |2008-12-04| 2.71E|23 USB adapter |2018-04-13| 5.50E|23 Computer mouse |2013-01-21| 12.99E| 5 XXL pants |2018-11-23| 17.25E| 5 2 IMAX tickets |2018-05-21| 32.85E| 0 Jacket |1999-12-06| 69.05E| 8 Aquarium |2018-02-08| 82.54E|23 Horse |2014-02-21| 90.90E|23 Pink carpet |2017-06-02| 165.10E| 8 Door |2018-05-28| 180.00E|23 LG Q7 |2000-11-21| 189.87E|23 LG Q7 |2000-11-21| 189.87E|23 Bicycle |2014-04-11| 245.00E|23 Horse |2014-02-06| 281.59E|23 Plane ticket |2017-06-29| 499.99E|23 33 spiders |2011-04-27| 817.29E| 5 Thinkpad T580 |2003-02-11| 1519.42E|23 Horse |2006-01-01| 4540.52E|23 Bonsai tree |2003-02-11| 4540.52E| 4 Bonsai tree |2003-02-11| 4540.52E| 4 Katana |2018-12-06| 35003.32E|23 Porche Carrera |2018-12-06|176684.21E|23 Porche Carrera |2018-02-12|193228.23E|23 2 helicopters |1997-08-01|713275.20E|23
Comments: - MERGE statement requires input files to be sorted accordingly to the same collating sequence as used in MERGE statement. Prices are in proper order but headers are out of order (letters are after space in default EBCDIC sequence). Because of that to make MERGE work correctly collating sequence must have been redefined. - If you use INPUT PROCEDURE you must open and close input files manually. If you use OUTPUT PROCEDURE you must open and close output files manually. - OUTPUT PROCEDURE has one purpose in this program, elimination of two duplicated headers.
Solution 6
COBOL code:
//RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1106) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1106. ENVIRONMENT DIVISION. CONFIGURATION SECTION. SPECIAL-NAMES. ALPHABET MY-ALPHABET IS "a" THROUGH "z" "A" THROUGH "Z". INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT INPUT1-FILE ASSIGN TO IN1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS INPUT1-FS. SELECT INPUT2-FILE ASSIGN TO IN2 ORGANIZATION IS SEQUENTIAL FILE STATUS IS INPUT2-FS. SELECT INPUT3-FILE ASSIGN TO IN3 ORGANIZATION IS SEQUENTIAL FILE STATUS IS INPUT3-FS. SELECT OUTPUT1-FILE ASSIGN TO OUT1 ORGANIZATION IS SEQUENTIAL FILE STATUS IS OUTPUT1-FS. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. FD INPUT1-FILE RECORDING MODE F. 01 INPUT1-RECORD. 05 INPUT1-NAME PIC X(15). 05 FILLER PIC X. 05 INPUT1-DATE PIC X(10). 05 FILLER PIC X. 05 INPUT1-PRICE PIC X(9). 05 INPUT1-CURRENCY PIC X. 05 FILLER PIC X. 05 INPUT1-VAT PIC X(2). FD INPUT2-FILE RECORDING MODE F. 01 INPUT2-RECORD. 05 INPUT2-NAME PIC X(15). 05 FILLER PIC X. 05 INPUT2-DATE PIC X(10). 05 FILLER PIC X. 05 INPUT2-PRICE PIC X(9). 05 INPUT2-CURRENCY PIC X. 05 FILLER PIC X. 05 INPUT2-VAT PIC X(2). FD INPUT3-FILE RECORDING MODE F. 01 INPUT3-RECORD. 05 INPUT3-NAME PIC X(15). 05 FILLER PIC X. 05 INPUT3-DATE PIC X(10). 05 FILLER PIC X. 05 INPUT3-PRICE PIC X(9). 05 INPUT3-CURRENCY PIC X. 05 FILLER PIC X. 05 INPUT3-VAT PIC X(2). FD OUTPUT1-FILE RECORDING MODE F. 01 OUTPUT1-RECORD. 05 OUTPUT1-NAME PIC X(15). 05 FILLER PIC X. 05 OUTPUT1-DATE PIC X(10). 05 FILLER PIC X. 05 OUTPUT1-PRICE PIC X(9). 05 OUTPUT1-CURRENCY PIC X. 05 FILLER PIC X. 05 OUTPUT1-VAT PIC X(2). 05 OUTPUT1-VAT-FIL PIC X. 05 OUTPUT1-VAT-VAL PIC X(9). 05 OUTPUT1-VAT-CUR PIC X. SD SORTWRK-FILE. 01 SORTWRK-RECORD. 05 SORTWRK-NAME PIC X(15). 05 FILLER PIC X. 05 SORTWRK-DATE PIC X(10). 05 FILLER PIC X. 05 SORTWRK-PRICE PIC X(9). 05 SORTWRK-CURRENCY PIC X. 05 FILLER PIC X. 05 SORTWRK-VAT PIC X(2). 05 SORTWRK-VAT-FIL PIC X. 05 SORTWRK-VAT-VAL PIC X(9). 05 SORTWRK-VAT-CUR PIC X. WORKING-STORAGE SECTION. 77 INPUT1-FS PIC X(2). 77 INPUT2-FS PIC X(2). 77 INPUT3-FS PIC X(2). 77 OUTPUT1-FS PIC X(2). 77 SORTWRK-EOF PIC 9 VALUE 0. 77 PREVIOUS-RECORD PIC X(40). 77 TEMP-RECORD PIC X(40). 77 VAT-PERCENT PIC 9(2) COMP. 77 VAT-FULL-PRICE PIC 9(10)V9(4) COMP. 77 VAT-VALUE PIC Z(5)9.99. PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON INPUT1-FILE INPUT2-FILE INPUT3-FILE OUTPUT1-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'IN1' STATUS: " INPUT1-FS. DISPLAY "'IN2' STATUS: " INPUT2-FS. DISPLAY "'IN3' STATUS: " INPUT3-FS. DISPLAY "'OUT1' STATUS: " OUTPUT1-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF INPUT1-FS NOT = "42" CLOSE INPUT1-FILE. IF INPUT2-FS NOT = "42" CLOSE INPUT2-FILE. IF INPUT3-FS NOT = "42" CLOSE INPUT3-FILE. IF OUTPUT1-FS NOT = "42" CLOSE OUTPUT1-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. MOVE "SORTOUT " TO SORT-MESSAGE. PERFORM OPEN-FILES. PERFORM MERGE-RECORDS. PERFORM CLOSE-FILES. PERFORM RE-SORT-BY-DATE. STOP RUN. OPEN-FILES. OPEN OUTPUT OUTPUT1-FILE. CLOSE-FILES. CLOSE OUTPUT1-FILE. MERGE-RECORDS. MERGE SORTWRK-FILE ASCENDING KEY SORTWRK-PRICE COLLATING SEQUENCE IS MY-ALPHABET USING INPUT1-FILE INPUT2-FILE INPUT3-FILE OUTPUT PROCEDURE POST-MERGE-PROC. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. POST-MERGE-PROC. RETURN SORTWRK-FILE RECORD INTO TEMP-RECORD AT END MOVE 1 TO SORTWRK-EOF. PERFORM COPY-OUTREC. PERFORM UNTIL SORTWRK-EOF = 1 PERFORM COPY-OUTREC END-PERFORM. COPY-OUTREC. IF TEMP-RECORD NOT = PREVIOUS-RECORD MOVE TEMP-RECORD TO PREVIOUS-RECORD IF TEMP-RECORD(40 : 1) IS NOT NUMERIC PERFORM COPY-HEADER ELSE PERFORM CALCULATE-VAT-VALUE END-IF WRITE OUTPUT1-RECORD END-IF. RETURN SORTWRK-FILE RECORD INTO TEMP-RECORD AT END MOVE 1 TO SORTWRK-EOF. COPY-HEADER. MOVE TEMP-RECORD TO OUTPUT1-RECORD(1 : 40). MOVE "|VAT VALUE " TO OUTPUT1-RECORD(41 : 11). CALCULATE-VAT-VALUE. MOVE TEMP-RECORD TO OUTPUT1-RECORD. MOVE "|" TO OUTPUT1-VAT-FIL. MOVE TEMP-RECORD(37 : 1) TO OUTPUT1-VAT-CUR. COMPUTE VAT-PERCENT = FUNCTION NUMVAL(OUTPUT1-VAT). COMPUTE VAT-FULL-PRICE = FUNCTION NUMVAL(OUTPUT1-PRICE). COMPUTE VAT-FULL-PRICE ROUNDED = (VAT-PERCENT / 100) * VAT-FULL-PRICE. MOVE VAT-FULL-PRICE TO VAT-VALUE. MOVE VAT-VALUE TO OUTPUT1-VAT-VAL. RE-SORT-BY-DATE. SORT SORTWRK-FILE ASCENDING KEY SORTWRK-DATE USING OUTPUT1-FILE GIVING OUTPUT1-FILE. //GO.SORTOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING.HISTORY //GO.IN2 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING.CURRENT //GO.IN3 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING.NEW //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.MERGED,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=51,BLKSIZE=5100,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
Comments: - DFSORT in COBOL does not provide most of its functionality via SORT & MERGE statement. Duplicate removal is also not an option here. Because of that, you need to do it manually, PREVIOUS-RECORD variable is used for comparison current and previous records. If they match, the current record is skipped. - As shown in the RE-SORT-BY-DATE paragraph, you can specify the same file as both input and output in SORT operation. - SORT & MERGE statements do not require that record lengths of input and sort work file are equal. Work file can have larger records. In this example, SORTWRK has LRECL=51 and it's used in MERGE statements where input data has LRECL=40. Of course, that's possible only when OUTPUT PROCEDURE is coded. - In this program, SORT messages are routed to SORTOUT DD statement. It doesn't matter much but it's worth doing when you want to isolate messages written to SYSOUT by your program from the ones generated by DFSORT.
Intrinsic functions
Introduction
In this Assignment, you'll learn about the second type of functions available in COBOL, intrinsic functions. Intrinsic functions work similarly to functions in other programming languages. Each of them returns some value, almost all accept some arguments, and you can nest one function in another. Not all functions are covered in this Assignment. Some are discussed in earlier Assignments, some are not that interesting and new functions are added with nearly every new release of Enterprise COBOL. So always make sure you an appropriate documentation for your COBOL version and that you stay up to date with COBOL language updates.
Tasks
![]() 1. Calculate square of the natural logarithm, of the factorial, of the integer part, of the sum of three numbers: 1.3, 3.87, and 2.24.
- What's the difference between INTEGER and INTERGER-PART functions?
1. Calculate square of the natural logarithm, of the factorial, of the integer part, of the sum of three numbers: 1.3, 3.87, and 2.24.
- What's the difference between INTEGER and INTERGER-PART functions?
![]() 2. Define a 20 element table of decimal numbers between -200.00 to 200.00:
- Populate it with random numbers.
- Display the table.
- Display table statistics with following functions: SUM, MIN, MAX, MEAN, MEDIAN, RANGE, MIDRANGE, VARIANCE, STANDARD DEVIATION.
- Describe what each of those function does.
2. Define a 20 element table of decimal numbers between -200.00 to 200.00:
- Populate it with random numbers.
- Display the table.
- Display table statistics with following functions: SUM, MIN, MAX, MEAN, MEDIAN, RANGE, MIDRANGE, VARIANCE, STANDARD DEVIATION.
- Describe what each of those function does.
![]() 3. Define a 10 element table where each element is a single character:
- Populate the table using RANDOM and CHAR functions.
- Display the entire table and collating-sequence number of each element using ORD function.
- Use ORD-MIN and ORD-MAX functions to detect and display the first and the last character in the table in terms of collating-sequence.
3. Define a 10 element table where each element is a single character:
- Populate the table using RANDOM and CHAR functions.
- Display the entire table and collating-sequence number of each element using ORD function.
- Use ORD-MIN and ORD-MAX functions to detect and display the first and the last character in the table in terms of collating-sequence.
![]() 4. Write a program that processes following numerics:
- " - 123 . 43"
- "$ 23.99"
- "-2,621,323.232"
- "+22322.32212"
- "- .5"
- "321 322.62-"
- "-23 221.323 232"
- "+32.99-"
- Pre-process each numeric: remove all spaces and count how many '.' ',' '$' '+' '-' characters are in the string.
- Depending on the result of the above check display error message or use NUMVAL or NUMVAL-C functions to display the number in standard format.
- Also, display the result and the remainder of the operation X modulo 5 using both MOD and RET functions. What's the difference?
4. Write a program that processes following numerics:
- " - 123 . 43"
- "$ 23.99"
- "-2,621,323.232"
- "+22322.32212"
- "- .5"
- "321 322.62-"
- "-23 221.323 232"
- "+32.99-"
- Pre-process each numeric: remove all spaces and count how many '.' ',' '$' '+' '-' characters are in the string.
- Depending on the result of the above check display error message or use NUMVAL or NUMVAL-C functions to display the number in standard format.
- Also, display the result and the remainder of the operation X modulo 5 using both MOD and RET functions. What's the difference?
![]() 5. Write a program that accepts set of dates in YYMMDD format and:
- Set sliding century window as +10. In other words, if currently is 2018, date 280101 should be translated to 20280101 and date 290101 to 19290101.
- Display the date in following formats YYYYMMDD, YYYY-MM-DD, DD/MM/YYYY, YYDDD.
- Display the date 1000 days after given date.
- Display the difference in days between given date and the current date.
5. Write a program that accepts set of dates in YYMMDD format and:
- Set sliding century window as +10. In other words, if currently is 2018, date 280101 should be translated to 20280101 and date 290101 to 19290101.
- Display the date in following formats YYYYMMDD, YYYY-MM-DD, DD/MM/YYYY, YYDDD.
- Display the date 1000 days after given date.
- Display the difference in days between given date and the current date.
![]() 6. Modify the program from Task#5:
- This time accept the date in full form YYYYMMDD.
- Display internal integer representation of each date.
- Display what day of the week it was at a given date.
- Display what day of the week it will be this year on the same day and month as in the given date.
6. Modify the program from Task#5:
- This time accept the date in full form YYYYMMDD.
- Display internal integer representation of each date.
- Display what day of the week it was at a given date.
- Display what day of the week it will be this year on the same day and month as in the given date.
![]() 7. Display "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789,.;'!@$&*[]{}()+-=" in following encodings:
- EBCDIC Latin 2 (CCSID 870)
- UTF-16 (CCSID 1200)
- UTF-8 (CCSID 1208)
- ASCII ISO-8859-1 (CCSID 819)
- Windows Latin 1 (CCSID 1252)
7. Display "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789,.;'!@$&*[]{}()+-=" in following encodings:
- EBCDIC Latin 2 (CCSID 870)
- UTF-16 (CCSID 1200)
- UTF-8 (CCSID 1208)
- ASCII ISO-8859-1 (CCSID 819)
- Windows Latin 1 (CCSID 1252)
Hint 7
The national data type is CCSID 1200 so it's equal to UTF-16. All you need in this program is NATIONAL-OF and DISPLAY-OF functions.
Solution 1
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1201. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 77 RESULT PIC S9(15)V999. 77 RESULT-EDI PIC -(14)9.999. PROCEDURE DIVISION. MAIN-LOGIC. COMPUTE RESULT ROUNDED = FUNCTION SQRT( FUNCTION LOG( FUNCTION FACTORIAL( FUNCTION INTEGER( FUNCTION SUM(1.3, 3.87, 2.24 ))))) ON SIZE ERROR PERFORM COMPUTE-OVERFLOW. MOVE RESULT TO RESULT-EDI. DISPLAY "RESULT: " RESULT-EDI. COMPUTE RESULT = FUNCTION INTEGER(-2.5) MOVE RESULT TO RESULT-EDI. DISPLAY "INTEGER: " RESULT-EDI. COMPUTE RESULT = FUNCTION INTEGER-PART(-2.5) MOVE RESULT TO RESULT-EDI. DISPLAY "INTEGER-PART: " RESULT-EDI. STOP RUN. COMPUTE-OVERFLOW. DISPLAY "OVERFLOW OCCURED. PROGRAM ENDS.". MOVE 8 TO RETURN-CODE. STOP RUN.
Output:
RESULT: 2.920 INTEGER: -3.000 INTEGER-PART: -2.000
Comments: - A big advantage of intrinsic functions over statements discussed in "Standard functions" Assignment is that you nest them together. In other words, the result of the one function becomes argument for another. Of course, when using intrinsic functions in that manner you must make sure that returned value data type is the same as an argument which this function supplies. - INTEGER and INTEGER-PART function work the same way on numbers above zero. The difference appears when working on negative numbers as you can see in the output. INTEGER-PART simply trims digits after the decimal point, INTEGER on the other hand returns closes integer number that is less than or equal to the argument.
Solution 2
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1202. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM-TAB. 05 NUM OCCURS 20 TIMES PIC S999V99. 77 NUM-EDI PIC ---9.99. 77 K1 PIC 9(4) COMP. 77 RAND-NUM PIC S9(9)V9(9) COMP. 77 RAND-SEED PIC 9(9) COMP. 77 STAT-NUM PIC S9(15)V999. 77 STAT-NUM-EDI PIC -(14)9.999. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM POPULATE-THE-TABLE. PERFORM DISPLAY-THE-TABLE. PERFORM DISPLAY-TABLE-STATISTICS. STOP RUN. POPULATE-THE-TABLE. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 20 COMPUTE RAND-SEED = FUNCTION NUMVAL( FUNCTION CURRENT-DATE(9 : 8) ) * K1 - K1 END-COMPUTE COMPUTE RAND-NUM = FUNCTION RANDOM(RAND-SEED) COMPUTE RAND-NUM = RAND-NUM * 400 - 200 MOVE RAND-NUM TO NUM(K1) END-PERFORM. DISPLAY-THE-TABLE. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 20 MOVE NUM(K1) TO NUM-EDI DISPLAY "NUM " K1 ": " NUM-EDI END-PERFORM. DISPLAY-TABLE-STATISTICS. COMPUTE STAT-NUM = FUNCTION SUM(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "SUM: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION MIN(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "MIN: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION MAX(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "MAX: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION MEAN(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "MEAN: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION MEDIAN(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "MEDIAN: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION RANGE(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "RANGE: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION MIDRANGE(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "MIDRANGE: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION VARIANCE(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "VARIANCE: " STAT-NUM-EDI. COMPUTE STAT-NUM = FUNCTION STANDARD-DEVIATION(NUM(ALL)) ON SIZE ERROR PERFORM SIZE-ERROR-PROC. MOVE STAT-NUM TO STAT-NUM-EDI. DISPLAY "STANDARD DEVIATION: " STAT-NUM-EDI. SIZE-ERROR-PROC. DISPLAY "OVERFLOW ERROR. PROGRAM ENDS.". MOVE 8 TO RETURN-CODE. STOP RUN.
Comments: - RANDOM is really a pseudo-random function. This means that you must use different seed in each iteration to get truly random results. Random in the scope of the current execution of the program. To make it random for each program invocation you must use seed that varies across invocations of the program. The CURRENT-DATE function is usually used for this purpose. - If you want to reference all table elements in Intrinsic functions you can use ALL keyword. - SUM – Returns the sum off all values in the array. - MIN – Returns the lowest value in the array. - MAX – Returns the highest value in the array. - MEAN – Returns average – SUM(table elements)/number of elements. - MEDIAN – Returns the middle table element (in sorter order). If the table has even number of elements MEDIAN returns the average of two middle values. - RANGE – Returns the difference between the lowest and the highest values – ABS(MIN(table)) + ABS(MAX(table)). - MIDRANGE – Returns the middle value between the lowest and the highest values – (MIN(table) + MAX(table)) / 2. - VARIANCE – SUM(table elements^2)/number of elements. - STANDARD DEVIATION – Square root of VARIANCE.
Solution 3
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1203. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 CHAR-TAB. 05 CHAR OCCURS 10 TIMES PIC X. 77 INTEGER PIC 9(4) COMP. 77 K1 PIC 9(4) COMP. 77 RAND-NUM PIC S9(9)V9(9) COMP. 77 RAND-SEED PIC 9(9) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM POPULATE-THE-TABLE. PERFORM DISPLAY-THE-TABLE. PERFORM DISPLAY-FIRST-AND-LAST. STOP RUN. POPULATE-THE-TABLE. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 10 COMPUTE RAND-SEED = FUNCTION NUMVAL( FUNCTION CURRENT-DATE(9 : 8) ) * K1 - K1 END-COMPUTE COMPUTE RAND-NUM = FUNCTION RANDOM(RAND-SEED) COMPUTE INTEGER = RAND-NUM * 256 MOVE FUNCTION CHAR(INTEGER) TO CHAR(K1) END-PERFORM. DISPLAY-THE-TABLE. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 10 COMPUTE INTEGER = FUNCTION ORD(CHAR(K1)) DISPLAY "CHAR " K1 ": " CHAR(K1) ", COL-SEQ-NBR: " INTEGER END-PERFORM. DISPLAY-FIRST-AND-LAST. COMPUTE INTEGER = FUNCTION ORD-MIN(CHAR(ALL)). DISPLAY "MIN: " CHAR(INTEGER). COMPUTE INTEGER = FUNCTION ORD-MAX(CHAR(ALL)). DISPLAY "MAX: " CHAR(INTEGER).
Comments: - CHAR, ORD, ORD-MIN, and ORD-MAX are four functions you can use to dynamically detect collating sequence order in your program. - Remember that if you have problems with conditional expression or sort because of collating-sequence usually defining your own ALPHABET is the best and simplest solution.
Solution 4
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1204. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 NUM-TAB. 05 NUM-STR OCCURS 8 TIMES PIC X(15). 77 COMP-NUM PIC S9(12)V9(6) COMP. 77 COMP-NUM-EDI PIC -(11)9.9(6). 77 K1 PIC 9(4) COMP. 77 K2 PIC 9(4) COMP. 77 T1 PIC 9(4) COMP. 77 T2 PIC 9(4) COMP. 77 STR-LEN PIC 9(4) COMP. 77 N-MINUS PIC 9(4) COMP. 77 N-PLUS PIC 9(4) COMP. 77 N-SIGN PIC 9(4) COMP. 77 N-COMMA PIC 9(4) COMP. 77 N-DOT PIC 9(4) COMP. 77 N-CURRENCY PIC 9(4) COMP. 77 N-SPACES PIC 9(4) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM POPULATE-THE-TABLE. PERFORM CHECK-AND-DISPLAY. STOP RUN. POPULATE-THE-TABLE. MOVE " - 123 . 43" TO NUM-STR(1). MOVE "$ 23.99" TO NUM-STR(2). MOVE "-2,621,323.232" TO NUM-STR(3). MOVE "+22322.32212" TO NUM-STR(4). MOVE "- .5" TO NUM-STR(5). MOVE "321 322.62-" TO NUM-STR(6). MOVE "-23 221.323 232" TO NUM-STR(7). MOVE "+32.99-" TO NUM-STR(8). CHECK-AND-DISPLAY. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > 8 D DISPLAY "CHECKING '" NUM-STR(K1) "'" PERFORM PRE-PROCESS-THE-NUMBER IF N-SIGN > 1 OR N-CURRENCY > 1 DISPLAY NUM-STR(K1) " IS INVALID." ELSE PERFORM REMOVE-SPACES IF N-SPACES = 0 PERFORM DISPLAY-THE-NUMBER ELSE DISPLAY NUM-STR (K1) " IS INVALID." END-IF END-IF END-PERFORM. PRE-PROCESS-THE-NUMBER. MOVE 0 TO N-MINUS N-PLUS N-COMMA N-DOT N-CURRENCY N-SPACES N-SIGN. INSPECT NUM-STR(K1) TALLYING N-MINUS FOR ALL '-'. INSPECT NUM-STR(K1) TALLYING N-PLUS FOR ALL '+'. INSPECT NUM-STR(K1) TALLYING N-COMMA FOR ALL ','. INSPECT NUM-STR(K1) TALLYING N-DOT FOR ALL '.'. INSPECT NUM-STR(K1) TALLYING N-CURRENCY FOR ALL '$'. INSPECT NUM-STR(K1) TALLYING N-SPACES FOR ALL ' '. COMPUTE N-SIGN = N-MINUS + N-PLUS. REMOVE-SPACES. PERFORM VARYING K2 FROM 1 BY 1 UNTIL N-SPACES = 0 OR K2 > 15 COMPUTE STR-LEN = 16 - K2 IF NUM-STR(K1)(K2 : 1) = SPACE COMPUTE T1 = K2 + 1 COMPUTE T2 = STR-LEN - 1 MOVE NUM-STR(K1)(T1 : T2) TO NUM-STR(K1)(K2 : STR-LEN) SUBTRACT 1 FROM N-SPACES END-IF END-PERFORM. D DISPLAY "SPACES REMOVED: " NUM-STR(K1). DISPLAY-THE-NUMBER. COMPUTE COMP-NUM = FUNCTION NUMVAL-C(NUM-STR(K1)). MOVE COMP-NUM TO COMP-NUM-EDI. DISPLAY "THE NUMBER: " COMP-NUM-EDI. COMPUTE COMP-NUM = COMP-NUM / 5. MOVE COMP-NUM TO COMP-NUM-EDI. DISPLAY "- X / 5 : " COMP-NUM-EDI. COMPUTE COMP-NUM = FUNCTION REM( FUNCTION INTEGER-PART(COMP-NUM) 5). MOVE COMP-NUM TO COMP-NUM-EDI. DISPLAY "- REMINDER: " COMP-NUM-EDI. COMPUTE COMP-NUM = FUNCTION MOD( FUNCTION INTEGER-PART(COMP-NUM) 5). MOVE COMP-NUM TO COMP-NUM-EDI. DISPLAY "- MODULO : " COMP-NUM-EDI.
Comments: - NUMVAL-C is basically the same thing as NUMVAL but also can process currency sign. Both functions have similar limitations so sometimes they may require some pre-processing option. For example, both functions don't allow spaces in the numeric. - The difference between MOD and RET is the same as between INTEGER and INTEGER-PART. It matters only when working on negative numbers. In Language Reference you can find: MOD: argument-1 - (argument-2 * FUNCTION INTEGER (argument-1 / argument-2)) REM: argument-1 - (argument-2 * FUNCTION INTEGER-PART (argument-1 / argument-2))
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1205. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 INPUT-DATE. 05 IN-YEAR PIC XX. 05 IN-MONTH PIC XX. 05 IN-DAY PIC XX. 01 INPUT-DATE-INT REDEFINES INPUT-DATE PIC 9(6). 01 CURRENT-DATE. 05 C-YEAR PIC 9(4). 05 C-MONTH PIC 9(2). 05 C-DAY PIC 9(2). 05 C-TIME PIC X(13). 01 TEMP-DATE. 05 T-YEAR PIC 9(4). 05 T-MONTH PIC 9(2). 05 T-DAY PIC 9(2). 01 TEMP-DATE-INT REDEFINES TEMP-DATE PIC 9(8). 77 CENTURY-BORDER PIC 99. 77 INTERNAL-DATE PIC S9(9) COMP. 77 INTERNAL-DATE2 PIC S9(9) COMP. 77 INTERNAL-DATE-EDI PIC -(8)9. PROCEDURE DIVISION. MAIN-LOGIC. MOVE FUNCTION CURRENT-DATE TO CURRENT-DATE. MOVE 10 TO CENTURY-BORDER. PERFORM ACCEPT-THE-DATE. PERFORM DISPLAY-DATE-STUFF UNTIL INPUT-DATE = LOW-VALUES. STOP RUN. ACCEPT-THE-DATE. MOVE LOW-VALUES TO INPUT-DATE. ACCEPT INPUT-DATE. DISPLAY-DATE-STUFF. PERFORM DISPLAY-VARIOUS-DATE-FORMATS. PERFORM DISPLAY-DATE-AFTER-1000-DAYS. PERFORM DISPLAY-DIFFERENCE-WITH-TODAY. PERFORM ACCEPT-THE-DATE. DISPLAY-VARIOUS-DATE-FORMATS. DISPLAY "INPUT: " INPUT-DATE-INT. COMPUTE TEMP-DATE-INT = FUNCTION DATE-TO-YYYYMMDD( INPUT-DATE-INT CENTURY-BORDER). DISPLAY "- YYYYMMDD: " TEMP-DATE. DISPLAY "- YYYY-MM-DD: " T-YEAR "-" T-MONTH "-" T-DAY. DISPLAY "- DD/MM/YYYY: " T-DAY "/" T-MONTH "/" T-YEAR. COMPUTE INTERNAL-DATE = FUNCTION INTEGER-OF-DATE(TEMP-DATE-INT). COMPUTE TEMP-DATE-INT = FUNCTION DAY-OF-INTEGER(INTERNAL-DATE). DISPLAY "- YYDDD: " TEMP-DATE(4 : 5). DISPLAY-DATE-AFTER-1000-DAYS. COMPUTE TEMP-DATE-INT = FUNCTION DATE-OF-INTEGER( FUNCTION INTEGER-OF-DATE( FUNCTION DATE-TO-YYYYMMDD( INPUT-DATE-INT CENTURY-BORDER )) + 1000). DISPLAY "- AFTER 1000 DAYS: " TEMP-DATE. DISPLAY-DIFFERENCE-WITH-TODAY. COMPUTE TEMP-DATE-INT = FUNCTION DATE-TO-YYYYMMDD( INPUT-DATE-INT CENTURY-BORDER). COMPUTE INTERNAL-DATE = FUNCTION INTEGER-OF-DATE(TEMP-DATE-INT). COMPUTE INTERNAL-DATE2 = FUNCTION NUMVAL(CURRENT-DATE(1 : 8)). COMPUTE INTERNAL-DATE2 = FUNCTION INTEGER-OF-DATE(INTERNAL-DATE2). COMPUTE INTERNAL-DATE2 = INTERNAL-DATE2 - INTERNAL-DATE. MOVE INTERNAL-DATE2 TO INTERNAL-DATE-EDI. DISPLAY "- DIFFERENCE WITH TODAY [DAYS]: " INTERNAL-DATE-EDI. //GO.SYSIN DD * 990203 180304 161201 280506 290125
Output:
INPUT: 990203 - YYYYMMDD: 19990203 - YYYY-MM-DD: 1999-02-03 - DD/MM/YYYY: 03/02/1999 - YYDDD: 99034 - AFTER 1000 DAYS: 20011030 - DIFFERENCE WITH TODAY [DAYS]: 7033 INPUT: 180304 - YYYYMMDD: 20180304 - YYYY-MM-DD: 2018-03-04 - DD/MM/YYYY: 04/03/2018 - YYDDD: 18063 - AFTER 1000 DAYS: 20201128 - DIFFERENCE WITH TODAY [DAYS]: 64 INPUT: 161201 - YYYYMMDD: 20161201 - YYYY-MM-DD: 2016-12-01 - DD/MM/YYYY: 01/12/2016 - YYDDD: 16336 - AFTER 1000 DAYS: 20190828 - DIFFERENCE WITH TODAY [DAYS]: 522 INPUT: 280506 - YYYYMMDD: 20280506 - YYYY-MM-DD: 2028-05-06 - DD/MM/YYYY: 06/05/2028 - YYDDD: 28127 - AFTER 1000 DAYS: 20310131 - DIFFERENCE WITH TODAY [DAYS]: -3652 INPUT: 290125 - YYYYMMDD: 19290125 - YYYY-MM-DD: 1929-01-25 - DD/MM/YYYY: 25/01/1929 - YYDDD: 29025 - AFTER 1000 DAYS: 19311022 - DIFFERENCE WITH TODAY [DAYS]: 32609
Comments: - COBOL doesn't have DATE data type so dates are stored and processed as strings or numbers. - Fortunately, there are a few intrinsic functions that make date-related operations easy. Many of them, like adding a number of days to a given date requires converting the date to an internal format, where 1601-01-01 is represented as 1, 1601-02-01 as 32 and so on. - When doing date-related operations, it's best to use zoned-decimal variables. They can be used in date related function and are easily displayable. Using zoned-decimal representation also enables you to define the date as a structure and then use REDEFINE keyword to represent it as a numeric, this way you can easily work on the date as both number and string. - In the DISPLAY-DATE-AFTER-1000-DAYS paragraph, you can see how you can nest date functions to add a number of days to a given date. Important: - INTDATE compiler option defines the starting date for internal integer format. By default, 1601-01-01 is used but you can change it to ANSI standard where 1582-10-15 is represented as 1.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1206. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 INPUT-DATE. 05 IN-YEAR PIC 9(4). 05 IN-MONTH PIC 9(2). 05 IN-DAY PIC 9(2). 01 INPUT-DATE-INT REDEFINES INPUT-DATE PIC 9(8). 77 INTERNAL-DATE PIC 9(9) COMP. 01 WEEKDAY PIC 9. 88 MONDAY VALUE 1. 88 TUESDAY VALUE 2. 88 WEDNESDAY VALUE 3. 88 THURSDAY VALUE 4. 88 FRIDAY VALUE 5. 88 SATURDAY VALUE 6. 88 SUNDAY VALUE 7. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ACCEPT-THE-DATE. PERFORM DISPLAY-DATE-STUFF UNTIL INPUT-DATE = LOW-VALUES. STOP RUN. ACCEPT-THE-DATE. MOVE LOW-VALUES TO INPUT-DATE. ACCEPT INPUT-DATE. DISPLAY-DATE-STUFF. DISPLAY "INPUT: " IN-YEAR "-" IN-MONTH "-" IN-DAY. PERFORM DISPLAY-DATE-INTERNAL-FORMAT. PERFORM DISPLAY-DAY-OF-WEEK. PERFORM DISPLAY-DAY-OF-WEEK-2018. PERFORM ACCEPT-THE-DATE. DISPLAY-DATE-INTERNAL-FORMAT. COMPUTE INTERNAL-DATE = FUNCTION INTEGER-OF-DATE(INPUT-DATE-INT). DISPLAY "- INTERAL FORMAT: " INTERNAL-DATE. DISPLAY-DAY-OF-WEEK. COMPUTE WEEKDAY = FUNCTION REM(INTERNAL-DATE 7). IF WEEKDAY = 0 MOVE 7 TO WEEKDAY. DISPLAY "- DAY OF WEEK: " WEEKDAY. PERFORM CHECK-DAY-NAME. DISPLAY-DAY-OF-WEEK-2018. MOVE 2018 TO IN-YEAR. COMPUTE INTERNAL-DATE = FUNCTION INTEGER-OF-DATE(INPUT-DATE-INT). COMPUTE WEEKDAY = FUNCTION REM(INTERNAL-DATE 7). IF WEEKDAY = 0 MOVE 7 TO WEEKDAY. DISPLAY "- " INPUT-DATE " DAY: " WEEKDAY. PERFORM CHECK-DAY-NAME. CHECK-DAY-NAME. EVALUATE TRUE WHEN MONDAY DISPLAY "- IT IS MONDAY" WHEN TUESDAY DISPLAY "- IT IS TUESDAY" WHEN WEDNESDAY DISPLAY "- IT IS WEDNESDAY" WHEN THURSDAY DISPLAY "- IT IS THURSDAY" WHEN FRIDAY DISPLAY "- IT IS FRIDAY" WHEN SATURDAY DISPLAY "- IT IS SATURDAY" WHEN SUNDAY DISPLAY "- IT IS SUNDAY" WHEN OTHER DISPLAY "ERROR - INCORRECT WEEKDAY" STOP RUN END-EVALUATE. //GO.SYSIN DD * 19990203 16010101 16020101 20180508 20280506 19290125
Comments: - In COBOL language there is no function that displays what day of the week it was on a given date, only DAY-OF-WEEK ACCEPT keyword which shows the current day. Fortunately, there is a trick to do that. Integer date representation is the day count since 1601-01-01. This day was Monday. So you can use the remainder of a division of integer date representation to check what day of the week it was on any date. - Sunday is the 7th day so the remainder is 0. You can use zero to represent Sundays in your program but it's better to change it to 7 to make it more intuitive.
Solution 7
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1207. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 STR PIC X(80). 01 STR-NAT PIC N(80). PROCEDURE DIVISION. MAIN-LOGIC. MOVE "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ012 - "3456789,.;'!@$&*[]{}()+-=" TO STR. DISPLAY "EBCDIC (870): " STR. MOVE FUNCTION NATIONAL-OF(STR 1140) TO STR-NAT. DISPLAY "UTF-16 (1200): " STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT 1208) TO STR. DISPLAY "UTF-8 (1208): " STR. MOVE FUNCTION DISPLAY-OF(STR-NAT 819) TO STR. DISPLAY "ASCII (819): " STR. MOVE FUNCTION DISPLAY-OF(STR-NAT 1252) TO STR. DISPLAY "WINDOWS-1252 (1252): " STR. STOP RUN.
Comments: - The above program isn't particularly useful, it simply demonstrates how NATIONAL-OF and DISPLAY-OF character sets are used. - There are hundreds of character encodings, many country-specific. Still, the five CCSIDs presented in this program are among the most popular so you should remember them: CCSID 870, 1200, 1208, 819, and 1252. Important: - Unicode character sets (UTF-8 and UTF-16) are variable character encoding formats. In other words, a UTF-8 character can have 1, 2, 3, or 4 bytes depending on the character. Thanks to that you can store all possible characters in a single format and with minimal space usage. But this length-variability also introduces some problems, for example, it's hard to calculate the length of the string with variable-length characters. To solve such problems, in COBOL 5.1 U* (ULENGTH, UWIDTH etc) functions were introduced.
Working with DB2 – Part I – Basics
Introduction
COBOL is a language designed for efficient data processing. That's why a COBOL programmer must be also a skilled database administrator. In the older days, COBOL communicated with IMS software which is also used in many companies. But, nowadays DB2 + CICS solution is more popular. This is the first Assignment in which you'll learn how to communicate with DB2 from your COBOL programs. Basic SQL knowledge is a must when writing such programs. COBOL programs that work with DB2 must be executed via DB2 API, which requires a special compilation process. There are two ways to compile a DB2 program, with the use of pre-compiler and co-processor. The first seven Tasks use pre-compiler, the last one demonstrates compilation process via co-processor. Regarding program functionality, all programs perform the simplest SELECT queries. More practical and complex database-related tasks will be discussed in "Working with DB2 – Part II".
Tasks
![]() 1. Describe in detail process of compiling COBOL DB2 program with use of pre-processor. Also, explain following DB2 terms:
- Package
- Access Path
- Application Plan
- Collection
- Version
- DB2 RUN command
- DB2 DCLGEN command
1. Describe in detail process of compiling COBOL DB2 program with use of pre-processor. Also, explain following DB2 terms:
- Package
- Access Path
- Application Plan
- Collection
- Version
- DB2 RUN command
- DB2 DCLGEN command
![]() 2. Create a test database and populate it with data as follows:
2. Create a test database and populate it with data as follows:
CREATE TABLE JSADEK.DOGS ( RACE VARCHAR(10), NAME VARCHAR(10), OWNER_ID INTEGER ) IN DATABASE JANSDB ; CREATE TABLE JSADEK.OWNERS ( OWNER_ID INTEGER, NAME VARCHAR(10) ) IN DATABASE JANSDB ; INSERT INTO DOGS SELECT 'HUSKY','LILLY',1 FROM SYSIBM.SYSDUMMY1 UNION ALL SELECT 'GREYHOUND','JACK',1 FROM SYSIBM.SYSDUMMY1 UNION ALL SELECT 'YORK','DUMMY',2 FROM SYSIBM.SYSDUMMY1 UNION ALL SELECT 'BEAGLE','FLUFFY',4 FROM SYSIBM.SYSDUMMY1 ; INSERT INTO OWNERS SELECT 1,'JONATHAN' FROM SYSIBM.SYSDUMMY1 UNION ALL SELECT 2,'DONALD' FROM SYSIBM.SYSDUMMY1 UNION ALL SELECT 3,'SARAH' FROM SYSIBM.SYSDUMMY1 ;
- Write a COBOL program that SELECTs RACE of a dog whose OWNER_ID = 2.
- Create a job that performs all steps necessary to compile and run it.
![]() 3. Modify program from Task#2:
- Create a collection and a plan that you'll use for all Tasks in this Assignment so you could skip BIND PLAN step when compiling your programs.
- Allow the user to specify dog NAME. On its basis read and display an appropriate record from DOGS table and also related record in OWNERS table (if exists).
3. Modify program from Task#2:
- Create a collection and a plan that you'll use for all Tasks in this Assignment so you could skip BIND PLAN step when compiling your programs.
- Allow the user to specify dog NAME. On its basis read and display an appropriate record from DOGS table and also related record in OWNERS table (if exists).
![]() 4. Write a program that copies all rows from DOGS table to COBOL array:
- Use cursor and single-row fetch.
- Copy fetched row into the table. Copy text fields in EBCDIC form.
- Display how many rows were copied and display all the records in the array.
- Detect last read record dynamically (don't use COUNT(*)).
- Test your program in following situations: received records < table size, received records = table size, received records > table size, received records = 0.
4. Write a program that copies all rows from DOGS table to COBOL array:
- Use cursor and single-row fetch.
- Copy fetched row into the table. Copy text fields in EBCDIC form.
- Display how many rows were copied and display all the records in the array.
- Detect last read record dynamically (don't use COUNT(*)).
- Test your program in following situations: received records < table size, received records = table size, received records > table size, received records = 0.
![]() 5. Modify program from Task#4:
- Instead of DCLGEN definition use a standard COBOL array that will store only two columns: dog name and owner ID.
- This time use COUNT(*) instruction to check if query result will fit into the array.
- Use DEPENDING ON clause to define table size.
- Test your program in following situations: received records < table size, received records = table size, received records > table size, received records = 0.
- Also, test a situation in which records are added or removed between SELECT COUNT(*) and FETCH instructions.
5. Modify program from Task#4:
- Instead of DCLGEN definition use a standard COBOL array that will store only two columns: dog name and owner ID.
- This time use COUNT(*) instruction to check if query result will fit into the array.
- Use DEPENDING ON clause to define table size.
- Test your program in following situations: received records < table size, received records = table size, received records > table size, received records = 0.
- Also, test a situation in which records are added or removed between SELECT COUNT(*) and FETCH instructions.
![]() 6. Create a program that:
- Displays two columns from SYSIBM.SYSTABLES, NAME and COLCOUNT.
- Uses multi-row FETCH to process and display 50 records at a time.
- Define column definitions manually.
6. Create a program that:
- Displays two columns from SYSIBM.SYSTABLES, NAME and COLCOUNT.
- Uses multi-row FETCH to process and display 50 records at a time.
- Define column definitions manually.
![]() 7. Copy the entire SYSIBM.SYSPACKLIST table to sequential file with RECFM=VB in CSV format:
- The program should run with parameter "EBCDIC" or "ASCII" and save the file in appropriate coding.
- Include a header.
- Copy numerics in a readable format.
- Trim leading and trailing spaces in all fields.
- Download the file and open it in Excel or its equivalent as a final test.
7. Copy the entire SYSIBM.SYSPACKLIST table to sequential file with RECFM=VB in CSV format:
- The program should run with parameter "EBCDIC" or "ASCII" and save the file in appropriate coding.
- Include a header.
- Copy numerics in a readable format.
- Trim leading and trailing spaces in all fields.
- Download the file and open it in Excel or its equivalent as a final test.
![]() 8. Compile the program from Task#7 with DB2 co-processor using SQLCCSID and then NOSQLCCSID options:
- Check if both ASCII and EBCDIC files were correctly generated with both options.
- Describe the difference between SQLCCSID and NOSQLCCSID options.
- Modify your program so it works correctly with SQLCCSID compiler option.
8. Compile the program from Task#7 with DB2 co-processor using SQLCCSID and then NOSQLCCSID options:
- Check if both ASCII and EBCDIC files were correctly generated with both options.
- Describe the difference between SQLCCSID and NOSQLCCSID options.
- Modify your program so it works correctly with SQLCCSID compiler option.
Hint 1
The entire process is described in detail in "Chapter 18. Preparing an application to run on Db2 for z/OS" of "DB2 for z/OS: Application Programming and SQL Guide". The entire process consists of seven steps: - Generate DCLGEN definitions - Pre-compile - Compile - Link-edit - Bind Package - Bind Plan - Run the program
Hint 2
SQL statements in COBOL are always enclosed in "EXEC SQL ... END-EXEC" clause. EXEC SQL clause must start in Area B. Remember to INCLUDE SQLCA in your code. Documentation: - Description of DCLGEN command (DCLGEN step): "DB2 for z/OS: Command Reference" document, "DCLGEN (DECLARATIONS GENERATOR)" chapter. - Description of DSNHPC parameters (Pre-compile step): "DB2 for z/OS: Application Programming and SQL Guide" document, "Options for SQL statement processing" sub-chapter. - Description of IGYCRCTL parameters (Compile step): "Enterprise COBOL for z/OS: Programming Guide" document, "Compiler options" chapter. - Description of IEWL parameters (Link-edit step): "z/OS MVS Program Management: User's Guide and Reference" document, "Binder options reference" chapter. - Description of BIND PACKAGE command (Bind Package step): "DB2 for z/OS: Command Reference" document, "BIND PACKAGE" chapter. - Description of BIND PLAN command (Bind Plan step): "DB2 for z/OS: Command Reference" document, "BIND PLAN" chapter. - Description of RUN command (Run step): "DB2 for z/OS: Command Reference" document, "RUN" chapter.
Hint 3
In this Task you'll have duplicate variable names NAME and OWNER-ID. You can use OF keyword to refer to the specific structure.
Hint 4
You'll have to use DB2 cursor and FETCH instruction. You can read more about those statements in "DB2 for z/OS: SQL Reference". The cursor reads sequentially records from the given query. When going through the last record there, the cursor will attempt another read and since no more records are present it will return SQL code = 100. You can use this code to detect the last record in the query.
Hint 5
In this exercise, you'll have to map DB2 column definition to PIC clause manually. In "Equivalent SQL and COBOL data types" chapter in "DB2 for z/OS: Application Programming and SQL Guide" document you can see how SQL data types are mapped to COBOL data types.
Hint 6
SQLCA can be used for controlling multi-row FETCH. When the last record is read SQLCODE will equal 100. SQLERRD(3) stores number of rows actually read during FETCH.
Hint 8
Read "COBOL and DB2 CCSID determination" chapter in "Enterprise COBOL for z/OS: Programming Guide".
Solution 1
You can see a package as a set of compiled SQL statements. The term "compilation" doesn't really apply here but a package is an executable form of SQL code. An important characteristic of a package is access path. The package is created on the basis of SQL statement included in source code. During execution, the program issues SQL statements by running them from a package. Package definitions are stored in DB2 catalogue in SYSIBM.SYSPACKAGE table. There are two basic types of packages: - Embedded SQL packages – the ones generated for your programs. - DB2 system packages – set of ready to use SQL modules used by DB2 itself. Access Path as the name suggests is the path used for accessing a specific data in the table. In other words, it defines how the data should be accessed and passed between your program and DB2 tables in the most efficient way. It defines what access method is used, what indexes and tables used. Application Plan is a set of collections. It also defines how packages in those collections are executed. To use any package it must be included in some plan. Definitions for plans are stored in SYSIBM.SYSPLAN. A collection is a grouping of packages. You can use the collection to specify common BIND and execution parameters for many packages. If you don't specify any collection a new one will be created with the name of the package. Basically, it goes like that: Plan consists of zero or more collections. Collection consists of one or more packages. A package consists of one or more executable SQL statements. For a better understanding, it's a good idea to do following queries. Let's assume you need to use DSN2TEP2 program. DSNTEP2 is an example of a package shipped with DB2. First, you must find out the collection to which it belongs: SELECT * FROM SYSIBM.SYSPACKAGE WHERE NAME = 'DSNTEP2'; Now that you have a collection name you can check to which Plan it belongs: SELECT * FROM SYSIBM.SYSPACKLIST WHERE COLLID = 'DSNTEP2'; To see how this package will be executed you should check columns in SYSPLAN table: SELECT * FROM SYSIBM.SYSPLAN WHERE NAME = 'DSNTEP91'; Version is a different version of a package. Packages can have duplicated names so you can store many different packages with different parameters or just as a backup copy. The RUN command is a DB2 command that can be also run via TSO. It allows you to run a program that uses DB2 packages or any other program that's part of DB2 such as DSNTEP2. DCLGEN command can be also run via TSO. This command generates variable definitions for columns of a selected DB2 table. It supports COBOL, PL/I, C, and C++. The following graph is taken from "DB2 Developers Guide (5th Edition)" book. It nicely shows all steps needed for creation of COBOL program that communicates with DB2. Rectagles visualize objects (data sets) while rounded rectangles activities needed.
Here is the short description of all steps presented in that figure: 1. Generating DCLGEN definitions. - The DCLGEN program is executed to produce table definitions. When you are working on any table you will need a structure, a set of variables that are mapped to specific columns in the DB2 table. Doing it manually would require a lot of time. The DCLGEN program does that for us. Input: - Table definition from DB2 catalogue tables. Output: - Variable definitions for all columns in the table. 2. Pre-compile. - INCLUDE statement are expanded. - SQL statements inside COBOL code are syntax-checked. - DBRM is produced. DBRM (Database Request Module) is data set that stores serialized SQL statements from your program. - SQL statements in COBOL source are replaced by CALL command. Now that SQL statements were copied to DBRM they can be removed from COBOL source. This needs to be done because most compilers do not recognize SQL statements. Instead, the program will issue CALL commands that execute a particular set of SQL statements from a package (the package will be later created on the basis of this DBRM). - Timestamp for modified source code and DBRM is saved. This is a security mechanism to make sure that your COBOL program executes the correct version of SQL statements. Input: - COBOL source code with SQL statements. - DCLGEN. Output: - Modified source code. With included DCLGEN definitions & EXEC SQL replaced with CALL. - DBRM. 3. Compile. - The normal compilation process you've done many times. During it, COBOL source code is converted into machine code. Input: - Modified source code. Output: - Object module. 4. Link-edit. - The normal linking process you've done many times. During it, all sub-programs for static calls, class definitions and so on, are added to object module from compilation process. Input: - Object module from the compilation step. - All other objects that are required for correct execution of the program. Output: - Load module. 5. Bind Package. - In this step SQL code from DBRM package is verified with DB2. DB2 checks the SQL for two main reasons. - The first reason is error checking. Pre-compilation step didn't have access to DB2 so it could verify only SQL syntax. Now DB2 performs much more complex checks, for example, if table and column names are correct, or if SQL functions will be done on the correct data type. - The second reason is optimization. DB2 Optimizer checks what your SQL statement do and figures out the most optimal way to perform such activity. For example, if a table has few indexes it checks which one will provide the fastest access to the requested data. On this basis Access Path is created. - In result, a Package is created. It is a ready to use, "compiled" SQL with Access Path definition. Input: - DBRM from the pre-compilation step. Output: - A Package. An executable version of SQL statements with Access Path definition. - Entry in SYSIBM.SYSPACKAGE. 6. Bind Plan. - Plan is a collection of packages, or to be more specific, collection of collections. It also defines how packages in it are executed. - Plan is just an entry in DB2 catalog. No data set is produced in this step. Input: - The package. - Entry in SYSIBM.SYSPACKAGE. Output: - Entry in SYSIBM.SYSPLAN & SYSIBM.SYSPACKLIST. 7. Run the program. - You cannot run COBOL program that uses packages as a normal program. Instead, you must execute it via DB2 RUN command specifying the plan to which the package belongs. Comments regarding the entire process: - DCLGEN step is not usually part of the process. In software development environment, there should be ready to use DCLGEN outputs for all tables that are used by the developed software. All you need to know is where they are stored. - Pre-compilation step can be also skipped. Nowadays DB2 is shipped with co-processor that performs activities from pre-compilation step at a compile time. - Bind plan step can be also skipped. To do that, you must add a package into existing collection and by that existing plan. - DB2 must be online in four steps: DCLGEN, Bind Package, Bind Plan, and during program execution. - DBRM, DCLGEN and Modified source are members that can be specified as temporary files. It's may be a good idea for DBRM and modified source but you should have a library with DCLGEN definition. Table definitions are changed very rarely so rerunning this step each time is just a waste of resources. - The entire process can be done via DB2I panels, but as usual, the batch job is faster and easier solution.
Solution 2
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. TEST1. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE DOGS END-EXEC. EXEC SQL INCLUDE SQLCA END-EXEC. 77 RACE-ASCII PIC X(10). 77 RACE-NAT PIC N(10). 77 RACE-EBCDIC PIC X(10). 77 NUM-EDI PIC -(17)9. PROCEDURE DIVISION. EXEC SQL SELECT RACE INTO :RACE-ASCII FROM DOGS WHERE OWNER_ID = 2 END-EXEC. EXEC SQL COMMIT END-EXEC. MOVE FUNCTION NATIONAL-OF(RACE-ASCII, 819) TO RACE-NAT. MOVE FUNCTION DISPLAY-OF(RACE-NAT, 1140) TO RACE-EBCDIC. DISPLAY "RACE-ASCII >>>" RACE-ASCII "<<<". DISPLAY "RACE-NAT >>>" RACE-NAT "<<<". DISPLAY "RACE-EBCDIC>>>" RACE-EBCDIC "<<<". PERFORM DISPLAY-SQL-INFO. STOP RUN. DISPLAY-SQL-INFO. MOVE SQLCODE TO NUM-EDI. DISPLAY "SQLCODE : " NUM-EDI. DISPLAY "SQLSTATE: " SQLSTATE.
Comments: - All EXEC SQL statements must begin in Area B. - INCLUDE statement simply includes code from a specific member. It works similarly to COPY statement which will be discussed in one of the later Assignments. - SQLCA should be always included in your program. It stores a set of SQL related variables such as SQLCODE or SQLSTATE which you can use to test if your queries ended fine or if they were empty or not. - The database in this example stores data in ASCII format. To display it, the data needs to be converted to EBCDIC. Such conversion is done with NATIONAL-OF and DISPLAY-OF functions. - ':' character is used to indicate COBOL variables in SQL code. Important: - Before including any SQL in your program always test it manually in SPUFI or similar tool, this way you'll save a lot of time in testing. - When you issue any SQL statement, even SELECT, you lock the dats in mode specified either in SQL code or in ISOLATION keyword of BIND command. This lock will persist until the point specified in RELEASE keyword of BIND command. COMMIT option means that the lock will persist until COMMIT command or program end. Be sure to always specify COMMIT as soon as possible in your code. Otherwise, you'll held the data for unnecessary time which increase probability of deadlocks and timeouts. JCL code:
//JSADEKDB JOB NOTIFY=&SYSUID,COND=(4,LT), <== VERIFY JOB CARD // LINES=(10,CANCEL),REGION=6M //********************************************************************* //* DCLGEN //********************************************************************* //DCLGEN EXEC PGM=IKJEFT01 //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * <== VERIFY PARAMETERS DSN SYSTEM (DB9G) DCLGEN TABLE (JSADEK.DOGS) - LIBRARY ('JSADEK.COBDB2.DCLGEN(DOGS)') - STRUCTURE (DOGS-REC) - ACTION (REP) - LANGUAGE (COBOL) - LABEL (YES) - QUOTE DCLGEN TABLE (JSADEK.OWNERS) - LIBRARY ('JSADEK.COBDB2.DCLGEN(OWNERS)') - STRUCTURE (OWNERS-REC) - ACTION (REP) - LANGUAGE (COBOL) - LABEL (YES) - QUOTE //********************************************************************* //* PRE-COMPILATION //********************************************************************* //PRECOMP EXEC PGM=DSNHPC,PARM='HOST(IBMCOB),APOST,SOURCE' //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //DBRMLIB DD DISP=SHR,DSN=JSADEK.COBDB2.DBRM(TEST1) <== DBRM MEM //SYSIN DD DISP=SHR,DSN=JSADEK.COBDB2.SOURCE(TEST1) <== SOURCE MEM //SYSCIN DD DISP=SHR,DSN=JSADEK.COBDB2.MODSRC(TEST1) <== MODSRC MEM //SYSLIB DD DISP=SHR,DSN=JSADEK.COBDB2.DCLGEN <== DCLGEN LIB //SYSPRINT DD SYSOUT=* //SYSTERM DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSUT1 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT2 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //********************************************************************* //* COMPILATION //********************************************************************* //COMPILE EXEC PGM=IGYCRCTL, // PARM=('LIST,LIB,MAP,OBJECT,DATA(31),XREF,RENT') //STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP <== COMPILER LIB //SYSIN DD DISP=SHR,DSN=JSADEK.COBDB2.MODSRC(TEST1) <== MODSRC MEM //SYSLIB DD DISP=SHR,DSN=JSADEK.COBDB2.DCLGEN <== DCLGEN LIB //SYSLIN DD DSN=&&OBJCODE,DISP=(MOD,PASS),SPACE=(CYL,(1,1)) //SYSPRINT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSUT1 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT2 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT3 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT4 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT5 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT6 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT7 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //********************************************************************* //* LINK EDIT //********************************************************************* //LINKEDIT EXEC PGM=IEWL,PARM='XREF' //SYSLIB DD DISP=SHR,DSN=CEE.SCEELKED <== SCEELKED LIB // DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSLMOD DD DISP=SHR,DSN=JSADEK.COBDB2.LOADLIB(TEST1) <== LOAD MOD //SYSLIN DD DSN=&&OBJCODE,DISP=(OLD,DELETE) //SYSPRINT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //********************************************************************* //* BIND PACKAGE //********************************************************************* //BINDPACK EXEC PGM=IKJEFT01 //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * <== VERIFY PARAMETERS DSN SYSTEM (DB9G) BIND MEMBER (TEST1) - PACKAGE (TEST1) - LIBRARY ('JSADEK.COBDB2.DBRM') - ACTION (REP) - ISOLATION (CS) - VALIDATE (BIND) - RELEASE (COMMIT) - OWNER (JSADEK) - QUALIFIER (JSADEK) //********************************************************************* //* BIND PLAN //********************************************************************* //BINDPLAN EXEC PGM=IKJEFT01 //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * <== VERIFY PARAMETERS DSN SYSTEM (DB9G) BIND PLAN (TEST1) - PKLIST (TEST1.*) - ACTION (REP) - ISOLATION (CS) - VALIDATE (BIND) - RELEASE (COMMIT) - OWNER (JSADEK) - QUALIFIER (JSADEK) //********************************************************************* //* RUN THE PROGRAM //********************************************************************* //RUNPROG EXEC PGM=IKJEFT01 //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * DSN SYSTEM (DB9G) RUN PROGRAM (TEST1) - PLAN (TEST1) - LIBRARY ('JSADEK.COBDB2.LOADLIB')
Comments: - Until you have experience with coding DB2 programs, it's a good idea to save both DBRM and Modified Source to libraries in contrast to using temporary files. This way you'll be able to see what's done by Pre-compiler. Especially Modified source is worth reviewing so you'll know what SQL related variables are available in SQLCA. - In DCLGEN member, you can see that COBOL variables for DB2 columns of VARCHAR data type consist of two fields, LEN and TEXT. LEN part works like RDW in variable records, it describes the length of the TEXT variable.
Solution 3
As you know Collections and Plans are just entries in DB2 Catalog tables. All you need to do to create them is to run BIND PLAN step:
//********************************************************************* //* BIND PLAN //********************************************************************* //BINDPLAN EXEC PGM=IKJEFT01 //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * <== VERIFY PARAMETERS DSN SYSTEM (DB9G) BIND PLAN (MPPLAN) - PKLIST (MPCOLL.*) - ACTION (REP) - ISOLATION (CS) - VALIDATE (BIND) - RELEASE (COMMIT) - OWNER (JSADEK) - QUALIFIER (JSADEK)
From now on you can skip this step in all Tasks in this Assignment and specify Collection name in BIND PACKAGE step:
//********************************************************************* //* BIND PACKAGE //********************************************************************* //BINDPACK EXEC PGM=IKJEFT01 //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * <== VERIFY PARAMETERS DSN SYSTEM (DB9G) BIND MEMBER (MP1303) - PACKAGE (MPCOLL) - LIBRARY ('JSADEK.COBDB2.DBRM') - ACTION (REP) - ISOLATION (CS) - VALIDATE (BIND) - RELEASE (COMMIT) - OWNER (JSADEK) - QUALIFIER (JSADEK)
Collection is a link between the Package and the Plan. In here Package MP1303 became part of MPCOLL Collection and in result part of MPPLAN Plan:
SELECT NAME, COLLID FROM SYSIBM.SYSPACKAGE WHERE COLLID = 'MPCOLL' ; ----------------- NAME COLLID ----------------- MP1303 MPCOLL MP1304 MPCOLL SELECT COLLID, PLANNAME FROM SYSIBM.SYSPACKLIST WHERE COLLID = 'MPCOLL' ; ------------------- COLLID PLANNAME ------------------- MPCOLL MPPLAN SELECT NAME FROM SYSIBM.SYSPLAN WHERE NAME = 'MPPLAN' ; -------- NAME -------- MPPLAN
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1303. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE DOGS END-EXEC. EXEC SQL INCLUDE OWNERS END-EXEC. 77 DOG-ASCII PIC X(10). 77 DOG-NAT PIC N(10). 77 DOG-EBCDIC PIC X(10). 77 NUM-EDI PIC -(9)9. 77 TEMP-NUM PIC S9(9) COMP. 77 TEMP-NAT PIC N(10). 77 TEMP-EBCDIC PIC X(10). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM ASK-FOR-DOG. PERFORM GET-DOG-INFO UNTIL DOG-EBCDIC = "EXIT". PERFORM SQL-COMMIT. STOP RUN. GET-DOG-INFO. PERFORM DOG-NAME-EBCDIC-TO-ASCII. MOVE LOW-VALUES TO DOGS-REC. EXEC SQL SELECT * INTO :DOGS-REC FROM DOGS WHERE NAME = :DOG-ASCII END-EXEC. PERFORM CHECK-SQL-INFO. IF SQLCODE = 100 DISPLAY "NO DOG NAMED " DOG-EBCDIC " FOUND" ELSE PERFORM DISPLAY-DOG MOVE OWNER-ID OF DOGS-REC TO TEMP-NUM MOVE LOW-VALUES TO OWNERS-REC EXEC SQL SELECT * INTO :OWNERS-REC FROM OWNERS WHERE OWNER_ID = :TEMP-NUM END-EXEC PERFORM CHECK-SQL-INFO IF SQLCODE = 100 DISPLAY "THIS POOR DOG DOESN'T HAVE AN OWNER" ELSE PERFORM DISPLAY-OWNER END-IF END-IF PERFORM ASK-FOR-DOG. ASK-FOR-DOG. MOVE LOW-VALUES TO DOG-EBCDIC. DISPLAY " ". DISPLAY "SPECIFY DOG NAME OR 'EXIT':" ACCEPT DOG-EBCDIC. DOG-NAME-EBCDIC-TO-ASCII. MOVE FUNCTION NATIONAL-OF(DOG-EBCDIC, 1140) TO DOG-NAT. MOVE FUNCTION DISPLAY-OF(DOG-NAT, 819) TO DOG-ASCII. DISPLAY-DOG. MOVE FUNCTION NATIONAL-OF(NAME-TEXT OF DOGS-REC, 819) TO TEMP-NAT. MOVE FUNCTION DISPLAY-OF(TEMP-NAT, 1140) TO TEMP-EBCDIC. DISPLAY "DOG NAME: " TEMP-EBCDIC. MOVE FUNCTION NATIONAL-OF(RACE-TEXT, 819) TO TEMP-NAT. MOVE FUNCTION DISPLAY-OF(TEMP-NAT, 1140) TO TEMP-EBCDIC. DISPLAY "DOG RACE: " TEMP-EBCDIC. MOVE OWNER-ID OF DOGS-REC TO NUM-EDI. DISPLAY "OWNER ID: " NUM-EDI. DISPLAY-OWNER. MOVE FUNCTION NATIONAL-OF(NAME-TEXT OF OWNERS-REC, 819) TO TEMP-NAT. MOVE FUNCTION DISPLAY-OF(TEMP-NAT, 1140) TO TEMP-EBCDIC. DISPLAY "OWNER : " TEMP-EBCDIC. CHECK-SQL-INFO. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE STOP RUN END-IF. SQL-COMMIT. EXEC SQL COMMIT END-EXEC.
Comments: - SQL doesn't clear host variables before moving data there. You need to do it manually before each EXEC SQL statement. - The first problem to solve is duplicated variable name. Both DOGS and OWNERS tables have same columns: NAME and OWNER-ID. This is a common situation. Of course, one solution to that would be to modify DCLGEN members, but you shouldn't do that. DCLGEN definitions are usually used by many programs so changing them would create a lot of problems when recompiling other programs. - COBOL allows a programmer to identify the structure to which variable belongs. This way we can reference duplicated fields. 'OF' keyword is used for that. - Not all dogs have owners. For example, FLUFFY is connected to a non-existing owner. When working with SQL you should always consider such conditions. - This is a better designed program than the one from previous assignment. After each SQL query, SQLCODE is checked for errors and for 'no records found' condition (SQLCODE = 100). - A lot of code went into conversion between ASCII and EBCDIC. Fortunately in standard COBOL programs data is rarely displayed but you may still need to perform such conversion while writing some kind of logs or reports to data sets that should be stored in EBCDIC format. Also, programs compiled with the use od co-processor can perform data conversion in flight. In other words, with the co-processor, your program can work on EBCDIC data even if DB2 tables use ASCII or UTF-8 character sets.
Solution 4
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1304. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE TDOGS END-EXEC. 77 NUM-EDI PIC -(9)9. 77 K1 PIC 9(4) COMP. 77 ROW-NUM PIC 9(4) COMP. 77 TBL-SIZE PIC 9(4) COMP VALUE 100. 77 TEMP-NAT PIC N(10). 77 T-RACE PIC X(10). 77 T-NAME PIC X(10). 77 T-OWNER PIC S9(10) COMP. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM INIT. PERFORM FETCH-DATA-FROM-DB2. PERFORM SQL-COMMIT. PERFORM DISPLAY-THE-DATA. PERFORM CLEANUP. STOP RUN. INIT. EXEC SQL DECLARE CSR-DOGS CURSOR FOR SELECT * FROM DOGS END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN CSR-DOGS END-EXEC. PERFORM CHECK-EXECSQL. FETCH-DATA-FROM-DB2. DISPLAY "FETCHING DATA...". PERFORM FETCH-ROW VARYING K1 FROM 1 BY 1 UNTIL SQLCODE NOT = 0. COMPUTE ROW-NUM = K1 - 2. IF ROW-NUM = 0 DISPLAY "ERROR: NO ROWS MATCH SELECTION CRITERIA." PERFORM CLEANUP STOP RUN END-IF. MOVE ROW-NUM TO NUM-EDI. DISPLAY "DATA LOADED..." NUM-EDI " ROWS COPIED.". FETCH-ROW. EXEC SQL FETCH NEXT FROM CSR-DOGS INTO :T-RACE, :T-NAME, :T-OWNER END-EXEC. PERFORM CHECK-EXECSQL. IF SQLCODE = 0 IF K1 > TBL-SIZE DISPLAY "ERROR: SQL QUERY RETURNED MORE ROWS THAT COULD F - "IT INTO TABLE." PERFORM CLEANUP STOP RUN END-IF PERFORM CONVERT-AND-COPY-ROW END-IF. CONVERT-AND-COPY-ROW. MOVE FUNCTION NATIONAL-OF(T-RACE, 819) TO TEMP-NAT. MOVE FUNCTION DISPLAY-OF(TEMP-NAT, 1140) TO RACE-TEXT(K1). MOVE FUNCTION NATIONAL-OF(T-NAME, 819) TO TEMP-NAT. MOVE FUNCTION DISPLAY-OF(TEMP-NAT, 1140) TO NAME-TEXT(K1). MOVE T-OWNER TO OWNER-ID(K1). DISPLAY-THE-DATA. DISPLAY " ". DISPLAY "EXTRACTED DATA:". PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > ROW-NUM DISPLAY "DOG NAME: " NAME-TEXT(K1) DISPLAY "DOG RACE: " RACE-TEXT(K1) MOVE OWNER-ID(K1) TO NUM-EDI DISPLAY "OWNER ID: " NUM-EDI END-PERFORM. CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE PERFORM CLEANUP STOP RUN END-IF. CLEANUP. EXEC SQL CLOSE CSR-DOGS END-EXEC. SQL-COMMIT. EXEC SQL COMMIT END-EXEC.
Output in three tested conditions:
**************************************** received records < table size **************************************** FETCHING DATA... DATA LOADED... 4 ROWS COPIED. EXTRACTED DATA: DOG NAME: LILLY DOG RACE: HUSKY OWNER ID: 1 DOG NAME: JACK DOG RACE: GREYHOUND OWNER ID: 1 DOG NAME: DUMMY DOG RACE: YORK OWNER ID: 2 DOG NAME: FLUFFY DOG RACE: BEAGLE OWNER ID: 4 **************************************** received records = table size **************************************** FETCHING DATA... DATA LOADED... 4 ROWS COPIED. EXTRACTED DATA: DOG NAME: LILLY DOG RACE: HUSKY OWNER ID: 1 DOG NAME: JACK DOG RACE: GREYHOUND OWNER ID: 1 DOG NAME: DUMMY DOG RACE: YORK OWNER ID: 2 DOG NAME: FLUFFY DOG RACE: BEAGLE OWNER ID: 4 **************************************** received records > table size **************************************** FETCHING DATA... ERROR: SQL QUERY RETURNED MORE ROWS THAT COULD FIT INTO TABLE. **************************************** received records = 0 **************************************** FETCHING DATA... ERROR: NO ROWS MATCH SELECTION CRITERIA.
Comments: - TDOGS is a modified version of DOGS DCLGEN. The only difference there is OCCURS clause. Now we are able to use this structure to store multiple rows from DOGS table. - Notice the usage of DB2 cursors. A cursor enables you to read rows in DB2 table similarly to reading records in a sequential file, one by one, but it also provides much more flexibility than you have with sequential files. - SQLCODE = 100 indicates 'no records found' condition. When used with cursor it indicates that the last record from the query result was already read. In other words, it's can be used for dynamic detection of the end of the query. - DECLARE & OPEN CURSOR statement must appear before FETCH instruction not only in terms of program execution flow but also order is source code. Moving INIT paragraph after FETCH-ROW will produce a false pre-compiler error. Important: - For performance reasons, you should use single-row fetch only when you're sure that a single row will be returned. In the next Assignment, you'll learn multi-row fetch which is the recommended way of fetching multiple rows from DB2 tables. Multi-row fetch is generally 50-60% faster than single-row fetch, is some cases it's even faster than that.
Solution 5
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1305. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. 01 DOG-TABLE. 05 DOG-REC OCCURS 2000 TIMES DEPENDING ON TAB-SIZE. 10 DOGNAME-L PIC S9(4) COMP. 10 DOGNAME PIC X(10). 05 OWNER-ID OCCURS 2000 TIMES DEPENDING ON TAB-SIZE PIC S9(9) COMP. 77 T-DOGNAME PIC X(10). 77 T-DOGNAME-L PIC S9(4) COMP. 77 T-OWNER-ID PIC S9(4) COMP. 77 NUM-EDI PIC -(4)9. 77 K1 PIC 9(4) COMP. 77 TAB-SIZE PIC S9(18) COMP. 77 TEMP-NAT PIC N(10). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM GET-COUNT. PERFORM HOLD-PROGRAM. PERFORM INIT-CSR. PERFORM FETCH-DATA-FROM-DB2. PERFORM SQL-COMMIT. PERFORM DISPLAY-THE-DATA. PERFORM CLEANUP. STOP RUN. HOLD-PROGRAM. ACCEPT T-DOGNAME FROM CONSOLE. GET-COUNT. EXEC SQL SELECT COUNT(*) INTO :TAB-SIZE FROM DOGS WITH RR END-EXEC. PERFORM CHECK-EXECSQL. IF TAB-SIZE = 0 DISPLAY "ERROR: NO ROWS MATCH SELECTION CRITERIA." PERFORM CLEANUP STOP RUN END-IF. IF TAB-SIZE > 2000 DISPLAY "ERROR: SQL QUERY RETURNED MORE ROWS THAT COULD FIT - " INTO TABLE." PERFORM CLEANUP STOP RUN END-IF. INIT-CSR. EXEC SQL DECLARE CSR CURSOR FOR SELECT NAME, OWNER_ID, LENGTH(NAME) FROM DOGS END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN CSR END-EXEC. PERFORM CHECK-EXECSQL. FETCH-DATA-FROM-DB2. DISPLAY "FETCHING DATA...". PERFORM FETCH-ROW VARYING K1 FROM 1 BY 1 UNTIL K1 > TAB-SIZE. MOVE TAB-SIZE TO NUM-EDI. DISPLAY "DATA LOADED..." NUM-EDI " ROWS COPIED.". FETCH-ROW. EXEC SQL FETCH NEXT FROM CSR INTO :T-DOGNAME, :T-OWNER-ID, :T-DOGNAME-L END-EXEC. PERFORM CHECK-EXECSQL. PERFORM CONVERT-AND-COPY-ROW. CONVERT-AND-COPY-ROW. MOVE FUNCTION NATIONAL-OF(T-DOGNAME, 819) TO TEMP-NAT. MOVE FUNCTION DISPLAY-OF(TEMP-NAT, 1140) TO DOGNAME(K1). MOVE T-OWNER-ID TO OWNER-ID(K1). MOVE T-DOGNAME-L TO DOGNAME-L(K1). DISPLAY-THE-DATA. DISPLAY " ". DISPLAY "EXTRACTED DATA:". PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > TAB-SIZE MOVE OWNER-ID(K1) TO NUM-EDI DISPLAY "DOG NAME: " DOGNAME(K1) (1 : DOGNAME-L(K1)) ", OWNER-ID: " NUM-EDI END-PERFORM. CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE PERFORM CLEANUP STOP RUN END-IF. CLEANUP. EXEC SQL CLOSE CSR END-EXEC. SQL-COMMIT. EXEC SQL COMMIT END-EXEC.
Comments: - As you can see you don't need to have DCLGEN definitions to work with DB2 tables. When you know that you're program uses only one column it may be a good idea to stay with a standard array. - When defining a structure for DB2 data without DCLGEN you need to figure out appropriate PIC clause yourself. The first thing to do is to check definitions of used columns. DB2ADM can be used here: DB2ADM ; 1 (DB2 System Catalog) ; Put your ID in "Owner" field ; T (Tables) ; C on DOGS record. - In there you'll see:
Column Name Col No Col Type Length Scale Null Def FP Col Card ------------------ ------ -------- ------ ------ ---- --- -- ----------- RACE 1 VARCHAR 10 0 Y Y N -1 NAME 2 VARCHAR 10 0 Y Y N -1 OWNER_ID 3 INTEGER 4 0 Y Y N -1
The appropriate definition looks as follow:
01 DOG-TABLE. 05 DOG-REC OCCURS 2000 TIMES DEPENDING ON TAB-SIZE. 10 DOGNAME-L PIC S9(4) COMP. 10 DOGNAME PIC X(10). 05 OWNER-ID OCCURS 2000 TIMES DEPENDING ON TAB-SIZE PIC S9(9) COMP.
- VARCHAR type should be mapped into two parts. The first part, DOGNAME-L defines the length of the text in DOGNAME part. - OWNER ID is an INTEGER which is mapped to "PIC S9(9) COMP" variable. - Of course, the easiest way is to generate full DCLGEN definition and then copy the fields you need, but it's also good to know how to do that manually. - Also, you need to know variable SQL to COBOL datatype mapping to define appropriate COBOL variables used in SQL functions. For example, COUNT(*) function returns BIGINT so it requires "S9(18) COMP" variable. - Notice the usage of DOGNAME-L variable. First SQL LENGTH(*) function gets the length of NAME field. Next, it's used to sub-string DOGNAME variable: "DOGNAME(K1) (1 : DOGNAME-L(K1))" in order to trim trailing spaces from NAME field. Some queries will populate length variable automatically, but sometimes you'll need to do it with use of LENGTH function. Important: - Using COUNT(*) simplifies the program but introduces a new problem. When working on DB2 you should always consider a situation in which the table you're working on is updated during program execution. In this example, it is possible that between COUNT(*) and FETCH statements some records will be added or removed. In result, the program may work on incorrect or incomplete results. This issue can be solved by "WITH RR" addition. With RR turns on Repeatable-Read mode, so it ensures that the data used in the transaction wont be modified in any way. See "Concurrency & Locking" Assignment in "DB2 & SQL" tab.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1306. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. 01 TABLES-TABLE. 05 TABNAME OCCURS 50 TIMES PIC X(128). 05 TABNAME-L OCCURS 50 TIMES PIC S9(4) COMP. 05 COLCOUNT OCCURS 50 TIMES PIC S9(4) COMP. 77 NUM-EDI PIC -(4)9. 77 K1 PIC 9(4) COMP. 77 TAB-SIZE PIC 9(4) COMP VALUE 0. 77 ROWS-IN-SET PIC 9(4) COMP. 77 ROWSET-NUM PIC 9(4) VALUE 0. 77 TEMP-NAT PIC N(128). 77 TEMP-EBCDIC PIC X(128). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM INIT-CSR. PERFORM FETCH-DATA-FROM-DB2. PERFORM SQL-COMMIT. PERFORM CLEANUP. STOP RUN. INIT-CSR. EXEC SQL DECLARE CSR CURSOR WITH ROWSET POSITIONING FOR SELECT NAME, COLCOUNT, LENGTH(NAME) FROM SYSIBM.SYSTABLES END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN CSR END-EXEC. PERFORM CHECK-EXECSQL. FETCH-DATA-FROM-DB2. DISPLAY "FETCHING DATA...". PERFORM FETCH-ROWSET UNTIL SQLCODE = 100. MOVE TAB-SIZE TO NUM-EDI. DISPLAY "DATA LOADED..." NUM-EDI " ROWS COPIED.". FETCH-ROWSET. EXEC SQL FETCH NEXT ROWSET FROM CSR FOR 50 ROWS INTO :TABNAME, :COLCOUNT, :TABNAME-L END-EXEC. PERFORM CHECK-EXECSQL. ADD 1 TO ROWSET-NUM. MOVE SQLERRD(3) TO ROWS-IN-SET. COMPUTE TAB-SIZE = TAB-SIZE + ROWS-IN-SET. PERFORM DISPLAY-THE-ROWSET. DISPLAY-THE-ROWSET. DISPLAY " ". DISPLAY "ROWSET " ROWSET-NUM " (" ROWS-IN-SET " ROWS):" PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > ROWS-IN-SET MOVE FUNCTION NATIONAL-OF(TABNAME(K1), 819) TO TEMP-NAT MOVE FUNCTION DISPLAY-OF(TEMP-NAT, 1140) TO TEMP-EBCDIC MOVE COLCOUNT(K1) TO NUM-EDI DISPLAY "TABLE NAME: " TEMP-EBCDIC(1 : TABNAME-L(K1)) ", COLUMNS IN THE TABLE: " NUM-EDI END-PERFORM. CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE PERFORM CLEANUP STOP RUN END-IF. CLEANUP. EXEC SQL CLOSE CSR END-EXEC. SQL-COMMIT. EXEC SQL COMMIT END-EXEC.
Comments: - You cannot use arrays of structure for multi-row fetch, for example:
01 TABLES-TABLE. 05 TABNAME-REC OCCURS 50 TIMES 10 TABNAME-L PIC S9(4) COMP. 10 TABNAME PIC X(128).
- OCCURS clause must appear directly in the item that's used in FETCH instruction so TABNAME & TABNAME-L. Important: - Multi-row FETCH should be always used. It has much better performance that single-row FETCH, it doesn't require as much RAM storage since you usually use arrays with 20, 50, maybe 100 elements and you don't have to worry about the actual query size. Also, code for multi-row fetch is actually simpler.
Solution 7
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1307. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT OUT-FILE ASSIGN TO OUTFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS OUT-STAT. DATA DIVISION. FILE SECTION. FD OUT-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 446 CHARACTERS DEPENDING ON REC-SIZE. 01 OUT-REC PIC X(446). WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE PACKLIST END-EXEC. 77 OUT-STAT PIC XX. 77 K1 PIC 9(4) COMP. 77 T1 PIC 9(4) COMP. 77 T2 PIC 9(4) COMP. 77 TAB-SIZE PIC 9(4) COMP VALUE 0. 77 ROWS-IN-SET PIC 9(4) COMP. 77 ROWSET-NUM PIC 9(4) VALUE 0. 77 STR-NAT PIC N(128). 77 STR-EBCDIC PIC X(128). 77 NUM-EDI PIC -(4)9. 77 REC-SIZE PIC 9(4) COMP. 77 ASCII-COMMA PIC X. 77 OUT-REC-NAT PIC N(80). 01 OUT-TEMP. 05 OUT-PLANNAME PIC X(24). 05 OUT-SEQNO PIC X(5). 05 OUT-LOCATION PIC X(128). 05 OUT-COLLID PIC X(128). 05 OUT-NAME PIC X(128). 05 OUT-TIMESTAMP PIC X(26). 05 OUT-IBMREQD PIC X. 01 CRLF-STRUCT. 05 CRLF-VALUE PIC 9(4) COMP VALUE 3338. LINKAGE SECTION. 01 PARM. 05 PARM-L PIC 9(4) COMP. 05 PARM-D PIC X(8). PROCEDURE DIVISION USING PARM. MAIN-LOGIC. PERFORM VERIFY-PARM. PERFORM INIT-CSR. PERFORM OPEN-FILE. PERFORM WRITE-HEADER. PERFORM COPY-PACKLIST-TABLE. PERFORM SQL-COMMIT. PERFORM CLEANUP. STOP RUN. VERIFY-PARM. IF (PARM-D(1 : PARM-L) NOT = "ASCII" AND PARM-D(1 : PARM-L) NOT = "EBCDIC") OR PARM-L > 6 DISPLAY "GIVEN PARAMETER (" PARM-D ") IS INVALID." MOVE PARM-L TO NUM-EDI MOVE 16 TO RETURN-CODE DISPLAY NUM-EDI STOP RUN END-IF. MOVE FUNCTION NATIONAL-OF(",", 1140) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 819) TO ASCII-COMMA. INIT-CSR. EXEC SQL DECLARE CSR CURSOR WITH ROWSET POSITIONING FOR SELECT LENGTH(PLANNAME), PLANNAME, SEQNO, LENGTH(LOCATION), LOCATION, LENGTH(COLLID), COLLID, LENGTH(NAME), NAME, TIMESTAMP, IBMREQD FROM SYSIBM.SYSPACKLIST END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN CSR END-EXEC. PERFORM CHECK-EXECSQL. WRITE-HEADER. MOVE "PLAN-NAME,SEQ-NO,LOCATION,COLLECTION-ID,PACKAGE-NAME,TI - "ME-STAMP,IBMREQD" TO OUT-REC. MOVE 71 TO REC-SIZE. IF PARM-D(1 : PARM-L) = "ASCII" MOVE FUNCTION NATIONAL-OF(OUT-REC, 1140) TO OUT-REC-NAT MOVE FUNCTION DISPLAY-OF(OUT-REC-NAT, 819) TO OUT-REC MOVE 73 TO REC-SIZE STRING OUT-REC(1 : 71) CRLF-STRUCT(1 : 2) DELIMITED BY SIZE INTO OUT-REC END-STRING END-IF. WRITE OUT-REC. PERFORM CHECK-OUT-FILE. OPEN-FILE. OPEN OUTPUT OUT-FILE. PERFORM CHECK-OUT-FILE. COPY-PACKLIST-TABLE. DISPLAY "FETCHING DATA...". PERFORM FETCH-ROWSET UNTIL SQLCODE NOT = 0. MOVE TAB-SIZE TO NUM-EDI. DISPLAY "DATA LOADED..." NUM-EDI " ROWS COPIED.". FETCH-ROWSET. EXEC SQL FETCH NEXT ROWSET FROM CSR FOR 20 ROWS INTO :PLANNAME-LEN, :PLANNAME-TEXT, :SEQNO, :LOCATION-LEN, :LOCATION-TEXT, :COLLID-LEN, :COLLID-TEXT, :NAME-LEN, :NAME-TEXT, :TIMESTAMP, :IBMREQD END-EXEC. PERFORM CHECK-EXECSQL. ADD 1 TO ROWSET-NUM. MOVE SQLERRD(3) TO ROWS-IN-SET. COMPUTE TAB-SIZE = TAB-SIZE + ROWS-IN-SET. PERFORM COPY-ROWSET-TO-EBCDIC-FILE. COPY-ROWSET-TO-EBCDIC-FILE. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > ROWS-IN-SET MOVE SPACES TO OUT-REC IF PARM-D(1 : PARM-L) = "EBCDIC" PERFORM CONVERT-TO-EBCDIC ELSE PERFORM CONVERT-TO-ASCII END-IF END-PERFORM. DISPLAY "ROWSET " ROWSET-NUM " (" ROWS-IN-SET " ROWS) COPIED". CONVERT-TO-ASCII. MOVE SEQNO(K1) TO NUM-EDI. MOVE 0 TO T1 T2. INSPECT NUM-EDI TALLYING T1 FOR LEADING SPACES. COMPUTE T2 = LENGTH OF NUM-EDI - T1. ADD 1 TO T1. MOVE FUNCTION NATIONAL-OF(NUM-EDI, 1140) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 819) TO OUT-SEQNO. STRING PLANNAME-TEXT(K1)(1 : PLANNAME-LEN(K1)) ASCII-COMMA OUT-SEQNO (T1 : T2) ASCII-COMMA LOCATION-TEXT(K1)(1 : LOCATION-LEN(K1)) ASCII-COMMA COLLID-TEXT(K1)(1 : COLLID-LEN(K1)) ASCII-COMMA NAME-TEXT(K1)(1 : NAME-LEN(K1)) ASCII-COMMA TIMESTAMP(K1) ASCII-COMMA IBMREQD(K1) CRLF-STRUCT(1 : 2) DELIMITED BY SIZE INTO OUT-REC. MOVE 0 TO REC-SIZE. INSPECT FUNCTION REVERSE(OUT-REC) TALLYING REC-SIZE FOR LEADING SPACES. COMPUTE REC-SIZE = LENGTH OF OUT-REC - REC-SIZE. WRITE OUT-REC. PERFORM CHECK-OUT-FILE. CONVERT-TO-EBCDIC. MOVE FUNCTION NATIONAL-OF(PLANNAME-TEXT(K1), 819) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 1140) TO OUT-PLANNAME. MOVE SEQNO(K1) TO NUM-EDI. MOVE NUM-EDI TO OUT-SEQNO. MOVE 0 TO T1 T2. INSPECT OUT-SEQNO TALLYING T1 FOR LEADING SPACES. COMPUTE T2 = LENGTH OF OUT-SEQNO - T1. ADD 1 TO T1. MOVE FUNCTION NATIONAL-OF(LOCATION-TEXT(K1), 819) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 1140) TO OUT-LOCATION. MOVE FUNCTION NATIONAL-OF(COLLID-TEXT(K1), 819) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 1140) TO OUT-COLLID. MOVE FUNCTION NATIONAL-OF(NAME-TEXT(K1), 819) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 1140) TO OUT-NAME. MOVE FUNCTION NATIONAL-OF(TIMESTAMP(K1), 819) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 1140) TO OUT-TIMESTAMP. MOVE FUNCTION NATIONAL-OF(IBMREQD(K1), 819) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 1140) TO OUT-IBMREQD. STRING OUT-PLANNAME DELIMITED BY SPACE "," OUT-SEQNO (T1 : T2) DELIMITED BY SIZE "," OUT-LOCATION DELIMITED BY SPACE "," OUT-COLLID DELIMITED BY SPACE "," OUT-NAME DELIMITED BY SPACE "," OUT-TIMESTAMP DELIMITED BY SIZE "," OUT-IBMREQD DELIMITED BY SIZE INTO OUT-REC. MOVE 0 TO REC-SIZE. INSPECT FUNCTION REVERSE(OUT-REC) TALLYING REC-SIZE FOR LEADING SPACES. COMPUTE REC-SIZE = LENGTH OF OUT-REC - REC-SIZE. WRITE OUT-REC. PERFORM CHECK-OUT-FILE. CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE MOVE 12 TO RETURN-CODE PERFORM CLEANUP STOP RUN END-IF. CHECK-OUT-FILE. IF OUT-STAT NOT = "00" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY: " OUT-STAT MOVE OUT-STAT TO RETURN-CODE PERFORM CLEANUP STOP RUN END-IF. CLEANUP. EXEC SQL CLOSE CSR END-EXEC. CLOSE OUT-FILE. SQL-COMMIT. EXEC SQL COMMIT END-EXEC.
JCL for running the job:
//********************************************************************* //* DELETE THE OUTPUT IF EXISTS //********************************************************************* //DELSTEP EXEC PGM=IEFBR14 //DELDD DD DSN=JSADEK.DB2.PACKLIST.EBCDIC, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //********************************************************************* //* RUN THE PROGRAM //********************************************************************* //RUNPROG EXEC PGM=IKJEFT01 //STEPLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * DSN SYSTEM (DB9G) RUN PROGRAM (MP1307) - PLAN (MPPLAN) - LIBRARY ('JSADEK.COBDB2.LOADLIB') - PARMS ('EBCDIC') //OUTFILE DD DSN=*.DELSTEP.DELDD,DISP=(NEW,CATLG,DELETE), // SPACE=(TRK,(15,15),RLSE),BLKSIZE=27998,LRECL=450,RECFM=VB
Comments: - The file has LRECL = 450 and is in VB record format so 450 is the maximum record length. Still, record description in the program is 446, this is the maximum length of the data (440 bytes can use up columns and additional 6 bytes is reserved for separation characters ','). - Parameters given to DB2 programs are passed via RUN DB2 command, not, for example, via PARM JCL keyword. - Also, notice how the parameter is referred to "PARM-D(1 : PARM-L)". When a parameter is passed via DB2 RUN command, trailing blanks are filled with LOW-VALUES instead of SPACES. This leads to an incorrect comparison result between PARM-D and "EBCDIC" constant. Because of that, sub-string of PARM-D is used for comparison. - As proven in this exercise, INSPECT function with SPACES keyword also correctly detects spaces codes in ASCII charset. - Notice the use of CRLF-STRUCT. In case of ASCII file, we need to add a new-line indicator at the end of each record. To do that you can quickly find hexadecimal representation of CR+LF characters "0D0A" convert it to decimal number "3338" and then put into COMP variable that thanks to CRLF-STRUCT can be also interpreted as a string.
Solution 8
JCL code:
//JSADEKDB JOB NOTIFY=&SYSUID,COND=(4,LT), <== VERIFY JOB CARD // LINES=(10,CANCEL),REGION=6M //JOBLIB DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB // DD DISP=SHR,DSN=IGY410.SIGYCOMP <== COMPILER LIB //********************************************************************* //* COMPILATION //********************************************************************* //COMPILE EXEC PGM=IGYCRCTL, // PARM=('LIST,LIB,MAP,OBJECT,DATA(31),XREF,RENT,SQL') //DBRMLIB DD DISP=SHR,DSN=JSADEK.COBDB2.DBRM(MP1308) <== DBRM MEM //SYSIN DD DISP=SHR,DSN=JSADEK.COBDB2.SOURCE(MP1308) <== SOURCE MEM //SYSLIB DD DISP=SHR,DSN=JSADEK.COBDB2.DCLGEN <== DCLGEN LIB //SYSLIN DD DSN=&&OBJCODE,DISP=(MOD,PASS),SPACE=(CYL,(1,1)) //SYSPRINT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSUT1 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT2 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT3 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT4 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT5 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT6 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //SYSUT7 DD UNIT=SYSDA,SPACE=(TRK,(1,15)) //********************************************************************* //* LINK EDIT //********************************************************************* //LINKEDIT EXEC PGM=IEWL,PARM='XREF' //SYSLIB DD DISP=SHR,DSN=CEE.SCEELKED <== SCEELKED LIB // DD DISP=SHR,DSN=DSN910.SDSNLOAD <== DB2 SDSNLOAD LIB //SYSLMOD DD DISP=SHR,DSN=JSADEK.COBDB2.LOADLIB(MP1308) <== LOAD MOD //SYSLIN DD DSN=&&OBJCODE,DISP=(OLD,DELETE) //SYSPRINT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //********************************************************************* //* BIND PACKAGE //********************************************************************* //BINDPACK EXEC PGM=IKJEFT01 //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * <== VERIFY PARAMETERS DSN SYSTEM (DB9G) BIND MEMBER (MP1308) - PACKAGE (MPCOLL) - LIBRARY ('JSADEK.COBDB2.DBRM') - ACTION (REP) - ISOLATION (CS) - VALIDATE (BIND) - RELEASE (COMMIT) - OWNER (JSADEK) - QUALIFIER (JSADEK) //********************************************************************* //* DELETE THE OUTPUT IF EXISTS //********************************************************************* //DELSTEP EXEC PGM=IEFBR14 //DELDD DD DSN=JSADEK.DB2.PACKLIST.ASCII2, // SPACE=(TRK,1),DISP=(MOD,DELETE,DELETE) //********************************************************************* //* RUN THE PROGRAM //********************************************************************* //RUNPROG EXEC PGM=IKJEFT01 //SYSPRINT DD SYSOUT=* //SYSTSPRT DD SYSOUT=* //SYSUDUMP DD SYSOUT=* //SYSTSIN DD * <== VERIFY PARAMETERS DSN SYSTEM (DB9G) RUN PROGRAM (MP1308) - PLAN (MPPLAN) - LIBRARY ('JSADEK.COBDB2.LOADLIB') - PARMS ('ASCII') //OUTFILE DD DSN=*.DELSTEP.DELDD,DISP=(NEW,CATLG,DELETE), // SPACE=(TRK,(15,15),RLSE),BLKSIZE=27998,LRECL=450,RECFM=VB
Comments: - No more pre-compilation step. Now, the source code is given directly to the compiler via SYSIN DD. - SQL and LIB compiler options must be specified. - DB2 SDSNLOAD library must be now included in STEPLIB in compilation step (or JOBLIB). EBCDIC file generated with SQLCCSID option:
PLAN-NAME,SEQ-NO,LOCATION,COLLECTION-ID,PACKAGE-NAME,TIME-STAMP,IBMREQD ÄâÕÙÅçç@@@@@@@@@@@@@@@@@,5,\@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ ÄâÕÙÅçç@@@@@@@@@@@@@@@@@,4,\@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ ...
ASCII file generated with SQLCCSID option:
&< +.+ (á.ëáé.+|.<|ä èñ|+.ä|<<áäèñ|+.ñà.& ä. åá.+ (á.èñ(á.ëè (&.ñâ(êáéà.. DSNREXX...*.DSNREXRR.DSNREXX.2008-05-30-16.33.27.974244.N.. DSNREXX...*.DSNREXRS.DSNREXX.2008-05-30-16.33.27.974244.N.. ...
It's not hard to notice that DB2 interfered with how the program processes the data: - In case of ASCII file, you can see that ASCII data was automatically converted to EBCDIC characters. The problem is that the program converts some of the data (header and numeric files from EBCDIC to ASCII. In result, we have mixed ASCII & EBCDIC data. - In case of EBCDIC file, the only readable data is header which wasn't manipulated in any way. But out program assumed that the data received from DB2 will be ASCII. In result, it interprets EBCDIC data as ASCII and converts EBCDIC to EBCDIC which, as you can see is not that good of an idea. Modified COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1308. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT OUT-FILE ASSIGN TO OUTFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS OUT-STAT. DATA DIVISION. FILE SECTION. FD OUT-FILE RECORDING MODE IS V RECORD IS VARYING IN SIZE FROM 1 TO 446 CHARACTERS DEPENDING ON REC-SIZE. 01 OUT-REC PIC X(446). WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE PACKLIST END-EXEC. 77 OUT-STAT PIC XX. 77 K1 PIC 9(4) COMP. 77 T1 PIC 9(4) COMP. 77 T2 PIC 9(4) COMP. 77 TAB-SIZE PIC 9(4) COMP VALUE 0. 77 ROWS-IN-SET PIC 9(4) COMP. 77 ROWSET-NUM PIC 9(4) VALUE 0. 77 STR-NAT PIC N(128). 77 STR-EBCDIC PIC X(128). 77 NUM-EDI PIC -(4)9. 77 REC-SIZE PIC 9(4) COMP. 77 ASCII-COMMA PIC X. 77 OUT-REC-NAT PIC N(446). 77 OUT-SEQNO PIC X(5). 01 CRLF-STRUCT. 05 CRLF-VALUE PIC 9(4) COMP VALUE 3338. LINKAGE SECTION. 01 PARM. 05 PARM-L PIC 9(4) COMP. 05 PARM-D PIC X(8). PROCEDURE DIVISION USING PARM. MAIN-LOGIC. PERFORM VERIFY-PARM. PERFORM INIT-CSR. PERFORM OPEN-FILE. PERFORM WRITE-HEADER. PERFORM COPY-PACKLIST-TABLE. PERFORM SQL-COMMIT. PERFORM CLEANUP. STOP RUN. VERIFY-PARM. IF (PARM-D(1 : PARM-L) NOT = "ASCII" AND PARM-D(1 : PARM-L) NOT = "EBCDIC") OR PARM-L > 6 DISPLAY "GIVEN PARAMETER (" PARM-D ") IS INVALID." MOVE PARM-L TO NUM-EDI MOVE 16 TO RETURN-CODE DISPLAY NUM-EDI STOP RUN END-IF. MOVE FUNCTION NATIONAL-OF(",", 1140) TO STR-NAT. MOVE FUNCTION DISPLAY-OF(STR-NAT, 819) TO ASCII-COMMA. INIT-CSR. EXEC SQL DECLARE CSR CURSOR WITH ROWSET POSITIONING FOR SELECT LENGTH(PLANNAME), PLANNAME, SEQNO, LENGTH(LOCATION), LOCATION, LENGTH(COLLID), COLLID, LENGTH(NAME), NAME, TIMESTAMP, IBMREQD FROM SYSIBM.SYSPACKLIST END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN CSR END-EXEC. PERFORM CHECK-EXECSQL. WRITE-HEADER. MOVE "PLAN-NAME,SEQ-NO,LOCATION,COLLECTION-ID,PACKAGE-NAME,TI - "ME-STAMP,IBMREQD" TO OUT-REC. MOVE 71 TO REC-SIZE. IF PARM-D(1 : PARM-L) = "ASCII" MOVE FUNCTION NATIONAL-OF(OUT-REC, 1140) TO OUT-REC-NAT MOVE FUNCTION DISPLAY-OF(OUT-REC-NAT, 819) TO OUT-REC MOVE 73 TO REC-SIZE STRING OUT-REC(1 : 71) CRLF-STRUCT(1 : 2) DELIMITED BY SIZE INTO OUT-REC END-STRING END-IF. WRITE OUT-REC. PERFORM CHECK-OUT-FILE. OPEN-FILE. OPEN OUTPUT OUT-FILE. PERFORM CHECK-OUT-FILE. COPY-PACKLIST-TABLE. DISPLAY "FETCHING DATA...". PERFORM FETCH-ROWSET UNTIL SQLCODE NOT = 0. MOVE TAB-SIZE TO NUM-EDI. DISPLAY "DATA LOADED..." NUM-EDI " ROWS COPIED.". FETCH-ROWSET. EXEC SQL FETCH NEXT ROWSET FROM CSR FOR 20 ROWS INTO :PLANNAME-LEN, :PLANNAME-TEXT, :SEQNO, :LOCATION-LEN, :LOCATION-TEXT, :COLLID-LEN, :COLLID-TEXT, :NAME-LEN, :NAME-TEXT, :TIMESTAMP, :IBMREQD END-EXEC. PERFORM CHECK-EXECSQL. ADD 1 TO ROWSET-NUM. MOVE SQLERRD(3) TO ROWS-IN-SET. COMPUTE TAB-SIZE = TAB-SIZE + ROWS-IN-SET. PERFORM COPY-ROWSET-TO-EBCDIC-FILE. COPY-ROWSET-TO-EBCDIC-FILE. PERFORM VARYING K1 FROM 1 BY 1 UNTIL K1 > ROWS-IN-SET MOVE SPACES TO OUT-REC PERFORM CONVERT-THE-FILE END-PERFORM. DISPLAY "ROWSET " ROWSET-NUM " (" ROWS-IN-SET " ROWS) COPIED". CONVERT-TO-ASCII. MOVE FUNCTION NATIONAL-OF(OUT-REC, 1140) TO OUT-REC-NAT. MOVE FUNCTION DISPLAY-OF(OUT-REC-NAT, 819) TO OUT-REC. STRING OUT-REC(1 : REC-SIZE) CRLF-STRUCT DELIMITED BY SIZE INTO OUT-REC. ADD 2 TO REC-SIZE. CONVERT-THE-FILE. MOVE SEQNO(K1) TO NUM-EDI. MOVE NUM-EDI TO OUT-SEQNO. MOVE 0 TO T1 T2. INSPECT OUT-SEQNO TALLYING T1 FOR LEADING SPACES. COMPUTE T2 = LENGTH OF OUT-SEQNO - T1. ADD 1 TO T1. STRING PLANNAME-TEXT(K1)(1 : PLANNAME-LEN(K1)) "," OUT-SEQNO (T1 : T2) "," LOCATION-TEXT(K1)(1 : LOCATION-LEN(K1)) "," COLLID-TEXT(K1)(1 : COLLID-LEN(K1)) "," NAME-TEXT(K1)(1 : NAME-LEN(K1)) "," TIMESTAMP(K1) "," IBMREQD(K1) DELIMITED BY SIZE INTO OUT-REC. MOVE 0 TO REC-SIZE. INSPECT FUNCTION REVERSE(OUT-REC) TALLYING REC-SIZE FOR LEADING SPACES. COMPUTE REC-SIZE = LENGTH OF OUT-REC - REC-SIZE. IF PARM-D(1 : PARM-L) = "ASCII" PERFORM CONVERT-TO-ASCII. WRITE OUT-REC. PERFORM CHECK-OUT-FILE. CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE MOVE 12 TO RETURN-CODE PERFORM CLEANUP STOP RUN END-IF. CHECK-OUT-FILE. IF OUT-STAT NOT = "00" DISPLAY "FILE ERROR OCCURED. PROGRAM ENDS." DISPLAY "FILE STATUS KEY: " OUT-STAT MOVE OUT-STAT TO RETURN-CODE PERFORM CLEANUP STOP RUN END-IF. CLEANUP. EXEC SQL CLOSE CSR END-EXEC. CLOSE OUT-FILE. SQL-COMMIT. EXEC SQL COMMIT END-EXEC.
Comments: - Source code shrank from 263 to 206 records. - Now data received and sent to the database is converted in-flight by DB2. So although our database is in CCSID = 367 (ASCII – US ANSI 3.4) we can process is as EBCDIC so use DISPLAY statement normally, copy data to file in EBCDIC and so on. - Thanks to that we could eliminate most conversion activities and greatly simplify the code. Now the only conversion that needs to be done, is the one back to ASCII. Differences between SQLCCSID and NOSQLCCSID option: - SQLCCSID option causes DB2 data convert data in-flight, so your programs can process it as EBCDIC, without any conversion instructions. - NOSQLCCSID option enables you to use DB2 co-processor with programs written with pre-compiler in mind. It won't make any data conversion. So you can run MP1307 code with this option and it will work fine. - SQLCCSID option decreases the performance of the program. So if you're coding a critical COBOL program that processes a lot of data coding in it NOSQLCCSID may be more cost-effective. There are also few differences between using pre-compiler and co-processor. They're nicely described in "Differences in how the DB2 precompiler and coprocessor behave" in "Enterprise COBOL for z/OS: Programming Guide". Important: - As you can see using DB2 co-processor with SQLCCSID option is not only recommended but also simplifies processing DB2 data greatly. With it, we don't have to worry that much of and character set used in DB2 since this part of the program is taken care by DB2 itself. The only exception to that rule is when your program processes huge amounts of DB2 data and you want to keep avoid performance degradation caused by SQLCCSID option.
Using copybooks
Introduction
COPY statement works similary to JCL INCLUDE statement. In enables you to paste the content of a given member into your source code. Unlike INCLUDE, COPY allows you to replace some words or parts of the words in the copied member. The copy is done at the beginning of the compilation process. The main use for COPY statement is coping SELECT and FD file definitions. Those definitions usually do not change and coding them in each program that works on a particular file is pretty annoying. Thanks to copybooks, in case the structure of such file is changed you have to modify only one copybook instead of all source codes that use this file. Still, all programs that use this copybook must be reviewed. But even that is easier, since there are tools in which you can list all programs that use given copybook, so you don't need to search them with documentation or manually. Another, less common use for copybooks is copying ready to use paragraphs or parts of the code. DECLARATIVES are good examples of paragraphs that can be shared by many programs.
Tasks
![]() 1. Write a program that reads a data set and displays its content.
- Include definitions from FILE-CONTROL and FILE SECTION inside separate members and use COPY statement to include them in the program.
- You can use the data set from Task#1 of "SORT & MERGE statements" Assignment.
1. Write a program that reads a data set and displays its content.
- Include definitions from FILE-CONTROL and FILE SECTION inside separate members and use COPY statement to include them in the program.
- You can use the data set from Task#1 of "SORT & MERGE statements" Assignment.
![]() 2. Copy the entire program from Task#1 of "SORT & MERGE statements" Assignment:
- Replace all FD & SD record definition with a single copy member and all three SELECT statements with another copy member.
2. Copy the entire program from Task#1 of "SORT & MERGE statements" Assignment:
- Replace all FD & SD record definition with a single copy member and all three SELECT statements with another copy member.
![]() 3. Modify program from Task#2:
- Define INPUT and OUTPUT PROCEDUREs that display file content before and after the sort.
- Design a universal DECLARATIVE section and set it up in copy member so you can use it for each data set processed in your programs.
- Test the program in various file error conditions.
3. Modify program from Task#2:
- Define INPUT and OUTPUT PROCEDUREs that display file content before and after the sort.
- Design a universal DECLARATIVE section and set it up in copy member so you can use it for each data set processed in your programs.
- Test the program in various file error conditions.
![]() 4. Modify program from Task#3:
- Write a copy member that calculates the length of the data in the given string.
- Use it in INPUT PROCEDURE to display length of item name for each record.
4. Modify program from Task#3:
- Write a copy member that calculates the length of the data in the given string.
- Use it in INPUT PROCEDURE to display length of item name for each record.
Hint 2
You'll have to use REPLACING keyword to replace parts of the text in the copied member. See "Enterprise COBOL for z/OS: Language Reference" for examples.
Solution 1
COBOL code:
//RUNCOBOL EXEC IGYWCLG,PARM.COBOL='LIB' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1401) //COBOL.SYSLIB DD DISP=SHR,DSN=&SYSUID..MY.COBOL.COPYBOOK //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1401. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. COPY ITEMSEL. DATA DIVISION. FILE SECTION. COPY ITEMFD. WORKING-STORAGE SECTION. 77 ITEM-FS PIC X(2). 77 ITEM-EOF PIC 9 VALUE 0. PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON ITEM-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'INFILE' STATUS: " ITEM-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF ITEM-FS NOT = "42" CLOSE ITEM-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. OPEN INPUT ITEM-FILE. PERFORM DISPLAY-THE-FILE. CLOSE ITEM-FILE. STOP RUN. DISPLAY-THE-FILE. READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. PERFORM UNTIL ITEM-EOF = 1 DISPLAY ITEM-RECORD READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF END-READ END-PERFORM. //GO.INFILE DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING
Comments: - To use COPY statement you need two things: library with copy members referenced in COBOL.SYSLIB DD statement and LIB compiler options. - COPY statement is resolved during compilation step. The content of the files is copied in place of COPY keyword so you must ensure that the content of copy members adhere to standard COBOL syntax.
Solution 2
COBOL code:
//RUNCOBOL EXEC IGYWCLG,PARM.COBOL='LIB' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1402) //COBOL.SYSLIB DD DISP=SHR,DSN=&SYSUID..MY.COBOL.COPYBOOK //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1402. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. COPY ITEMSEL REPLACING ==:TAG1:== BY ==ITEM== ==:TAG2:== BY ==IN1==. COPY ITEMSEL REPLACING ==:TAG1:== BY ==ITEMOUT== ==:TAG2:== BY ==OUT1==. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. COPY ITEMFD REPLACING ==:TAG1:== BY ==ITEM==. COPY ITEMFD REPLACING ==:TAG1:== BY ==ITEMOUT==. SD SORTWRK-FILE. COPY ITEMFD REPLACING ==FD :TAG1:-FILE RECORDING MODE F.== BY == == ==:TAG1:== BY ==SORTWRK==. WORKING-STORAGE SECTION. 77 ITEM-FS PIC X(2). 77 ITEMOUT-FS PIC X(2). 77 SORTWRK-FS PIC X(2). PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON ITEM-FILE ITEMOUT-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'IN1' STATUS: " ITEM-FS. DISPLAY "'OUT1' STATUS: " ITEMOUT-FS. DISPLAY "PROGRAM TERMINATES.". MOVE 12 TO RETURN-CODE. IF ITEM-FS NOT = "42" CLOSE ITEM-FILE. IF ITEMOUT-FS NOT = "42" CLOSE ITEMOUT-FILE. STOP RUN. END DECLARATIVES. MAIN-LOGIC. PERFORM SORT-RECORDS. STOP RUN. SORT-RECORDS. SORT SORTWRK-FILE DESCENDING KEY SORTWRK-DATE USING ITEM-FILE GIVING ITEMOUT-FILE. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.SORTED,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=27960,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
ITEMSEL copy member:
***************************************************************** * COPY MEMBER * SELECT DEFINITION FOR JSADEK.COBOL.SHOPPING.** DATA SETS * * TAG1 - FILE VARIABLES PREFIX * TAG2 - FILE DD STATEMENT * * INSTRUCTIONS: * - MAKE SURE YOU DEFINE ":TAG1:-FS" VARIABLE ***************************************************************** SELECT :TAG1:-FILE ASSIGN TO :TAG2: ORGANIZATION IS SEQUENTIAL FILE STATUS IS :TAG1:-FS.
ITEMFD copy member:
***************************************************************** * COPY MEMBER * FD DEFINITION FOR JSADEK.COBOL.SHOPPING.** DATA SETS * * TAG1 - FILE VARIABLES PREFIX ***************************************************************** FD :TAG1:-FILE RECORDING MODE F. 01 :TAG1:-RECORD. 05 :TAG1:-NAME PIC X(15). 05 FILLER PIC X. 05 :TAG1:-DATE PIC X(10). 05 FILLER PIC X. 05 :TAG1:-PRICE PIC X(9). 05 :TAG1:-CURRENCY PIC X. 05 FILLER PIC X. 05 :TAG1:-VAT PIC X(2).
There are basically three ways in which you replace data in copy member: - An entire word or set of words. In this case, you put replaced string inside "==" delimiters. ITEMFD replacement of SORTWRK file shows how it is done. - Partial words. To replace only part of the selected word you must additionally use delimiters ": :". As you can see from COPYBOOKs those tags should be appropriately set up and described. - LEADING and TRAILING options (introduced in COBOL 5.2). Those keywords can be used to simplify some REPLACING operations. Comments: - In comparison to the original program, only FILE-CONTROL paragraph and FILE SECTION were modified. - REPLACING keyword gives you some flexibility for working with COPYBOOKs. In the above example, you can see how SELECT, FD and SD definitions were replaced with copybooks. - SORTWRK file needs special mention. It would seem that we could simply use "REPLACING ==FD== by ==SD==". But REPLACING keyword does not work in Area A. In this example, "SD" would be replaced with "FD" but it would be also moved to Area B which would cause a syntax error. Because of that, a workaround had to be applied. The entire FD line was replaced with a blank and SD line was kept in the main source code.
Solution 3
COBOL code:
//RUNCOBOL EXEC IGYWCLG,PARM.COBOL='LIB' //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1403) //COBOL.SYSLIB DD DISP=SHR,DSN=&SYSUID..MY.COBOL.COPYBOOK //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1403. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. COPY ITEMSEL REPLACING ==:TAG1:== BY ==ITEM== ==:TAG2:== BY ==IN1==. COPY ITEMSEL REPLACING ==:TAG1:== BY ==ITEMOUT== ==:TAG2:== BY ==OUT1==. SELECT SORTWRK-FILE ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. COPY ITEMFD REPLACING ==:TAG1:== BY ==ITEM==. COPY ITEMFD REPLACING ==:TAG1:== BY ==ITEMOUT==. SD SORTWRK-FILE. COPY ITEMFD REPLACING ==FD :TAG1:-FILE RECORDING MODE F.== BY == == ==:TAG1:== BY ==SORTWRK==. WORKING-STORAGE SECTION. 77 ITEM-FS PIC X(2). 77 ITEMOUT-FS PIC X(2). 77 ITEM-EOF PIC 9 VALUE 0. 77 SORTWRK-EOF PIC 9 VALUE 0. PROCEDURE DIVISION. DECLARATIVES. COPY FILEDECL REPLACING ==:TAG1:== BY ==ITEM-FILE== ==:TAG2:== BY ==ITEM-FS== ==PLACEHOLDER1== BY ==IF ITEMOUT-FS NOT = "42" CLOSE ITEMOUT-FILE==. COPY FILEDECL REPLACING ==:TAG1:== BY ==ITEMOUT-FILE== ==:TAG2:== BY ==ITEMOUT-FS== ==PLACEHOLDER1== BY ==IF ITEM-FS NOT = "42" CLOSE ITEM-FILE== ==PLACEHOLDER2== BY ==DISPLAY "GOOD BYE."==. END DECLARATIVES. MAIN-LOGIC. PERFORM OPEN-FILES. PERFORM SORT-RECORDS. PERFORM CLOSE-FILES. STOP RUN. OPEN-FILES. OPEN INPUT ITEM-FILE. OPEN OUTPUT ITEMOUT-FILE. CLOSE-FILES. CLOSE ITEM-FILE. CLOSE ITEMOUT-FILE. SORT-RECORDS. SORT SORTWRK-FILE DESCENDING KEY SORTWRK-DATE INPUT PROCEDURE PRE-SORT-PROC OUTPUT PROCEDURE POST-SORT-PROC. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL. PROGRAM TERMINATE." MOVE SORT-RETURN TO RETURN-CODE STOP RUN END-IF. PRE-SORT-PROC. DISPLAY "RECORDS BEFORE SORTING:". READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. PERFORM UNTIL ITEM-EOF = 1 DISPLAY ITEM-RECORD RELEASE SORTWRK-RECORD FROM ITEM-RECORD READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF END-READ END-PERFORM. DISPLAY " ". POST-SORT-PROC. DISPLAY "RECORDS AFTER SORTING:". RETURN SORTWRK-FILE RECORD INTO ITEMOUT-RECORD AT END MOVE 1 TO SORTWRK-EOF. PERFORM UNTIL SORTWRK-EOF = 1 DISPLAY ITEMOUT-RECORD WRITE ITEMOUT-RECORD RETURN SORTWRK-FILE RECORD INTO ITEMOUT-RECORD AT END MOVE 1 TO SORTWRK-EOF END-RETURN END-PERFORM. DISPLAY " ". //GO.SYSOUT DD SYSOUT=* //GO.IN1 DD DISP=SHR,DSN=JSADEK.COBOL.SHOPPING //GO.OUT1 DD DSN=JSADEK.COBOL.SHOPPING.SORTED,DISP=(NEW,CATLG), // SPACE=(TRK,(1,1)),LRECL=40,BLKSIZE=4000,RECFM=FB //GO.SORTWRK DD DSN=&&TEMP,DISP=(NEW,DELETE,DELETE), // LIKE=JSADEK.COBOL.SHOPPING
FILEDECL member:
***************************************************************** * COPYBOOK * UNIVERSAL FILE ERROR PROCEDURE THAT TERMINATES * THE PROGRAM WITH RC = 15 * * TAG1 - FILE NAME DEFINED IN SELECT STATEMENT * TAG2 - FILE STATUS DEFINED IN FILE STATUS STMT * * INSTRUCTIONS: * - YOU CAN REPLACE PLACEHOLDER DUMMY PARAGRAPHS WITH SOME * ADDITIONAL INSTRUCTIONS, LIKE CLOSING OTHER FILES. ***************************************************************** FILE-:TAG1:-ERROR SECTION. USE AFTER ERROR PROCEDURE ON :TAG1:. FILE-:TAG1:-ERRORS. DISPLAY "FILE ERROR OCCUREED. PROGRAM TERMINATES.". DISPLAY "FILE STATUS CODE: " :TAG2:. MOVE 15 TO RETURN-CODE. IF :TAG2: NOT = "42" CLOSE :TAG1:. PLACEHOLDER1. PLACEHOLDER2. PLACEHOLDER3. STOP RUN.
Comments: - In this example, you can see next great use of copy books. Unless you expect some specific file conditions you'll usually reuse your ERROR PROCEDUREs for file error handling. You can save yourself a lot of work by designing a universal error handling procedure and putting it in the COPYBOOK. - You can also see a trick how you can insert some lines into a copy member. You can define empty paragraph names (PLACEHOLDERn) and replace them with any COBOL instructions. In this case, we used this trick to leave a place for the closing instructions for other files used in the program. - REPLACING statement doesn't work inside literals, so we cannot display the name of the file in error. - REPLACING keyword also doesn't work in Area A. The text in area A can be found and replaced but after the replacement, it will be moved to Area B. You can see that in this example where paragram name PLACEHOLDER1 string in Area A, after the replacement is written into Area B.
Solution 4
Modified paragraph:
PRE-SORT-PROC. DISPLAY "RECORDS BEFORE SORTING:". READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF. PERFORM UNTIL ITEM-EOF = 1 COPY LENGTH1 REPLACING ==:TAG1:== BY ==ITEM-NAME== ==:TAG2:== BY ==TEMPNUM==. DISPLAY ITEM-RECORD ", NAME-LENGTH: " TEMPNUM RELEASE SORTWRK-RECORD FROM ITEM-RECORD READ ITEM-FILE AT END MOVE 1 TO ITEM-EOF END-READ END-PERFORM. DISPLAY " ".
LENGTH1 copy member:
***************************************************************** * COPYBOOK * UNIVERSAL PROCEDURE FOR CALCULATING LENGTH OF THE DATA * INSIDE THE STRING * * TAG1 - STRING THAT IS INSPECTED * TAG2 - INTEGER VARIABLE THAT WILL STORE STRING LENGTH * * INSTRUCTIONS: * - THIS VERSION DOES NOT CONTAIN DOTS SO IT SHOULD BE USED * INSIDE PERFORM OF IF STATEMENTS. ***************************************************************** MOVE 0 TO :TAG2: INSPECT FUNCTION REVERSE(:TAG1:) TALLYING :TAG2: FOR LEADING SPACES COMPUTE :TAG2: = LENGTH OF :TAG1: - :TAG2:
Comments: - Another not that common use of copy members are small functions, code chunks that realize some simple functionality. Calculating length, date operations, or CCSID conversions are just a few ideas of how you can utilize copybooks. - In this copy member we didn't have to use ": :" characters, they are needed only when you need to replace part of the word. But they also improve readability so you may want to use them anyway.
Working with DB2 – Part II – Locks & Performance
Introduction
In DB2 & SQL tab there are many assignments teaching the basics regarding locking mechanism in DB2 and various performance improving techniques. Knowlege included there should be considered mandatory for every COBOL Developer since this language nearly always interfaces with DB2, CICS or both. It's generally considered that 80% of performance issues are caused by the code. Those include programming specific issues, such as using single-row fetch instead of multi-row, and also issues with SQL queries. Good practices dictate that there should be a DBA specialist in every software development team who's main responsibility is reviewing SQL queries coded by developers (at least those most imporant, which are known to run hundreds and thousands of times each day). Such person checks SQL both from the perspective of data integrity, if locks are designed correctly, and query performance. Whether you're a developer or DBA cooperating with developers, you need to also know language specific optimization techniques. In this Assignment we'll take a look at the performance and locking basics in Application programs.
Tasks
![]() 1. Rule #1: Multi-row fetch is much faster than single-row fetch.
- Write a COBOL program that displays all employees born in 1964 or later.
- Compare performance of a single-row fetch and a multi-row fetch with 10, 20, 100, 500, and 2000 rows in a set.
1. Rule #1: Multi-row fetch is much faster than single-row fetch.
- Write a COBOL program that displays all employees born in 1964 or later.
- Compare performance of a single-row fetch and a multi-row fetch with 10, 20, 100, 500, and 2000 rows in a set.
![]() 2. Rule #2: Design your lock correctly.
- Modify the program from Task#1 - add a paragraph which holds the job for a while just after the end of data fetching.
- While the program is held, check what locks are held on the table in following cases: Isolation(CS) specified in BIND command, Isolation(RR) in BIND command. Isolation(RR) in BIND and CS in SELECT statement. Isolation(CS) in BIND and RR in SELECT statement.
- Compare the results as well as query performance.
2. Rule #2: Design your lock correctly.
- Modify the program from Task#1 - add a paragraph which holds the job for a while just after the end of data fetching.
- While the program is held, check what locks are held on the table in following cases: Isolation(CS) specified in BIND command, Isolation(RR) in BIND command. Isolation(RR) in BIND and CS in SELECT statement. Isolation(CS) in BIND and RR in SELECT statement.
- Compare the results as well as query performance.
![]() 3. Rule #3: Use COMMIT ASAP.
- Use the program from Task#2.
- Hold the program after OPEN CURSOR statements and FETCH statements. At which point lock on the table is created?
- Issue COMMIT command before holding the program. Does the lock still persists?
- Test DEALLOCATE BIND option. How it differs from COMMIT?
3. Rule #3: Use COMMIT ASAP.
- Use the program from Task#2.
- Hold the program after OPEN CURSOR statements and FETCH statements. At which point lock on the table is created?
- Issue COMMIT command before holding the program. Does the lock still persists?
- Test DEALLOCATE BIND option. How it differs from COMMIT?
![]() 4. Rule #4: Consider using WITH UR to improve performance.
- Modify the program from Task#2.
- FETCH all employee records who have ever earned 100000 USD/year or more.
- This time don't display the fetched data. This way you'll you'll eliminate one factor influencing program performance.
- Compare the performance of isolation level RR, CS and UR.
4. Rule #4: Consider using WITH UR to improve performance.
- Modify the program from Task#2.
- FETCH all employee records who have ever earned 100000 USD/year or more.
- This time don't display the fetched data. This way you'll you'll eliminate one factor influencing program performance.
- Compare the performance of isolation level RR, CS and UR.
![]() 5. Rule #5: Use OPTIMIZE FOR clause wisely.
- Rerun the program from Task#4.
- Test program performance with and without OPTIMIZE FOR clause.
- Modify the program, go back to single-row fetch and repeat the experiment in three cases: Without OPTIMIZE FOR clause, with OPTIMIZE FOR 1 ROWS, and with OPTIMIZE FOR 10 ROWS.
5. Rule #5: Use OPTIMIZE FOR clause wisely.
- Rerun the program from Task#4.
- Test program performance with and without OPTIMIZE FOR clause.
- Modify the program, go back to single-row fetch and repeat the experiment in three cases: Without OPTIMIZE FOR clause, with OPTIMIZE FOR 1 ROWS, and with OPTIMIZE FOR 10 ROWS.
![]() 6. Rule #6: When getting a specific row, always use FETCH FOR 1 ROW ONLY.
- Issue a SELECT which gets the name and the current salary of a employee with a specific ID.
- Repeat the query in loop for IDs 10001 - 50000.
- Don't display the data to get accurate query times.
6. Rule #6: When getting a specific row, always use FETCH FOR 1 ROW ONLY.
- Issue a SELECT which gets the name and the current salary of a employee with a specific ID.
- Repeat the query in loop for IDs 10001 - 50000.
- Don't display the data to get accurate query times.
![]() 7. Rule #7: Let the DB2 do the work - Part I.
- Modify the program from Task#4.
- Display all employee records who have ever earned 100000 USD/year or more.
- Convert the names to upper-case using COBOL UPPER-CASE functions and then SQL UCASE.
7. Rule #7: Let the DB2 do the work - Part I.
- Modify the program from Task#4.
- Display all employee records who have ever earned 100000 USD/year or more.
- Convert the names to upper-case using COBOL UPPER-CASE functions and then SQL UCASE.
![]() 8. Rule #7: Let the DB2 do the work - Part II.
Modify the program from Task#4.
- This time display only records with current employee salaries, so with TO_DATE='9999-01-01'.
- Sort the records from the lowest to highest salary (above 100000) using ORDER BY function and then using SORT COBOL function.
8. Rule #7: Let the DB2 do the work - Part II.
Modify the program from Task#4.
- This time display only records with current employee salaries, so with TO_DATE='9999-01-01'.
- Sort the records from the lowest to highest salary (above 100000) using ORDER BY function and then using SORT COBOL function.
Solution 1
COBOL source:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1501. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBEMP2 END-EXEC. 01 START-TIME. 05 S-HOUR PIC 9(2). 05 S-MINUTES PIC 9(2). 05 S-SECONDS PIC 9(2). 05 S-HMILI PIC 9(2). 01 END-TIME. 05 E-HOUR PIC 9(2). 05 E-MINUTES PIC 9(2). 05 E-SECONDS PIC 9(2). 05 E-HMILI PIC 9(2). 77 K1 PIC 9(9) VALUE 0. 77 K2 PIC 9(9). 77 NUM-EDI PIC -(9)9. 77 BDATE PIC X(10). 77 S-TIME PIC S9(18). 77 E-TIME PIC S9(18). 77 ROWS-IN-SET PIC 9(9). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM DISP-START-TIME. PERFORM INIT-CSR. PERFORM FETCH-ROWSET UNTIL SQLCODE NOT = 0. PERFORM DISP-END-TIME. PERFORM CLEANUP. STOP RUN. INIT-CSR. MOVE '1964-01-01' TO BDATE. EXEC SQL DECLARE C1 CURSOR WITH ROWSET POSITIONING FOR SELECT FIRST_NAME, LAST_NAME FROM MPDB.EMTBEMPL WHERE BIRTH_DATE >= :BDATE END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN C1 END-EXEC. PERFORM CHECK-EXECSQL. FETCH-ROWSET. INITIALIZE EMPL-REC. EXEC SQL FETCH NEXT ROWSET FROM C1 FOR 10 ROWS INTO :FIRST-NAME, :LAST-NAME END-EXEC. MOVE SQLERRD(3) TO ROWS-IN-SET. PERFORM VARYING K2 FROM 1 BY 1 UNTIL K2 > ROWS-IN-SET ADD 1 TO K1 DISPLAY "EMP " K1 ": " FIRST-NAME-TEXT(K2) " " LAST-NAME-TEXT(K2) END-PERFORM. * PERFORM CHECK-EXECSQL. DISP-START-TIME. ACCEPT START-TIME FROM TIME. DISPLAY "SQL START TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "--------------------------------------". DISP-END-TIME. DISPLAY "--------------------------------------". ACCEPT END-TIME FROM TIME. DISPLAY "SQL STA TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "SQL END TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. COMPUTE S-TIME = S-HMILI + S-SECONDS * 100 + S-MINUTES * 6000 + S-HOUR * 360000. COMPUTE E-TIME = E-HMILI + E-SECONDS * 100 + E-MINUTES * 6000 + E-HOUR * 360000. COMPUTE E-TIME = E-TIME - S-TIME. IF E-TIME < 0 ADD 8640000 TO E-TIME. COMPUTE E-HOUR = E-TIME / 360000. COMPUTE E-TIME = E-TIME - E-HOUR * 360000. COMPUTE E-MINUTES = E-TIME / 6000. COMPUTE E-TIME = E-TIME - E-MINUTES * 6000. COMPUTE E-SECONDS = E-TIME / 100. COMPUTE E-TIME = E-TIME - E-SECONDS * 100. COMPUTE E-HMILI = E-TIME. DISPLAY "SQL RUN TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. DISPLAY "--------------------------------------". CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE STOP RUN END-IF. CLEANUP. EXEC SQL CLOSE C1 END-EXEC.
When testing query performance in any program you must be aware that other program instructions will also influence your performance results. Because of that you should minimize number of instruction executed during the query and measure times straight before and after it. 00:00:19.83 - 1 row 00:00:13.79 - 10 rows 00:00:13.16 - 20 rows 00:00:12.70 - 100 rows 00:00:12.45 - 500 rows 00:00:12.52 - 2000 rows As you can see the biggest jump in performance happened after switching from single-row fetch to multi-row fetch. Further gains due to the increase in rowset size doesn't bring that much of a difference but are still significant. In this example, there is probably no point in fetching more than 200 rows in one fetch. It is generally considered that multi-row fetch is 50-60% faster than single-row fetch. This test confirms that. We've gained 59%. The amount of rows fetched often depends on the program logic. For example, when a customer displays the last 20 transactions on his account there is no point fetching more data. But in cases when you have a choice, be sure to use multi-row fetch and to test it for the optimum between query performance and memory usage.
Solution 2
To hold the job you can use a wait paragraph or you can issue a WTOR with "ACCEPT K2 FROM CONSOLE." instruction for example. Isolation(CS) in BIND: - Lock: H-IS,P,C - Time: 00:00:12.65 Isolation(RR) in BIND: - Lock: H-S,P,C - Time: 00:00:12.66 Isolation(RR) in BIND and CS in SELECT: - Lock: H-IS,P,C - Time: 00:00:12.70 Isolation(CS) in BIND and RR in SELECT: - Lock: H-S,P,C - Time: 00:00:12.44 Comments: - Isolation specified in BIND command is the default isolation level which may be overwritten by the SQL inside the code. - The locks are released after the point specified in RELEASE parameter in BIND command. Imagine a situation, where after this SELECT you would further process the data for 15 minutes. This would leave the lock on the table for those 15 minutes! - RR and CS isolation levels generally run just as fast, after all both modes create the same number of locks, just a different type so the difference here lies not in performance but with possible problems due to deadlocks and timeouts.
Solution 3
Comments: - If you don't specify COMMIT command even with SELECT statement, the locks allocated by your programs will last until the program ends. It means that if your program runs for an hour after the fetch is done, the pages or rows locked by this program will stay blocked for this hour. This is an unacceptable situation in any program. - Good coding practice states that you should minimize the time frame of SQL processing. Which in this example means that the time between FETCH and COMMIT should be as short as possible. This way you minimize the duration of locks created by your program. - The lock is not created by DECLARE or OPEN CURSON statements. The data is getting locked from the start of FETCH instructions. Which means that you can safely do some processing between OPEN and FETCH instruction without worrying about locks. - DEALLOCATE statement in BIND command will keep the lock until program ends. This is usually undesired. Even in cases, where you code further logic checking is some update operation is correct and depending on it issue COMMIT or ROLLBACK, it's still better to use COMMIT keyword. - If you perform multiple SQL operations in the program, you should consider if you can issue COMMIT after each or some of them and this way free the locks taken by the program while it's still executing. If that's possible, it depends on a program logic, but if it is, you should definitely do that.
Solution 4
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1504. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBEMP2 END-EXEC. EXEC SQL INCLUDE EMTBSLR2 END-EXEC. 01 START-TIME. 05 S-HOUR PIC 9(2). 05 S-MINUTES PIC 9(2). 05 S-SECONDS PIC 9(2). 05 S-HMILI PIC 9(2). 01 END-TIME. 05 E-HOUR PIC 9(2). 05 E-MINUTES PIC 9(2). 05 E-SECONDS PIC 9(2). 05 E-HMILI PIC 9(2). 77 K1 PIC 9(9) VALUE 0. 77 K2 PIC 9(9). 77 NUM-EDI PIC -(9)9. 77 SLRYLIM PIC S9(9) USAGE COMP. 77 S-TIME PIC S9(18). 77 E-TIME PIC S9(18). 77 ROWS-IN-SET PIC 9(9). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM DISP-START-TIME. PERFORM INIT-CSR. PERFORM FETCH-ROWSET UNTIL SQLCODE NOT = 0. PERFORM SQL-COMMIT. PERFORM DISP-END-TIME. PERFORM CLEANUP. STOP RUN. INIT-CSR. MOVE 100000 TO SLRYLIM. EXEC SQL DECLARE C1 CURSOR WITH ROWSET POSITIONING FOR SELECT FIRST_NAME, LAST_NAME, SALARY FROM EMTBEMPL, EMTBSLRY WHERE SALARY >= :SLRYLIM AND EMTBEMPL.EMP_NO = EMTBSLRY.EMP_NO WITH UR END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN C1 END-EXEC. PERFORM CHECK-EXECSQL. FETCH-ROWSET. INITIALIZE EMPL-REC SLRY-REC. EXEC SQL FETCH NEXT ROWSET FROM C1 FOR 20 ROWS INTO :FIRST-NAME, :LAST-NAME, :SALARY END-EXEC. MOVE SQLERRD(3) TO ROWS-IN-SET. * PERFORM VARYING K2 FROM 1 BY 1 UNTIL K2 > ROWS-IN-SET * ADD 1 TO K1 * DISPLAY "EMP " K1 ": " FIRST-NAME-TEXT(K2) * " " LAST-NAME-TEXT(K2) " - " SALARY(K2) * END-PERFORM. * PERFORM CHECK-EXECSQL. DISP-START-TIME. ACCEPT START-TIME FROM TIME. DISPLAY "SQL START TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "--------------------------------------". DISP-END-TIME. DISPLAY "--------------------------------------". ACCEPT END-TIME FROM TIME. DISPLAY "SQL STA TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "SQL END TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. COMPUTE S-TIME = S-HMILI + S-SECONDS * 100 + S-MINUTES * 6000 + S-HOUR * 360000. COMPUTE E-TIME = E-HMILI + E-SECONDS * 100 + E-MINUTES * 6000 + E-HOUR * 360000. COMPUTE E-TIME = E-TIME - S-TIME. IF E-TIME < 0 ADD 8640000 TO E-TIME. COMPUTE E-HOUR = E-TIME / 360000. COMPUTE E-TIME = E-TIME - E-HOUR * 360000. COMPUTE E-MINUTES = E-TIME / 6000. COMPUTE E-TIME = E-TIME - E-MINUTES * 6000. COMPUTE E-SECONDS = E-TIME / 100. COMPUTE E-TIME = E-TIME - E-SECONDS * 100. COMPUTE E-HMILI = E-TIME. DISPLAY "SQL RUN TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. DISPLAY "--------------------------------------". CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE STOP RUN END-IF. SQL-COMMIT. EXEC SQL COMMIT END-EXEC. PERFORM CHECK-EXECSQL. CLEANUP. EXEC SQL CLOSE C1 END-EXEC.
WITH RR: 00:01:06.19 WITH CS: 00:01:06.48 WITH UR: 00:01:04.38 As seen in this example there is no difference between isolation level RR and CS, after all, in both case the same number of locks is issued, just a different type. We got a slight increase using UR. So if you're certain you can safely use UR, it will be the best choice performance-wise. If you are not sure about that, it's better to stay with safer isolation levels.
Solution 5
Multi-row fetch: WITHOUT OPTIMIZE: 00:01:06.48 OPTIMIZE FOR 20 ROWS: 00:01:14.74 When you use FETCH FOR n ROWS DB2 already optimizes such query for that amount of rows, therefore, using OPTIMIZE FOR with FETCH doesn't make sense. More so, as seen in results it messes up FETCH optimization and gives worse performance. Single-row fetch: WITHOUT OPTIMIZE: 00:01:33.62 OPTIMIZE FOR 1 ROWS: 00:01:40.99 OPTIMIZE FOR 10 ROWS: 00:01:41.54 The results are very similar with a single-row fetch. So although OPTIMIZE FOR can speed up some queries, especially done on distributed servers, there are also cases in which it degrades performance, therefore you should always test how it affects the actual query performance in a given program.
Solution 6
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1506. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBEMPL END-EXEC. EXEC SQL INCLUDE EMTBSLRY END-EXEC. 01 START-TIME. 05 S-HOUR PIC 9(2). 05 S-MINUTES PIC 9(2). 05 S-SECONDS PIC 9(2). 05 S-HMILI PIC 9(2). 01 END-TIME. 05 E-HOUR PIC 9(2). 05 E-MINUTES PIC 9(2). 05 E-SECONDS PIC 9(2). 05 E-HMILI PIC 9(2). 77 K1 PIC 9(9) VALUE 0. 77 K2 PIC S9(9) COMP. 77 NUM-EDI PIC -(9)9. 77 S-TIME PIC S9(18). 77 E-TIME PIC S9(18). 77 TDATE PIC X(10). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM DISP-START-TIME. PERFORM FETCH-THE-DATA. PERFORM SQL-COMMIT. PERFORM DISP-END-TIME. STOP RUN. FETCH-THE-DATA. MOVE 10000 TO K2. MOVE '9999-01-01' TO TDATE. PERFORM UNTIL K2 > 50000 PERFORM FETCH-A-ROW IF SQLCODE = 0 ADD 1 TO K1 * DISPLAY "EMP " K1 ": " FIRST-NAME-TEXT * " " LAST-NAME-TEXT " - " SALARY END-IF ADD 1 TO K2 END-PERFORM. DISPLAY "COUNT: " K1. FETCH-A-ROW. INITIALIZE EMPL-REC SLRY-REC. EXEC SQL SELECT FIRST_NAME, LAST_NAME, SALARY INTO :FIRST-NAME, :LAST-NAME, :SALARY FROM EMTBEMPL, EMTBSLRY WHERE EMTBEMPL.EMP_NO = :K2 AND EMTBEMPL.EMP_NO = EMTBSLRY.EMP_NO AND TO_DATE = :TDATE END-EXEC. DISP-START-TIME. ACCEPT START-TIME FROM TIME. DISPLAY "SQL START TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "--------------------------------------". DISP-END-TIME. DISPLAY "--------------------------------------". ACCEPT END-TIME FROM TIME. DISPLAY "SQL STA TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "SQL END TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. COMPUTE S-TIME = S-HMILI + S-SECONDS * 100 + S-MINUTES * 6000 + S-HOUR * 360000. COMPUTE E-TIME = E-HMILI + E-SECONDS * 100 + E-MINUTES * 6000 + E-HOUR * 360000. COMPUTE E-TIME = E-TIME - S-TIME. IF E-TIME < 0 ADD 8640000 TO E-TIME. COMPUTE E-HOUR = E-TIME / 360000. COMPUTE E-TIME = E-TIME - E-HOUR * 360000. COMPUTE E-MINUTES = E-TIME / 6000. COMPUTE E-TIME = E-TIME - E-MINUTES * 6000. COMPUTE E-SECONDS = E-TIME / 100. COMPUTE E-TIME = E-TIME - E-SECONDS * 100. COMPUTE E-HMILI = E-TIME. DISPLAY "SQL RUN TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. DISPLAY "--------------------------------------". CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE STOP RUN END-IF. SQL-COMMIT. EXEC SQL COMMIT END-EXEC. PERFORM CHECK-EXECSQL.
Without FETCH FIRST: 00:01:53.53 With FETCH FIRST: 00:01:02.11 Comments: - We've issued the query 32000 times to see the real difference between queries with and without FETCH FIRST 1 ROW ONLY. - In reality, we're talking here about a situation where the program needs one specific record. So this test simulates a program which would be executed 32000 per day. And there are programs which are executed much more than that. - In such case, we don't need cursors and we can issue a simple query like in this example. Of course not in a loop but to extract a specific row. - As you can see using FETCH FIRST clause nearly doubles the query speed. This makes perfect sense because without FETCH FIRST clause DB2 will extract the first record and then search for the next one which doesn't exist. So thanks to that simple trick we cut in half the amount of records DB2 needs to search for.
Solution 7
COBOL UPPER-CASE: 00:01:23.22 SQL UCASE: 00:01:28.53 The "Let DB2 do the work rule" states that SQL processing is usually faster and it can process the data at earlier stages which additionally improves the performance of the program. In this example, we can see this is another "it depends" rule. Here, using COBOL function for converting characters to upper-case was much faster. Another situation in which COBOL would be faster are all cases where DB2 would have to apply the function before creating the final result set (on more rows that are actually passed to the COBOL in the result set).
Solution 8
COBOL code for COBOL internal sorting:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1508. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT SORTWRK ASSIGN TO SORTWRK. DATA DIVISION. FILE SECTION. SD SORTWRK. 01 SORTWRK-REC. 05 SW-FNAME PIC X(14). 05 SW-LNAME PIC X(14). 05 SW-SLRY PIC S9(9) USAGE COMP. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBEMP2 END-EXEC. EXEC SQL INCLUDE EMTBSLR2 END-EXEC. 77 SORTWRK-EOF PIC 9 VALUE 0. 01 START-TIME. 05 S-HOUR PIC 9(2). 05 S-MINUTES PIC 9(2). 05 S-SECONDS PIC 9(2). 05 S-HMILI PIC 9(2). 01 END-TIME. 05 E-HOUR PIC 9(2). 05 E-MINUTES PIC 9(2). 05 E-SECONDS PIC 9(2). 05 E-HMILI PIC 9(2). 77 K1 PIC 9(9) VALUE 0. 77 K2 PIC 9(9). 77 NUM-EDI PIC -(9)9. 77 SLRYLIM PIC S9(9) USAGE COMP. 77 S-TIME PIC S9(18). 77 E-TIME PIC S9(18). 77 ROWS-IN-SET PIC 9(9). 77 BDATE PIC X(10). PROCEDURE DIVISION. MAIN-LOGIC. MOVE "SORTMSG" TO SORT-MESSAGE. PERFORM DISP-START-TIME. PERFORM INIT-CSR. SORT SORTWRK ASCENDING KEY SW-SLRY INPUT PROCEDURE PRE-SORT-PROC OUTPUT PROCEDURE POST-SORT-PROC. PERFORM SQL-COMMIT. PERFORM DISP-END-TIME. PERFORM CLEANUP. STOP RUN. INIT-CSR. MOVE 100000 TO SLRYLIM. MOVE '9999-01-01' TO BDATE. EXEC SQL DECLARE C1 CURSOR WITH ROWSET POSITIONING FOR SELECT FIRST_NAME, LAST_NAME, SALARY FROM EMTBEMPL, EMTBSLRY WHERE SALARY >= :SLRYLIM AND EMTBEMPL.EMP_NO = EMTBSLRY.EMP_NO ORDER BY SALARY ASC END-EXEC. PERFORM CHECK-EXECSQL. EXEC SQL OPEN C1 END-EXEC. PERFORM CHECK-EXECSQL. PRE-SORT-PROC. PERFORM FETCH-ROWSET UNTIL SQLCODE NOT = 0. POST-SORT-PROC. RETURN SORTWRK AT END MOVE 1 TO SORTWRK-EOF END-RETURN PERFORM VARYING K2 FROM 1 BY 1 UNTIL SORTWRK-EOF = 1 DISPLAY "EMP " K2 ": " SW-FNAME " " SW-LNAME " - " SW-SLRY RETURN SORTWRK AT END MOVE 1 TO SORTWRK-EOF END-RETURN END-PERFORM. FETCH-ROWSET. INITIALIZE EMPL-REC. EXEC SQL FETCH NEXT ROWSET FROM C1 FOR 20 ROWS INTO :FIRST-NAME, :LAST-NAME, :SALARY END-EXEC. MOVE SQLERRD(3) TO ROWS-IN-SET. PERFORM VARYING K2 FROM 1 BY 1 UNTIL K2 > ROWS-IN-SET ADD 1 TO K1 MOVE FIRST-NAME-TEXT(K2) TO SW-FNAME MOVE LAST-NAME-TEXT(K2) TO SW-LNAME MOVE SALARY(K2) TO SW-SLRY RELEASE SORTWRK-REC END-PERFORM. DISP-START-TIME. ACCEPT START-TIME FROM TIME. DISPLAY "SQL START TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "--------------------------------------". DISP-END-TIME. DISPLAY "--------------------------------------". ACCEPT END-TIME FROM TIME. DISPLAY "SQL STA TIME: " S-HOUR ":" S-MINUTES ":" S-SECONDS "." S-HMILI. DISPLAY "SQL END TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. COMPUTE S-TIME = S-HMILI + S-SECONDS * 100 + S-MINUTES * 6000 + S-HOUR * 360000. COMPUTE E-TIME = E-HMILI + E-SECONDS * 100 + E-MINUTES * 6000 + E-HOUR * 360000. COMPUTE E-TIME = E-TIME - S-TIME. IF E-TIME < 0 ADD 8640000 TO E-TIME. COMPUTE E-HOUR = E-TIME / 360000. COMPUTE E-TIME = E-TIME - E-HOUR * 360000. COMPUTE E-MINUTES = E-TIME / 6000. COMPUTE E-TIME = E-TIME - E-MINUTES * 6000. COMPUTE E-SECONDS = E-TIME / 100. COMPUTE E-TIME = E-TIME - E-SECONDS * 100. COMPUTE E-HMILI = E-TIME. DISPLAY "SQL RUN TIME: " E-HOUR ":" E-MINUTES ":" E-SECONDS "." E-HMILI. DISPLAY "--------------------------------------". CHECK-EXECSQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO NUM-EDI DISPLAY "SQL ERROR OCCURED" DISPLAY "SQLCODE : " NUM-EDI DISPLAY "SQLSTATE: " SQLSTATE STOP RUN END-IF. SQL-COMMIT. EXEC SQL COMMIT END-EXEC. PERFORM CHECK-EXECSQL. CLEANUP. EXEC SQL CLOSE C1 END-EXEC.
DB2 SORT: 00:01:32.87 COBOL SORT: 00:01:38.25 From the previous task, you know that not all SQL processing is faster than COBOL based one. Here you see an example of a processing which should be done always via SQL, so various operations which require data sorts, such as GROUP BY, ORDER BY, DISTINCT, JOINs and so on. Here are just a few reasons for that: - DB2 sorts are much faster. - You need less code, so it results in savings for programmer salaries. - Sorting via COBOL instead of DB2 increases the probability of errors. - DB2 sort can utilize indexes, COBOL sort cannot. - SQL statements can be modified/optimized more easily than COBOL code.
Good Coding Practices
Introduction
Each and every COBOL development team has, or at least should have, a set of clearly defined programming standards used by everyone working within the team. This ensures a few important things: - That the new, less-experienced programmers can easily avoid most common programming errors. - That all programmers are obligated to follow best coding practices instead of going with a tempting "quick and dirty" approach. - That a specific naming convention is used in the code which speeds up program analysis and ensures consistent code structure for all programs. - That all programs are well-documented and therefore easier to modify in the future, even for someone who's not fully familiar with a particular code. - That the code is created faster. - That all code modifications are well documented. - That all programmers use performance efficient solutions. - That all programmers use techniques which minimize the probability of errors. As not hard to notice, all the programs on this website use the "quick and dirty" approach. This way more materials could end up on Mainframe Playground. Further programs will also follow this path but in this Assignment, we'll code how it should be coded. We'll explore various practices that make the code more readable, more error-free, and easier to analyze and maintain.
Tasks
![]() 1. Remember about the design phase.
Create a diagram or pseudocode for the program described below:
- The program should read the file with the following record structure: personal number, first name, last name, gender, birth date, death date.
- The program should display all the records from the file sorted via birth date alongside the calculated life span for a given person in years and days.
- Consider cases where people are still alive and dead. Use '9999-01-01' death date to indicate that a person is still alive.
1. Remember about the design phase.
Create a diagram or pseudocode for the program described below:
- The program should read the file with the following record structure: personal number, first name, last name, gender, birth date, death date.
- The program should display all the records from the file sorted via birth date alongside the calculated life span for a given person in years and days.
- Consider cases where people are still alive and dead. Use '9999-01-01' death date to indicate that a person is still alive.
![]() 2. Follow the agreed naming convention.
Design your own naming convention for following language elements:
- Program names.
- Paragraph names.
- Variable names.
- Structures.
- Tables.
- File names.
- DCLGEN table definitions.
- Parameters.
Modify the code from Task#1 so it follows new standards.
2. Follow the agreed naming convention.
Design your own naming convention for following language elements:
- Program names.
- Paragraph names.
- Variable names.
- Structures.
- Tables.
- File names.
- DCLGEN table definitions.
- Parameters.
Modify the code from Task#1 so it follows new standards.
![]() 3. Always document your program.
- Add all comments you consider necessary to the program from Task#2.
- Compare added comment types with the ones presented in the solution and, if necessary, update your code.
3. Always document your program.
- Add all comments you consider necessary to the program from Task#2.
- Compare added comment types with the ones presented in the solution and, if necessary, update your code.
![]() 4. Keep your changes in the code.
- Include a change-log in your program.
- Modify the program so now its output is not routed to SYSOUT but saved in the file.
- Indicate all in-line modification with appropriate markers.
4. Keep your changes in the code.
- Include a change-log in your program.
- Modify the program so now its output is not routed to SYSOUT but saved in the file.
- Indicate all in-line modification with appropriate markers.
![]() 5. Keep the code neat.
- Issue "C " " " " 8 72 ALL" command ten times.
- Compare how the code readability has changed.
- List the most important rules for structuring the code indents, groupings etc.
- Modify the code from the Task#4 accordingly.
5. Keep the code neat.
- Issue "C " " " " 8 72 ALL" command ten times.
- Compare how the code readability has changed.
- List the most important rules for structuring the code indents, groupings etc.
- Modify the code from the Task#4 accordingly.
![]() 6. Avoid unnecessary keywords.
- Remove unnecessary keywords from your program.
6. Avoid unnecessary keywords.
- Remove unnecessary keywords from your program.
![]() 7. Pay attention to the environment in which the program will run.
- Modify your program and the job which executes it so now sorting is done by standalone DFSORT in the preceding step.
7. Pay attention to the environment in which the program will run.
- Modify your program and the job which executes it so now sorting is done by standalone DFSORT in the preceding step.
![]() 8. KISS.
Answer the following questions:
- Is it better to use complex algorithms to save processor power or spread the code across more instructions but keep it more easily readable?
- Is it better to reuse some variables such as subscripts or computational items or to define a separate variable for each instruction?
- Should you always optimize your code for performance?
- Is it better to outsource some of the program functionality to a sub-program if you suspect this functionality could be needed by other programs?
- Should you ensure your programs handles all possible errors?
- Is it better to reuse and customize your older code for a new program or rewrite it from scratch?
8. KISS.
Answer the following questions:
- Is it better to use complex algorithms to save processor power or spread the code across more instructions but keep it more easily readable?
- Is it better to reuse some variables such as subscripts or computational items or to define a separate variable for each instruction?
- Should you always optimize your code for performance?
- Is it better to outsource some of the program functionality to a sub-program if you suspect this functionality could be needed by other programs?
- Should you ensure your programs handles all possible errors?
- Is it better to reuse and customize your older code for a new program or rewrite it from scratch?
![]() 9. Don't use 66 and 77 items.
- Write a program that demonstrates the difference between 66 and the REDEFINE clause.
- Why you should avoid 66 and 77 items?
9. Don't use 66 and 77 items.
- Write a program that demonstrates the difference between 66 and the REDEFINE clause.
- Why you should avoid 66 and 77 items?
![]() 10. Test all execution paths for your programs.
Test the program from Task#7 in following cases:
- The input data does not exist.
- The input data set is empty.
- The output data set already exists.
- The birth date or death date is missing.
Ensure you handle all those conditions either via JCL or in the program.
Consider if you should also test the program for the following conditions:
- The input data set is locked by another job.
- The input data set is not sorted.
- The birth date or death date is in incorrect format.
- The death date is earlier than the birth date.
- The birth date is older than 1600-01-01.
- The personal number is missing.
- The is an error during age calculation.
- There is an I/O error during record read or write.
10. Test all execution paths for your programs.
Test the program from Task#7 in following cases:
- The input data does not exist.
- The input data set is empty.
- The output data set already exists.
- The birth date or death date is missing.
Ensure you handle all those conditions either via JCL or in the program.
Consider if you should also test the program for the following conditions:
- The input data set is locked by another job.
- The input data set is not sorted.
- The birth date or death date is in incorrect format.
- The death date is earlier than the birth date.
- The birth date is older than 1600-01-01.
- The personal number is missing.
- The is an error during age calculation.
- There is an I/O error during record read or write.
![]() 11. Other good practices.
- Research and describe other recommended practices and habits for software development in COBOL.
11. Other good practices.
- Research and describe other recommended practices and habits for software development in COBOL.
Solution 1
Each time you write any program or function from the beginning you should always start with the design phase. This is where all the program functionality and logic should be clearly defined on the basis of the requirement you got from the person/team ordering the program. There two main approaches here. The first is to write the program in a simplified form using pseudocode. The second is to visualize program logic with a diagram. I prefer diagrams but both approaches are equally good. The important thing here is to go through this phase, to design the program before you'll actually code it. Ok, but why we need the design phase? The short answer is to save time. Contrary to intuition designing your program on paper can hugely reduce the amount of time you spend coding it and the more complex the program the more time you'll save this way. You save time because of: - Better design. In the design phase, you always consider the entire picture, every function that your program needs to provide, which allows you to easily find the most optimal solution for a given functionality. This, in turn, will save you a lot of time on re-working your code after noticing that the thing you've been writing for X hours, won't really fit in the solution you need to provide. - Error reduction. That's the biggest advantage of the design phase. Thinking through program logic you can detect various errors before they appear in code and solve them on paper. The cost of error here is the lowest. The further the error manifests itself the more expensive it becomes to fix it. In some case, you'll even need to redesign the entire program because of some unfortunate flaw in its logic. Having in mind your sense of aesthetics I won't include here my messy diagrams but on the following website, you can find a few example of how such diagrams can look like. Of course, there are many types of diagrams with different look and processes for creating them, but at the beginning don't worry about it. The thing that truly matters is the time spent on thinking, on designing the program logic in the most optimal way. https://www.edrawsoft.com/flowchart-ns-pad.php
Solution 2
Naming standards are used to indicate some characteristics of a particular programming construct in its name. This makes both coding and program analysis easier. At least it should, there are cases in which this technique is overdone. ________________________________________ - Program names. Program names usually start with two letter application indicator. An application is a set of programs which together realize some bigger functionality. The simplest naming convention was already used in the previous assignments: MPabb: - MP – indicates programs written for Mainframe Playground - a – one or two digits marking the number of a particular assignment. - bb – two digits marking the task in the assignment. A more complex example. In real-world companies you'll often see something similar - AASETXXX: - AA – Application ID to which the program belongs. There can be also codes non-related to any application. For example for programs used by system administrators can have its own ID as well as programs shared by multiple applications. - S – One-letter subcomponent identifier. If the application is very large it's useful to additionally divide it into subcomponents, so its smaller functionalities. - E – Environment. If many test environments run on the same system and use the same software (Same DB2 subsystem for example) names for various application components must vary. A letter indicator is usually used in such cases. - T – Application type. Marks what type in terms of used subsystems/technology this program is. For example, CICS programs = C, DB2 programs = B, DB2 + CICS programs = D, IMS programs = I and so on. - XXX – Three letter program ID. In here we'll stick with MPabb pattern. ________________________________________ - Paragraph names. Paragraph names usually follow a numeric pattern depending on the procedure from which they're executed. For example:
0000-MAIN. PERFORM 1000-INIT. PERFORM 2000-DO-SOMETHING. PERFORM 3000-CLEANUP. STOP RUN. 1000-INIT. PERFORM 1100-READ-FILE. PERFORM 1200-DISPLAY-FILE. ... 1100-READ-FILE. PERFORM 1110-CHECK-SMTH. ...
In here, you can see that the first digit in the paragraph name is used to indicate procedures which are executed from the main program procedure. The second digit is used for procedures nested one level, third digit for the ones nested two levels and so on. Paragraphs which are not clearly connected to any specific paragraph (for example, are executed multiple times) are marked with a different prefix, for example, with "9" or "Z". You can also use a similar idea but use letters which allow a little bit more flexibility:
MAIN. PERFORM A-INIT. PERFORM B-DO-SOMETHING. PERFORM C-CLEANUP. STOP RUN. A-INIT. PERFORM AA-READ-FILE. PERFORM AB-DISPLAY-FILE. ... AA-READ-FILE. PERFORM AAA-CHECK-SMTH. ...
A disadvantage of such conventions is that inserting a new paragraph into the code becomes problematic. Even if the design of the program is done very well, there will be always situations in which you'll have to add a paragraph between two existing. With this convention you have to play a little bit with change command, for example, "C "2112-" "2113-" ALL". Still, the easier code analysis and readability is usually considered worth the effort. Also, knowing how annoying it can be you'll be more motivated to spend more time on the design phase of programming. We'll go here with the first version since it's more commonly used. ________________________________________ - Variable names. Here is where things can become complicated. You can divide variables depending on many characteristics... Where they are placed in the program: - W – variables in WORKING-STORAGE section. - L – variables in LINKAGE section. - F – variables in FILE section. - D – variables in DCLGEN. And so on... What's their type: - N – numeric. - E – numeric-edited. - B – binary. - P – packed-decimal. - D – display (zoned-decimal). - T – text. - R – pointer. - S – structure. And so on... What's their usage: - CS – constant. - CP – computational variable. - LC – loop counter. - FL – flag/indicator. - DB – DCLGEN definition. - DT – date. - TM – time. - TS – timestamp. - TB – table. - TS – table subscript. - TI – table index. - PG – program name (used in CALL statement). - ME – error message. - MI – information message. - TP – temporary usage variable. - IN – input data. - OU – output data. - And so on... Notice that some variables can be considered many types in the above convention. For example, there can be an input data which is stored in a table and additionally is a timestamp and DCLGEN. That's a common problem with such convention. Its also a good example of how overdoing this technique makes coding and code analysis harder, not easier. There also conventions that mix up the above categorizations or use all of them at once. There are also shops which don't use such standard at all. In this assignment, we'll use a join of the first two categories. - Placement – In what part/section of the program variable is defined. - Type – Indicating variable type in the name immediately shows you what you can do with a given variable and what functions can be used on it. Additionally, it makes name selection easier, since you'll use the same name for the same data but in a different format. For example, it's not uncommon to store a date read from DB2 in many copies. In its original DCLGEN variable, in a copy on which you can do calculations, and in a variable used to writing it to a file. Using this convention, you can use the same name, just with different prefixes. For example: DT-BIRTH-DATE - DCLGEN text variable. WZ-BIRTH-DATE - Zoned decimal variable in the working-storage section. FT-BIRTH-DATE - Text variable used for writing data to a file in the desired format. We'll use "PT-name" convention as shown above, where: P – place where the variable is defined: - W – WORKING-STORAGE SECTION. - F – FD definition in the FILE SECTION. - S – SD definition in the FILE SECTION. - L – LINKAGE SECTION. - D – DCLGEN. T – variable type: - Z – zoned-decimal (DISPLAY). - E – numeric-edited - B – binary. - I – native binary (COMP-5). - F – floating point (COMP-1). - L – long floating point (COMP-2). - P – packed-decimal (COMP-3). - M – external-floating-point - T – alphanumeric - X – alphanumeric-edited - N – national - C – DBCS (DISPLAY-1). - S – structure grouping item. - V – varchar item, so a structure consisting of text and number variables. I probably missed something but you can see how it goes. ________________________________________ - Structures. The best option for choosing names for structure variables is to use a prefix. For example, "EMP" for a structure representing an employee record. Using this rule and the previously chosen naming convention will result in:
01 EMP-WS. 05 EMP-WS-NAME. 10 EMP-WT-FNAME PIC X(15). 10 EMP-WT-LNAME PIC X(15). 05 EMP-WZ-AGE PIC 9(3). 05 EMP-WB-SALARY PIC 9(9) COMP. ... 01 EMP-WB-COUNT PIC S9(9) COMP.
Additionally, variables which are used for table-related activities. For example, subscripts can also have the same prefix which makes their purpose clearer. So now our general naming convention is: "[str-]PT-name". Often 01 structure item is indicated with '-REC' as we did in some previous assignments. In here, we indicate grouping items in 'type' letter so we can skip this convention here. ________________________________________ - Tables. Indicating if a particular item is a table or not is always problematic because it conflicts with each of the three variable categorizations presented earlier. A table can be both in working storage and in DCLGEN. It can store COMP-3 items or text data. It can serve as a set of counters or input variables. Therefore the most reasonable way is to add some prefix/suffix to the table items or to avoid this convention at all. For example: - EMP-WS-NAME-TB. - EMP-TB-WS-NAME. In here we'll won't use table indicator. Tables are not that common and usually very important to program functionality so remembering which names define a table shouldn't be a problem. ________________________________________ - File names. Each file definition has a few different variables which can be very easily confused. For example, file name near at SELECT keyword can be easily mistaken with DD name in the ASSIGN clause. Therefore setting a naming standard for file-related variables is a very good idea. The most common solution and the one we'll use here is adding a suffix to the file-related variables: Filename: nnn-FILE DD name: nnnFILE EOF indicator: nnn-EOF File status: nnn-FS File record definition: nnn-"PT-name" Sort file variables: Adding "S" letter at the end of file prefix, for example: nnnS-FILE. Similarly to structures, variables created for file management like record counters, cursors, etc. should use the same prefix as the file. File related variables: nnn-PT-name ________________________________________ - DCLGEN table definitions. We've already covered that with 'P' indicator. DCLGENs are structures so accordingly to our naming convention they should have a prefix. It's best to use a table name for the prefix. In here, we'll also use 4-letter prefixes instead of 3-letter ones as in case of other structures, which additionally enable us to quickly recognize DCLGEN variables in the program. We're using the EMPLOYEE database with "AATTXXXX" object naming standard. For example EMTBEMPL. The last 4 letters are table ID, so this is what we should use as the prefix for DCLGEN structures:
************************************************* 01 EMPL-DS. ********************************************* 10 EMPL-DB-EMP-NO PIC S9(9) USAGE COMP. ********************************************* 10 EMPL-DT-BIRTH-DATE PIC X(10). ********************************************* 10 EMPL-DS-FIRST-NAME. 49 EMPL-DB-FIRST-NAME PIC S9(4) USAGE COMP. 49 EMPL-DT-FIRST-NAME PIC X(14). *********************************************
'-LEN' and '-TEXT' suffixes for the FIRST-NAME variable were removed since now we can recognize which variable is which with 'Type' marker. The names in the DCLGEN should always match the names of columns in DB2 with the exception that DB2 columns use '_' instead of '-' as a separator. But that's also a naming convention which makes differentiating between column names and host variables easier. Another benefit of this naming convention in DCLGENs is that now we don't have to worry if the program works on two tables with the same column names. We'd had to use "OF" keyword to differentiate between them, now prefix does that. ________________________________________ - Parameters. We've also covered that in our current naming convention, all parameters are defined in the LINKAGE section, therefore, we would be able to recognize them via "Placement" indicator in the parameter name. ________________________________________ COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1601. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT PPL-FILE ASSIGN TO PPLFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS PPL-WT-FS. SELECT PPLS-FILE ASSIGN TO PPLSFILE. DATA DIVISION. FILE SECTION. FD PPL-FILE RECORDING MODE F. 01 PPL-FS. 05 PPL-FZ-PERS-NUMBER PIC 9(11). 05 PPL-FT-FIRST-NAME PIC X(15). 05 PPL-FT-LAST-NAME PIC X(15). 05 PPL-FT-GENDER PIC X. 05 PPL-FS-BIRTH-DATE. 10 PPL-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-BDAY PIC 9(2). 05 PPL-FS-DEATH-DATE. 10 PPL-FZ-DYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-DMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-DDAY PIC 9(2). 05 FILLER PIC X(18). SD PPLS-FILE. 01 PPLS-FS. 05 PPLS-FZ-PERS-NUMBER PIC 9(11). 05 PPLS-FT-FIRST-NAME PIC X(15). 05 PPLS-FT-LAST-NAME PIC X(15). 05 PPLS-FT-GENDER PIC X. 05 PPLS-FS-BIRTH-DATE. 10 PPLS-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 PPLS-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 PPLS-FZ-BDAY PIC 9(2). 05 PPLS-FS-DEATH-DATE. 10 PPLS-FZ-DYEAR PIC 9(4). 10 FILLER PIC X. 10 PPLS-FZ-DMONTH PIC 9(2). 10 FILLER PIC X. 10 PPLS-FZ-DDAY PIC 9(2). 05 FILLER PIC X(18). WORKING-STORAGE SECTION. 77 PPLS-WZ-EOF PIC 9 VALUE 0. 77 PPL-WT-FS PIC X(2). 77 PPL-WZ-AGE-YEARS PIC 9(3)V9(2). 77 PPL-WE-AGE-YEARS PIC ZZ9.9(2). 77 PPL-WZ-AGE-DAYS PIC 9(5). 77 PPL-WE-AGE-DAYS PIC Z(4)9. 77 WB-INT-DATE-START PIC 9(9) USAGE COMP. 77 WB-INT-DATE-END PIC 9(9) USAGE COMP. 77 WZ-TEMP-DATE PIC 9(8). PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON PPL-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'PPLFILE' STATUS: " PPL-WT-FS. DISPLAY "PROGRAM TERMINATES.". IF PPL-WT-FS NOT = "42" CLOSE PPL-FILE. MOVE 12 TO RETURN-CODE. STOP RUN. END DECLARATIVES. 0000-MAIN. PERFORM 1000-INIT. PERFORM 2000-DISPLAY-HEADER. PERFORM 3000-SORT-AND-DISPLAY. PERFORM Z100-CLEANUP. 1000-INIT. MOVE "SORTMSG" TO SORT-MESSAGE. 2000-DISPLAY-HEADER. DISPLAY "-----------|---------------|---------------|" "-|----------|----------|------|-----". DISPLAY "PERS NUMBER|FIRST NAME |LAST NAME |" "G|BIRTH DATE|DEATH DATE|YEARS |DAYS ". DISPLAY "-----------|---------------|---------------|" "-|----------|----------|------|-----". 3000-SORT-AND-DISPLAY. SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL" MOVE SORT-RETURN TO RETURN-CODE PERFORM Z100-CLEANUP END-IF. 3100-DISPLAY-FILE. RETURN PPLS-FILE AT END MOVE 1 TO PPLS-WZ-EOF. PERFORM UNTIL PPLS-WZ-EOF = 1 PERFORM 3110-CALCULATE-AGE PERFORM 3120-DISPLAY-RECORD RETURN PPLS-FILE AT END MOVE 1 TO PPLS-WZ-EOF END-RETURN END-PERFORM. 3110-CALCULATE-AGE. PERFORM 3111-CONVERT-DATES-TO-INT. COMPUTE PPL-WZ-AGE-DAYS = WB-INT-DATE-END - WB-INT-DATE-START. COMPUTE PPL-WZ-AGE-YEARS = PPL-WZ-AGE-DAYS / 365.25. MOVE PPL-WZ-AGE-DAYS TO PPL-WE-AGE-DAYS. MOVE PPL-WZ-AGE-YEARS TO PPL-WE-AGE-YEARS. 3111-CONVERT-DATES-TO-INT. COMPUTE WZ-TEMP-DATE = PPLS-FZ-BYEAR * 10000 + PPLS-FZ-BMONTH * 100 + PPLS-FZ-BDAY. COMPUTE WB-INT-DATE-START = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF. COMPUTE WB-INT-DATE-END = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). 3120-DISPLAY-RECORD. DISPLAY PPLS-FZ-PERS-NUMBER " " PPLS-FT-FIRST-NAME " " PPLS-FT-LAST-NAME " " PPLS-FT-GENDER " " PPLS-FS-BIRTH-DATE " " PPLS-FS-DEATH-DATE " " PPL-WE-AGE-YEARS " " PPL-WE-AGE-DAYS. Z100-CLEANUP. STOP RUN.
Output:
-----------|---------------|---------------|-|----------|----------|------|----- PERS NUMBER|FIRST NAME |LAST NAME |G|BIRTH DATE|DEATH DATE|YEARS |DAYS -----------|---------------|---------------|-|----------|----------|------|----- 98472193874 Padavan Srawan M 1900-03-13 2001-05-19 101.18 36957 47913472000 Michiel Ocean M 1913-11-07 2000-11-30 87.06 31800 13820019922 Anna Amarath F 1935-04-11 1993-04-16 58.01 21190 43009138882 Jessica Assica F 1948-06-21 1993-07-27 45.09 16472 73699900173 Peter Parker M 1971-12-03 9999-01-01 46.83 17107 92273919384 Johan Maveric M 1978-05-05 9999-01-01 40.41 14762 77388210300 Harry Vodka M 1988-07-09 2017-01-25 28.54 10427 38172938219 Sarah Kowalski F 1991-03-31 9999-01-01 27.51 10049 84736662321 Scarlet Margaret F 1998-03-31 9999-01-01 20.51 7492 98001127293 Barok Fema-Smith M 2001-02-23 9999-01-01 17.60 6432
Comments: - As you can see there are all kinds of ways in which you could design naming convention for COBOL programs developed by your team. The main thing to remember is to keep the right balance between the number of details included in the naming standard and its simplicity. Making it too complex makes coding harder and introduces another area in which programmers can make errors, which is never a good thing. - In the above case, naming convention follows the simplest standard. It only indicates where the variable is placed in the program and what type it is. At first glance, it may seem like not much of an improvement, but as you'll see in your own coding and code analysis practice, such naming conventions are very nice. - You can see here another good coding practice, so having "INIT" and "CLEANUP" functions which perform all kinds of activity that needs to be done before and after the main program logic, whether it is executed normally or abnormally. CLEANUP name starts with "Z" since according to our standard "Z" marks routines which are executed from various paragraphs in a program and "CLEANUP" routine should be always a common ending point of all execution paths, both normal and abnormal.
Solution 3
This rule states you should always document your program by including all kinds of comments inside the code and also by maintaining program documentation outside the z/OS. In-code documentation should include: - Creator name – so the name of the person who initially wrote the routine. IDs of programmers who modified the code should be included in the changelog. - Creation date – when the first version of the program was written. An alternative to that is to specify the creation date and creators as the first entry in the change log. - Compilation date (it's added automatically so don't worry about it). - General description of program functionality. - Security considerations – so if the program uses company/customer data and how it is/should be protected. - Description of every called sub-program. - Comments for every variable describing its usage (unless its content and usage is obvious). - Comments for every paragraph describing its function. - Comments for every EXEC-SQL and EXEC CICS clause. - Comments for all parts of the code which may be unclear/tricky to figure out to someone who'll analyze the code for the first time. - Description of program input whether it's DB2 table, file, data passed by CICS or anything else. - Description of program output whether it's DB2, file, CICS etc. - On what subsystems/processes the program depends. So if it uses TCP/IP directly, DB2, CICS, MVS commands, or any other system components. And also: - Changelog. - Modified/added/removed lines. Which we'll cover in the next Task. External documentation should include: - Predecessors – program names on which this program depends (which may, for example, create a file on which our program depends). - Successors – programs which depend on the successful execution of this program. (For predecessors and successors, include only first level relations. This way you'll save time and avoid confusion during dependency analysis). - Dependency schema - except the direct dependencies you should have in the documentation a schema with all the relation inside a particular application and also all the connections to different applications. The often overlooked part of such schemas are inputs and outputs for each program, so also remember about that. - Error handling instructions. Instructions regarding error handling are subject to frequent change and depending on the environment and other circumstances they may vary greatly. Therefore, keeping them inside the code is not an effective solution. They can be part of operator instruction in the JCL (if the program runs in batch) or external documentation. In addition: - It's a good habit to code comments in mixed cases, this will make them stand out from program instructions. - When making comments, always put them above the instruction you're commenting. Additionally, you can use a separation line like shown in the code below, to make the code more readable. Updated CODE:
*----------------------------------------------------------------- * ### Program description ### * * Program reads employees personal data and calculates their age. *----------------------------------------------------------------- * ### Inputs ### * * - 'JSADEK.COBOL.PEOPLE(0)' data set. * - Sort WRK file for sorting the above data set. *----------------------------------------------------------------- * ### Outputs ### * * - SYSOUT - Program only produces listing via DISPLAY instr. * - SORTMSG - DD to which DFSORT messages are routed. *----------------------------------------------------------------- * ### Called sub-programs ### * * None *----------------------------------------------------------------- * ### System-related dependencies ### * * Batch program - JES2 & Scheduler *----------------------------------------------------------------- * ### Security considerations ### * * Program read and produces company's confidential data. * It cannot leave internal infrastructure without an approval. *----------------------------------------------------------------- IDENTIFICATION DIVISION. PROGRAM-ID. MP1601. AUTHOR. JSADEK (myemail@gmail.com) DATE-WRITTEN. 2018.10.04. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. *----------------------------------------------------------------- * PPL-FILE contains employees data from which the age is * calculated *----------------------------------------------------------------- SELECT PPL-FILE ASSIGN TO PPLFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS PPL-WT-FS. *----------------------------------------------------------------- * Sort file for sorting PPL-FILE *----------------------------------------------------------------- SELECT PPLS-FILE ASSIGN TO PPLSFILE. DATA DIVISION. FILE SECTION. FD PPL-FILE RECORDING MODE F. 01 PPL-FS. *----------------------------------------------------------------- * Employee personal number (Polish format). *----------------------------------------------------------------- 05 PPL-FZ-PERS-NUMBER PIC 9(11). 05 PPL-FT-FIRST-NAME PIC X(15). 05 PPL-FT-LAST-NAME PIC X(15). 05 PPL-FT-GENDER PIC X. 05 PPL-FS-BIRTH-DATE. 10 PPL-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-BDAY PIC 9(2). *----------------------------------------------------------------- * '9999-01-01' value indicates that the person is still alive. *----------------------------------------------------------------- 05 PPL-FS-DEATH-DATE. 10 PPL-FZ-DYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-DMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-DDAY PIC 9(2). *----------------------------------------------------------------- * The last 18 bytes in file are reseved for future use (LRECL=80) *----------------------------------------------------------------- 05 FILLER PIC X(18). SD PPLS-FILE. 01 PPLS-FS. 05 PPLS-FZ-PERS-NUMBER PIC 9(11). 05 PPLS-FT-FIRST-NAME PIC X(15). 05 PPLS-FT-LAST-NAME PIC X(15). 05 PPLS-FT-GENDER PIC X. 05 PPLS-FS-BIRTH-DATE. 10 PPLS-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 PPLS-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 PPLS-FZ-BDAY PIC 9(2). 05 PPLS-FS-DEATH-DATE. 10 PPLS-FZ-DYEAR PIC 9(4). 10 FILLER PIC X. 10 PPLS-FZ-DMONTH PIC 9(2). 10 FILLER PIC X. 10 PPLS-FZ-DDAY PIC 9(2). 05 FILLER PIC X(18). WORKING-STORAGE SECTION. *----------------------------------------------------------------- * End of file indicator for PPLS sort file. *----------------------------------------------------------------- 77 PPLS-WZ-EOF PIC 9 VALUE 0. *----------------------------------------------------------------- * File status variable for PPL input file. *----------------------------------------------------------------- 77 PPL-WT-FS PIC X(2). *----------------------------------------------------------------- * Variable for storing employee age in years. *----------------------------------------------------------------- 77 PPL-WZ-AGE-YEARS PIC 9(3)V9(2). *----------------------------------------------------------------- * DISPLAY version of PPL-WZ-AGE-YEARS. *----------------------------------------------------------------- 77 PPL-WE-AGE-YEARS PIC ZZ9.9(2). *----------------------------------------------------------------- * Variable for storing employee age in days. *----------------------------------------------------------------- 77 PPL-WZ-AGE-DAYS PIC 9(5). *----------------------------------------------------------------- * DISPLAY version of PPL-WZ-AGE-DAYS. *----------------------------------------------------------------- 77 PPL-WE-AGE-DAYS PIC Z(4)9. *----------------------------------------------------------------- * Two variables storing BIRTH-DATE and either DEATH-DATE or * current date in INT format. Used in calculation only. *----------------------------------------------------------------- 77 WB-INT-DATE-START PIC 9(9) USAGE COMP. 77 WB-INT-DATE-END PIC 9(9) USAGE COMP. *----------------------------------------------------------------- * Temporary variable used during conversion from 'YYYY-MM-DD' * format to INT date format. *----------------------------------------------------------------- 77 WZ-TEMP-DATE PIC 9(8). PROCEDURE DIVISION. DECLARATIVES. *----------------------------------------------------------------- * File handling rountine for PPL-FILE. * In this execution path Z100-CLEANUP is not executed so be sure * to also add here cleanup istructions if needed. *----------------------------------------------------------------- FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON PPL-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'PPLFILE' STATUS: " PPL-WT-FS. DISPLAY "PROGRAM TERMINATES.". *----------------------------------------------------------------- * Loop prevention. '42' means that program attemted to close the * file which is already closed. *----------------------------------------------------------------- IF PPL-WT-FS NOT = "42" CLOSE PPL-FILE. MOVE 12 TO RETURN-CODE. STOP RUN. END DECLARATIVES. *----------------------------------------------------------------- * 0000-MAIN * Main program routine. *----------------------------------------------------------------- 0000-MAIN. PERFORM 1000-INIT. PERFORM 2000-DISPLAY-HEADER. PERFORM 3000-SORT-AND-DISPLAY. PERFORM Z100-CLEANUP. *----------------------------------------------------------------- * 1000-INIT * Initialization routine. *----------------------------------------------------------------- 1000-INIT. MOVE "SORTMSG" TO SORT-MESSAGE. *----------------------------------------------------------------- * 2000-DISPLAY-HEADER * Displays the header for easier column identification. *----------------------------------------------------------------- 2000-DISPLAY-HEADER. DISPLAY "-----------|---------------|---------------|" "-|----------|----------|------|-----". DISPLAY "PERS NUMBER|FIRST NAME |LAST NAME |" "G|BIRTH DATE|DEATH DATE|YEARS |DAYS ". DISPLAY "-----------|---------------|---------------|" "-|----------|----------|------|-----". *----------------------------------------------------------------- * 3000-SORT-AND-DISPLAY * Displays the header for easier column identification. *----------------------------------------------------------------- 3000-SORT-AND-DISPLAY. SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL" MOVE SORT-RETURN TO RETURN-CODE PERFORM Z100-CLEANUP END-IF. *----------------------------------------------------------------- * 3100-DISPLAY-FILE * Sort output procedure. Gets sorted records one by one * and passes them for futher processing. *----------------------------------------------------------------- 3100-DISPLAY-FILE. RETURN PPLS-FILE AT END MOVE 1 TO PPLS-WZ-EOF. PERFORM UNTIL PPLS-WZ-EOF = 1 PERFORM 3110-CALCULATE-AGE PERFORM 3120-DISPLAY-RECORD RETURN PPLS-FILE AT END MOVE 1 TO PPLS-WZ-EOF END-RETURN END-PERFORM. *----------------------------------------------------------------- * 3110-CALCULATE-AGE * Computes employee age in years and days on the basis of the * BIRTH-DATE and DEATH-DATE variables. *----------------------------------------------------------------- 3110-CALCULATE-AGE. PERFORM 3111-CONVERT-DATES-TO-INT. *----------------------------------------------------------------- * Calculates number of days between from BIRTH-DATE * and DEATH-DATE or CURRENT-TIME *----------------------------------------------------------------- COMPUTE PPL-WZ-AGE-DAYS = WB-INT-DATE-END - WB-INT-DATE-START. *----------------------------------------------------------------- * Calculating age in years on the basis of age value in days. *----------------------------------------------------------------- COMPUTE PPL-WZ-AGE-YEARS = PPL-WZ-AGE-DAYS / 365.25. *----------------------------------------------------------------- * Moves numbers in ZD format to EDITED variables. *----------------------------------------------------------------- MOVE PPL-WZ-AGE-DAYS TO PPL-WE-AGE-DAYS. MOVE PPL-WZ-AGE-YEARS TO PPL-WE-AGE-YEARS. *----------------------------------------------------------------- * 3111-CONVERT-DATES-TO-INT * Converts BIRTH-DATE and DEATH-DATE/CURRENT-DATE from * 'YYYY-MM-DD' to INT format. *----------------------------------------------------------------- 3111-CONVERT-DATES-TO-INT. *----------------------------------------------------------------- * Converts birth date to INT format (YYYYMMDD). *----------------------------------------------------------------- COMPUTE WZ-TEMP-DATE = PPLS-FZ-BYEAR * 10000 + PPLS-FZ-BMONTH * 100 + PPLS-FZ-BDAY. *----------------------------------------------------------------- * Converts INT (YYYYMMDD) format into COBOL INT date * representation. *----------------------------------------------------------------- COMPUTE WB-INT-DATE-START = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). *----------------------------------------------------------------- * IF checks if person is still alive and on this basis decides * if DEATH-DATE or CURRENT-DATE is used for age calculation. *----------------------------------------------------------------- IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF. *----------------------------------------------------------------- * Converts DEATH-DATE / CURRENT-DATE into COBOL INT date * representation. *----------------------------------------------------------------- COMPUTE WB-INT-DATE-END = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). *----------------------------------------------------------------- * 3120-DISPLAY-RECORD * Display a single employee record with calculated age. *----------------------------------------------------------------- 3120-DISPLAY-RECORD. DISPLAY PPLS-FZ-PERS-NUMBER " " PPLS-FT-FIRST-NAME " " PPLS-FT-LAST-NAME " " PPLS-FT-GENDER " " PPLS-FS-BIRTH-DATE " " PPLS-FS-DEATH-DATE " " PPL-WE-AGE-YEARS " " PPL-WE-AGE-DAYS. *----------------------------------------------------------------- * Z100-CLEANUP * Standard cleaup routine, use it to define actions which needs * to be done before program ends (either normally or abnormally). *----------------------------------------------------------------- Z100-CLEANUP. STOP RUN.
Comments: - Be sure to specify all input/output streams for the program. In this example, we use non-standard DD name for DFSORT messages, so we should indicate that in Output Description. Similarly we should state that WRK file for sort is needed. It could be deducted from the code but the entire point of comments is to make the code analysis easier. In some cases, even not-needed. - Notice that not all variables are described. Many of them like FIRST-NAME or BIRTH-DATE are so obvious that additionally describing them would be a waste of time. Still notice PERS-NUMBER. It's usage is clear as well, but the personal number matches Polish standards. Details like that should be always included in the code.
Solution 4
COBOL code:
*----------------------------------------------------------------- * ### Program description ### * * Program reads employees personal data and calculates their age. *----------------------------------------------------------------- * ### Inputs ### * * - 'JSADEK.COBOL.PEOPLE(0)' data set. * - Sort WRK file for sorting the above data set. *----------------------------------------------------------------- * ### Outputs ### * * - REPFILE - Sorted input with added age calculation. * - SORTMSG - DD to which DFSORT messages are routed. *----------------------------------------------------------------- * ### Called sub-programs ### * * None *----------------------------------------------------------------- * ### System-related dependencies ### * * Batch program - JES2 & Scheduler *----------------------------------------------------------------- * ### Security considerations ### * * Program read and produces company's confidential data. * It cannot leave internal infrastructure without an approval. *----------------------------------------------------------------- * ### Change Log ### *----------------------------------------------------------------- *CHNG| PROG | DATE | TICKET | SHORT DESCRIPTION * ID | ID |YYYYMMDD| NUMBER | *----------------------------------------------------------------- *0000|JSADEK |20181004| N/A | First version of program created *----------------------------------------------------------------- *0001|JSADEK |20181005| N/A | Output destination changed from * | | | | SYSOUT to data set. *----------------------------------------------------------------- * | | | | COPY RECORD *----------------------------------------------------------------- IDENTIFICATION DIVISION. PROGRAM-ID. MP1604. AUTHOR. JSADEK (myemail@gmail.com) DATE-WRITTEN. 2018.10.04. ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. *----------------------------------------------------------------- * PPL-FILE contains employees data from which the age is * calculated *----------------------------------------------------------------- SELECT PPL-FILE ASSIGN TO PPLFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS PPL-WT-FS. #0001N*----------------------------------------------------------------- # * REP-FILE output - stores sorted input with added employee age # *----------------------------------------------------------------- # SELECT REP-FILE # ASSIGN TO REPFILE # ORGANIZATION IS SEQUENTIAL #0001N FILE STATUS IS REP-WT-FS. *----------------------------------------------------------------- * Sort file for sorting PPL-FILE *----------------------------------------------------------------- SELECT PPLS-FILE ASSIGN TO PPLSFILE. DATA DIVISION. FILE SECTION. FD PPL-FILE RECORDING MODE F. 01 PPL-FS. *----------------------------------------------------------------- * Employee personal number (Polish format). *----------------------------------------------------------------- 05 PPL-FZ-PERS-NUMBER PIC 9(11). 05 PPL-FT-FIRST-NAME PIC X(15). 05 PPL-FT-LAST-NAME PIC X(15). 05 PPL-FT-GENDER PIC X. 05 PPL-FS-BIRTH-DATE. 10 PPL-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-BDAY PIC 9(2). *----------------------------------------------------------------- * '9999-01-01' value indicates that the person is still alive. *----------------------------------------------------------------- 05 PPL-FS-DEATH-DATE. 10 PPL-FZ-DYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-DMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-DDAY PIC 9(2). *----------------------------------------------------------------- * The last 18 bytes in file are reseved for future use (LRECL=80) *----------------------------------------------------------------- 05 FILLER PIC X(18). #0001N FD REP-FILE # RECORDING MODE F. # 01 REP-FS. # 05 REP-FZ-PERS-NUMBER PIC 9(11). # 05 REP-FT-FIRST-NAME PIC X(15). # 05 REP-FT-LAST-NAME PIC X(15). # 05 REP-FT-GENDER PIC X. # 05 REP-FS-BIRTH-DATE. # 10 REP-FZ-BYEAR PIC 9(4). # 10 FILLER PIC X. # 10 REP-FZ-BMONTH PIC 9(2). # 10 FILLER PIC X. # 10 REP-FZ-BDAY PIC 9(2). # 05 REP-FS-DEATH-DATE. # 10 REP-FZ-DYEAR PIC 9(4). # 10 FILLER PIC X. # 10 REP-FZ-DMONTH PIC 9(2). # 10 FILLER PIC X. # 10 REP-FZ-DDAY PIC 9(2). # 05 REP-FE-AGE-IN-YEARS PIC ZZ9.9(2). # 05 REP-FE-AGE-IN-DAYS PIC Z(4)9. #0001N 05 FILLER PIC X(7). SD PPLS-FILE. 01 PPLS-FS. 05 PPLS-FZ-PERS-NUMBER PIC 9(11). 05 PPLS-FT-FIRST-NAME PIC X(15). 05 PPLS-FT-LAST-NAME PIC X(15). 05 PPLS-FT-GENDER PIC X. 05 PPLS-FS-BIRTH-DATE. 10 PPLS-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 PPLS-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 PPLS-FZ-BDAY PIC 9(2). 05 PPLS-FS-DEATH-DATE. 10 PPLS-FZ-DYEAR PIC 9(4). 10 FILLER PIC X. 10 PPLS-FZ-DMONTH PIC 9(2). 10 FILLER PIC X. 10 PPLS-FZ-DDAY PIC 9(2). 05 FILLER PIC X(18). WORKING-STORAGE SECTION. *----------------------------------------------------------------- * End of file indicator for PPLS sort file. *----------------------------------------------------------------- 77 PPLS-WZ-EOF PIC 9 VALUE 0. *----------------------------------------------------------------- * File status variable for PPL input file. *----------------------------------------------------------------- 77 PPL-WT-FS PIC X(2). #0001N*----------------------------------------------------------------- # * File status variable for REP output file. # *----------------------------------------------------------------- #0001N 77 REP-WT-FS PIC X(2). *----------------------------------------------------------------- * Variable for storing employee age in years. *----------------------------------------------------------------- 77 PPL-WZ-AGE-YEARS PIC 9(3)V9(2). $0001D*----------------------------------------------------------------- $ * DISPLAY version of PPL-WZ-AGE-YEARS. $ *----------------------------------------------------------------- $0001D*77 PPL-WE-AGE-YEARS PIC ZZ9.9(2). *----------------------------------------------------------------- * Variable for storing employee age in days. *----------------------------------------------------------------- 77 PPL-WZ-AGE-DAYS PIC 9(5). $0001D*----------------------------------------------------------------- $ * DISPLAY version of PPL-WZ-AGE-DAYS. $ *----------------------------------------------------------------- $0001D*77 PPL-WE-AGE-DAYS PIC Z(4)9. *----------------------------------------------------------------- * Two variables storing BIRTH-DATE and either DEATH-DATE or * current date in INT format. Used in calculation only. *----------------------------------------------------------------- 77 WB-INT-DATE-START PIC 9(9) USAGE COMP. 77 WB-INT-DATE-END PIC 9(9) USAGE COMP. *----------------------------------------------------------------- * Temporary variable used during conversion from 'YYYY-MM-DD' * format to INT date format. *----------------------------------------------------------------- 77 WZ-TEMP-DATE PIC 9(8). PROCEDURE DIVISION. DECLARATIVES. *----------------------------------------------------------------- * File handling rountine for PPL-FILE. * In this execution path Z100-CLEANUP is not executed so be sure * to also add here cleanup istructions if needed. *----------------------------------------------------------------- FILE-ERRORS SECTION. $0001U* USE AFTER ERROR PROCEDURE ON PPL-FILE. #0001N USE AFTER ERROR PROCEDURE ON PPL-FILE REP-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'PPLFILE' STATUS: " PPL-WT-FS. #0001N DISPLAY "'REPFILE' STATUS: " REP-WT-FS. DISPLAY "PROGRAM TERMINATES.". *----------------------------------------------------------------- * Loop prevention. '42' means that program attemted to close the * file which is already closed. *----------------------------------------------------------------- IF PPL-WT-FS NOT = "42" CLOSE PPL-FILE. #0001N IF REP-WT-FS NOT = "42" #0001N CLOSE REP-FILE. MOVE 12 TO RETURN-CODE. STOP RUN. END DECLARATIVES. *----------------------------------------------------------------- * 0000-MAIN * Main program routine. *----------------------------------------------------------------- 0000-MAIN. PERFORM 1000-INIT. $0001D* PERFORM 2000-DISPLAY-HEADER. PERFORM 3000-SORT-AND-DISPLAY. PERFORM Z100-CLEANUP. *----------------------------------------------------------------- * 1000-INIT * Initialization routine. *----------------------------------------------------------------- 1000-INIT. MOVE "SORTMSG" TO SORT-MESSAGE. #0001N OPEN OUTPUT REP-FILE. $0001D*----------------------------------------------------------------- $ * 2000-DISPLAY-HEADER $ * Displays the header for easier column identification. $ *----------------------------------------------------------------- $ *2000-DISPLAY-HEADER. $ * DISPLAY "-----------|---------------|---------------|" $ * "-|----------|----------|------|-----". $ * DISPLAY "PERS NUMBER|FIRST NAME |LAST NAME |" $ * "G|BIRTH DATE|DEATH DATE|YEARS |DAYS ". $ * DISPLAY "-----------|---------------|---------------|" $0001D* "-|----------|----------|------|-----". *----------------------------------------------------------------- * 3000-SORT-AND-DISPLAY * Displays the header for easier column identification. *----------------------------------------------------------------- 3000-SORT-AND-DISPLAY. SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL" MOVE SORT-RETURN TO RETURN-CODE PERFORM Z100-CLEANUP END-IF. *----------------------------------------------------------------- * 3100-DISPLAY-FILE * Sort output procedure. Gets sorted records one by one * and passes them for futher processing. *----------------------------------------------------------------- 3100-DISPLAY-FILE. RETURN PPLS-FILE AT END MOVE 1 TO PPLS-WZ-EOF. PERFORM UNTIL PPLS-WZ-EOF = 1 PERFORM 3110-CALCULATE-AGE PERFORM 3120-DISPLAY-RECORD RETURN PPLS-FILE AT END MOVE 1 TO PPLS-WZ-EOF END-RETURN END-PERFORM. *----------------------------------------------------------------- * 3110-CALCULATE-AGE * Computes employee age in years and days on the basis of the * BIRTH-DATE and DEATH-DATE variables. *----------------------------------------------------------------- 3110-CALCULATE-AGE. PERFORM 3111-CONVERT-DATES-TO-INT. *----------------------------------------------------------------- * Calculates number of days between from BIRTH-DATE * and DEATH-DATE or CURRENT-TIME *----------------------------------------------------------------- COMPUTE PPL-WZ-AGE-DAYS = WB-INT-DATE-END - WB-INT-DATE-START. *----------------------------------------------------------------- * Calculating age in years on the basis of age value in days. *----------------------------------------------------------------- COMPUTE PPL-WZ-AGE-YEARS = PPL-WZ-AGE-DAYS / 365.25. *----------------------------------------------------------------- * Initializes output record so it doesn't contain nulls. *----------------------------------------------------------------- #0001N MOVE SPACES TO REP-FS. *----------------------------------------------------------------- * Moves numbers in ZD format to EDITED variables. *----------------------------------------------------------------- $0001U* MOVE PPL-WZ-AGE-DAYS TO PPL-WE-AGE-DAYS. #0001N MOVE PPL-WZ-AGE-DAYS TO REP-FE-AGE-IN-DAYS. $0001U* MOVE PPL-WZ-AGE-YEARS TO PPL-WE-AGE-YEARS. #0001N MOVE PPL-WZ-AGE-YEARS TO REP-FE-AGE-IN-YEARS. *----------------------------------------------------------------- * 3111-CONVERT-DATES-TO-INT * Converts BIRTH-DATE and DEATH-DATE/CURRENT-DATE from * 'YYYY-MM-DD' to INT format. *----------------------------------------------------------------- 3111-CONVERT-DATES-TO-INT. *----------------------------------------------------------------- * Converts birth date to INT format (YYYYMMDD). *----------------------------------------------------------------- COMPUTE WZ-TEMP-DATE = PPLS-FZ-BYEAR * 10000 + PPLS-FZ-BMONTH * 100 + PPLS-FZ-BDAY. *----------------------------------------------------------------- * Converts INT (YYYYMMDD) format into COBOL INT date * representation. *----------------------------------------------------------------- COMPUTE WB-INT-DATE-START = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). *----------------------------------------------------------------- * IF checks if person is still alive and on this basis decides * if DEATH-DATE or CURRENT-DATE is used for age calculation. *----------------------------------------------------------------- IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF. *----------------------------------------------------------------- * Converts DEATH-DATE / CURRENT-DATE into COBOL INT date * representation. *----------------------------------------------------------------- COMPUTE WB-INT-DATE-END = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). *----------------------------------------------------------------- * 3120-DISPLAY-RECORD * Display a single employee record with calculated age. *----------------------------------------------------------------- 3120-DISPLAY-RECORD. $0001U* DISPLAY PPLS-FZ-PERS-NUMBER " " PPLS-FT-FIRST-NAME $ * " " PPLS-FT-LAST-NAME " " PPLS-FT-GENDER $ * " " PPLS-FS-BIRTH-DATE " " PPLS-FS-DEATH-DATE $0001U* " " PPL-WE-AGE-YEARS " " PPL-WE-AGE-DAYS. #0001N MOVE PPLS-FZ-PERS-NUMBER TO REP-FZ-PERS-NUMBER. # MOVE PPLS-FT-FIRST-NAME TO REP-FT-FIRST-NAME. # MOVE PPLS-FT-LAST-NAME TO REP-FT-LAST-NAME. # MOVE PPLS-FT-GENDER TO REP-FT-GENDER. # MOVE PPLS-FS-BIRTH-DATE TO REP-FS-BIRTH-DATE. # MOVE PPLS-FS-DEATH-DATE TO REP-FS-DEATH-DATE. #0001N WRITE REP-FS. *----------------------------------------------------------------- * Z100-CLEANUP * Standard cleaup routine, use it to define actions which needs * to be done before program ends (either normally or abnormally). *----------------------------------------------------------------- Z100-CLEANUP. #0001N CLOSE REP-FILE. STOP RUN.
Comments: - The changelog was added at the beginning of the program. In there, you can find a programmer name, change description, and modification date. Change ID is an internal change indicator which is also used for line markers. - Line markers follow a specific convention. "MnnnnO" where 'M' is an indicator saying if the line was added or excluded from the code (#-Added, $-Excluded for example). Thanks to this convention, you'll be able to easily exclude old code with EX command using this indicator. "nnnn" is the change ID. "O" is operation indicator (N - new line, D - deleted line, U - updated line). - There should be a specific procedure for modification removal. A reasonable solution is set a specific amount of year after which modifications can be removed. For example, 3 years. Program after running 3 years is obviously very well tested and the old code is unlikely to be useful. In other shops it may be 10 years. Yet in another changes may be removed after 5 software developments cycles. - Line markers are only useful if your shop doesn't have software which stores old versions of code or it cannot provide a quick comparison of changes between old and new versions of the code. If you have such software, there is no point in maintaining markers as shown here.
Solution 5
Rule 1: Use two or four spaces for indicating which instruction belongs to which blocks. Four spaces are considered standard but if you code under ISPF using two have more benefits. Less clicking and more characters in records are left for instructions. Readability of both versions is the same.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF. ----------------------------------------------------------------- ALSO GOOD ----------------------------------------------------------------- IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF.
Rule 2: Spead complex instruction across many lines.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE. ----------------------------------------------------------------- ALSO BAD – THE RULE IS OVERDONE HERE ----------------------------------------------------------------- SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- DISPLAY PPLS-FZ-PERS-NUMBER " " PPLS-FT-FIRST-NAME " " PPLS-FT-LAST-NAME " " PPLS-FT-GENDER " " PPLS-FS-BIRTH-DATE " " PPLS-FS-DEATH-DATE " " PPL-WE-AGE-YEARS " " PPL-WE-AGE-DAYS. ----------------------------------------------------------------- ALMOST GOOD ----------------------------------------------------------------- DISPLAY PPLS-FZ-PERS-NUMBER " " PPLS-FT-FIRST-NAME " " PPLS-FT-LAST-NAME " " PPLS-FT-GENDER " " PPLS-FS-BIRTH-DATE " " PPLS-FS-DEATH-DATE " " PPL-WE-AGE-YEARS " " PPL-WE-AGE-DAYS. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- DISPLAY PPLS-FZ-PERS-NUMBER " " PPLS-FT-FIRST-NAME " " PPLS-FT-LAST-NAME " " PPLS-FT-GENDER " " PPLS-FS-BIRTH-DATE " " PPLS-FS-DEATH-DATE " " PPL-WE-AGE-YEARS " " PPL-WE-AGE-DAYS.
Rule 3: Put all PIC clauses in the same column. Generally column 50 is an optimal choice to start PIC clauses.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- 77 WB-INT-DATE-START PIC 9(9) USAGE COMP. 77 WB-INT-DATE-END PIC 9(9) USAGE COMP. 77 WZ-TEMP-DATE PIC 9(8). ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- 77 WB-INT-DATE-START PIC 9(9) USAGE COMP. 77 WB-INT-DATE-END PIC 9(9) USAGE COMP. 77 WZ-TEMP-DATE PIC 9(8).
Rule 4: Be sure to indent PIC items accordingly to their level.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- 01 REP-FS. 05 REP-FZ-PERS-NUMBER PIC 9(11). 05 REP-FT-FIRST-NAME PIC X(15). 05 REP-FT-LAST-NAME PIC X(15). 05 REP-FT-GENDER PIC X. 05 REP-FS-BIRTH-DATE. 10 REP-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 REP-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 REP-FZ-BDAY PIC 9(2). ----------------------------------------------------------------- ALSO BAD ----------------------------------------------------------------- 01 REP-FS. 05 REP-FZ-PERS-NUMBER PIC 9(11). 05 REP-FT-FIRST-NAME PIC X(15). 05 REP-FT-LAST-NAME PIC X(15). 05 REP-FT-GENDER PIC X. 05 REP-FS-BIRTH-DATE. 10 REP-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 REP-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 REP-FZ-BDAY PIC 9(2). ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- 01 REP-FS. 05 REP-FZ-PERS-NUMBER PIC 9(11). 05 REP-FT-FIRST-NAME PIC X(15). 05 REP-FT-LAST-NAME PIC X(15). 05 REP-FT-GENDER PIC X. 05 REP-FS-BIRTH-DATE. 10 REP-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 REP-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 REP-FZ-BDAY PIC 9(2). ----------------------------------------------------------------- EVEN BETTER ----------------------------------------------------------------- 01 REP-FS. 05 REP-FZ-PERS-NUMBER PIC 9(11). 05 REP-FT-FIRST-NAME PIC X(15). 05 REP-FT-LAST-NAME PIC X(15). 05 REP-FT-GENDER PIC X. 05 REP-FS-BIRTH-DATE. 10 REP-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 REP-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 REP-FZ-BDAY PIC 9(2).
Rule 5: Always increase variable levels number by 5.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- 01 REP-FS. 03 REP-FZ-PERS-NUMBER PIC 9(11). 03 REP-FT-FIRST-NAME PIC X(15). 03 REP-FT-LAST-NAME PIC X(15). 03 REP-FT-GENDER PIC X. 03 REP-FS-BIRTH-DATE. 06 REP-FZ-BYEAR PIC 9(4). 06 FILLER PIC X. 06 REP-FZ-BMONTH PIC 9(2). 06 FILLER PIC X. 06 REP-FZ-BDAY PIC 9(2). ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- 01 REP-FS. 05 REP-FZ-PERS-NUMBER PIC 9(11). 05 REP-FT-FIRST-NAME PIC X(15). 05 REP-FT-LAST-NAME PIC X(15). 05 REP-FT-GENDER PIC X. 05 REP-FS-BIRTH-DATE. 10 REP-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 REP-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 REP-FZ-BDAY PIC 9(2).
Rule 6: Put empty lines between instructions. This is an optional rule since it has both good and bad sides. The good side is slightly improved readability. The bad is that you'll be able to see less code on the screen at once and that you'll have to spend more time on code editing.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- COMPUTE WB-INT-DATE-START = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- COMPUTE WB-INT-DATE-START = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). IF PPLS-FZ-DYEAR = 9999 MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE ELSE COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY END-COMPUTE END-IF.
Rule 7: Indent similar parts of the same instruction to the same column. This is a rule which can both improve and harm code readability so you must use your intuition to judge which structure is the best.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- MOVE PPLS-FZ-PERS-NUMBER TO REP-FZ-PERS-NUMBER. MOVE PPLS-FT-FIRST-NAME TO REP-FT-FIRST-NAME. MOVE PPLS-FT-LAST-NAME TO REP-FT-LAST-NAME. MOVE PPLS-FT-GENDER TO REP-FT-GENDER. MOVE PPLS-FS-BIRTH-DATE TO REP-FS-BIRTH-DATE. MOVE PPLS-FS-DEATH-DATE TO REP-FS-DEATH-DATE. COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- MOVE PPLS-FZ-PERS-NUMBER TO REP-FZ-PERS-NUMBER. MOVE PPLS-FT-FIRST-NAME TO REP-FT-FIRST-NAME. MOVE PPLS-FT-LAST-NAME TO REP-FT-LAST-NAME. MOVE PPLS-FT-GENDER TO REP-FT-GENDER. MOVE PPLS-FS-BIRTH-DATE TO REP-FS-BIRTH-DATE. MOVE PPLS-FS-DEATH-DATE TO REP-FS-DEATH-DATE. COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 + PPLS-FZ-DMONTH * 100 + PPLS-FZ-DDAY SORT PPLS-FILE ASCENDING KEY PPLS-FS-BIRTH-DATE USING PPL-FILE OUTPUT PROCEDURE 3100-DISPLAY-FILE.
Rule 8: Place paragraphs in the right order.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- Z100-CLEANUP. ... 3000-SORT-AND-DISPLAY. ... 4000-SOME-PROCESSING. ... 3100-DISPLAY-FILE. ... 3110-CALCULATE-AGE. ... ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- 3000-SORT-AND-DISPLAY. ... 3100-DISPLAY-FILE. ... 3110-CALCULATE-AGE. ... 4000-SOME-PROCESSING. ... Z100-CLEANUP. ...
Rule 9: Indent "END" clauses to the "start" clauses.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL" END-IF. IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL" END-IF. ----------------------------------------------------------------- VERY BAD ----------------------------------------------------------------- IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL" END-IF. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- IF SORT-RETURN NOT = 0 DISPLAY "SORT UNSUCCESSFUL" END-IF.
Rule 10: Always code END-IF.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- IF OPTION = 1 PERFORM OPTION-1 ELSE IF OPTION = 2 PERFORM OPTION-2 ELSE IF OPTION = 0 PERFORM END-PROGRAM ELSE PERFORM INPUT-ERROR. ----------------------------------------------------------------- KIND OF GOOD – SEE THE NEXT RULE ----------------------------------------------------------------- IF OPTION = 1 PERFORM OPTION-1 ELSE IF OPTION = 2 PERFORM OPTION-2 ELSE IF OPTION = 0 PERFORM END-PROGRAM ELSE PERFORM INPUT-ERROR END-IF END-IF END-IF.
Rule 11: Use EVALUATE instead of complex IFs.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- IF OPTION = 1 PERFORM OPTION-1 ELSE IF OPTION = 2 PERFORM OPTION-2 ELSE IF OPTION = 0 PERFORM END-PROGRAM ELSE PERFORM INPUT-ERROR END-IF END-IF END-IF. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- EVALUATE OPTION WHEN 1 PERFORM OPTION-1 WHEN 2 PERFORM OPTION-2 WHEN 0 PERFORM END-PROGRAM WHEN OTHER PERFORM INPUT-ERROR END-EVALUATE.
Rule 12: Do not use user-defined SECTIONs. SECTIONs in COBOL have exactly the same purpose as paragraphs. They are simply an additional layer of code grouping. The thing is that using sections increases program complexity and therefore reduces program readability. Therefore, it's best to depend only on the paragraphs for designing program logic.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- MAIN-LOGIC SECTION. ... MAIN. ... ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- MAIN. ...
Rule 13: Never use PERFORM para1 THRU para5. Using PERFORM THRU maybe save you a few lines of code, but it can introduce errors to new programs. For example, if someone by mistake adds a paragraph in between the ones used in such PERFORM, it will be unnecessarily executed. It also decreases code readability. Therefore, it's never worth using.
----------------------------------------------------------------- BAD ----------------------------------------------------------------- PERFORM 1000-INIT THRU 3000-SORT-AND-DISPLAY. ----------------------------------------------------------------- GOOD ----------------------------------------------------------------- PERFORM 1000-INIT. PERFORM 2000-DISPLAY-HEADER. PERFORM 3000-SORT-AND-DISPLAY.
To sum it up: Rule 1: Use two or four spaces for indicating which instruction belongs to which blocks. Rule 2: Spead complex instruction across many lines. Rule 3: Put all PIC clauses in the same column. Rule 4: Be sure to indent PIC items accordingly to their level. Rule 5: Always increase variable levels number by 5. Rule 6: Put empty lines between instructions. Rule 7: Indent similar parts of the same instruction to the same column. Rule 8: Place paragraphs in the right order. Rule 9: Indent "END" clauses to the "start" clauses. Rule 10: Always code END-IF. Rule 11: Use EVALUATE instead of complex IFs. Rule 12: Do not use user-defined SECTIONs. Rule 13: Never use PERFORM para1 THRU para5.
Solution 6
This rule states that you should avoid using keywords which are not required by the COBOL syntax. This will eliminate a few additional places where you can make an error and it will improve code readability. A few examples: - Don't use USAGE keyword next to PIC clauses. - Don't use RECORDING MODE keyword for fixed record format. - Use FILLER for fields that do not contain meaningful data. - Don't use PICTURE, use PIC. Of course, there are exceptions to this rule: - Some people prefer to add "END-" instructions even if they're not needed, such as END-READ. In the case of "END-IF" coding it each time is good, but in other cases not so much. - It's better to code optional keyword if they make the particular instruction clearer. For example, using ASCENDING/DESCENDING in SORT instruction. - FILLER shouldn't be used for fields with data, even if those fields are not used in the program.
Solution 7
Full code:
//JSADEKRN JOB NOTIFY=&SYSUID //*--------------------------------------------------------------------- //DELSTEP EXEC PGM=IEFBR14 //DELDD DD DISP=(MOD,DELETE),SPACE=(TRK,1), // DSN=JSADEK.COBOL.PEOPLE.OUT //*--------------------------------------------------------------------- //PRESORT EXEC PGM=SORT //SYSOUT DD SYSOUT=* //SORTIN DD DISP=SHR,DSN=JSADEK.COBOL.PEOPLE //SORTOUT DD DSN=&&TEMPFILE,DISP=(NEW,PASS),SPACE=(TRK,(1,1)) //SYSIN DD * SORT FIELDS=(43,10,CH,A) //*--------------------------------------------------------------------- //RUNCOBOL EXEC IGYWCLG //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1604) //GO.REPFILE DD DSN=JSADEK.COBOL.PEOPLE.OUT,DISP=(NEW,CATLG), // LRECL=80,BLKSIZE=8000,RECFM=FB,SPACE=(TRK,(1,1)) //GO.PPLFILE DD DISP=SHR,DSN=&&TEMPFILE //GO.PPLSFILE DD DISP=(NEW,DELETE),UNIT=3390,SPACE=(CYL,(5,5)), // DSN=&&SORTWRK //COBOL.SYSIN DD * *----------------------------------------------------------------- * ### Program description ### * * Program reads employees personal data and calculates their age. *----------------------------------------------------------------- * ### Inputs ### * * - 'JSADEK.COBOL.PEOPLE(0)' data set. It needs to be pre-sorted * via BIRTH-DATE before this program processes it. *----------------------------------------------------------------- * ### Outputs ### * * - REPFILE - Sorted input with added age calculation. *----------------------------------------------------------------- * ### Called sub-programs ### * * None *----------------------------------------------------------------- * ### System-related dependencies ### * * Batch program - JES2 & Scheduler *----------------------------------------------------------------- * ### Security considerations ### * * Program read and produces company's confidential data. * It cannot leave internal infrastructure without an approval. *----------------------------------------------------------------- * ### Change Log ### *----------------------------------------------------------------- *CHNG| PROG | DATE | TICKET | SHORT DESCRIPTION * ID | ID |YYYYMMDD| NUMBER | *----------------------------------------------------------------- *0000|JSADEK |20181004| N/A | First version of program created *----------------------------------------------------------------- *0001|JSADEK |20181005| N/A | Output destination changed from * | | | | SYSOUT to data set. *----------------------------------------------------------------- *0002|JSADEK |20181008| N/A | Input sort outsourced from code * | | | | to JCL step. *----------------------------------------------------------------- * | | | | COPY RECORD *----------------------------------------------------------------- IDENTIFICATION DIVISION. * PROGRAM-ID. MP1604. * AUTHOR. JSADEK (myemail@gmail.com) * DATE-WRITTEN. 2018.10.04. * ENVIRONMENT DIVISION. * INPUT-OUTPUT SECTION. * FILE-CONTROL. *----------------------------------------------------------------- * PPL-FILE contains employees data from which the age is * calculated *----------------------------------------------------------------- SELECT PPL-FILE ASSIGN TO PPLFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS PPL-WT-FS. #0001N*----------------------------------------------------------------- # * REP-FILE output - stores sorted input with added employee age # *----------------------------------------------------------------- # SELECT REP-FILE # ASSIGN TO REPFILE # ORGANIZATION IS SEQUENTIAL #0001N FILE STATUS IS REP-WT-FS. $0002D*----------------------------------------------------------------- $ * Sort file for sorting PPL-FILE $ *----------------------------------------------------------------- $ * SELECT PPLS-FILE $0002D* ASSIGN TO PPLSFILE. * DATA DIVISION. * FILE SECTION. * FD PPL-FILE. 01 PPL-FS. *----------------------------------------------------------------- * Employee personal number (Polish format). *----------------------------------------------------------------- 05 PPL-FZ-PERS-NUMBER PIC 9(11). 05 PPL-FT-FIRST-NAME PIC X(15). 05 PPL-FT-LAST-NAME PIC X(15). 05 PPL-FT-GENDER PIC X. 05 PPL-FS-BIRTH-DATE. 10 PPL-FZ-BYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-BMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-BDAY PIC 9(2). *----------------------------------------------------------------- * '9999-01-01' value indicates that the person is still alive. *----------------------------------------------------------------- 05 PPL-FS-DEATH-DATE. 10 PPL-FZ-DYEAR PIC 9(4). 10 FILLER PIC X. 10 PPL-FZ-DMONTH PIC 9(2). 10 FILLER PIC X. 10 PPL-FZ-DDAY PIC 9(2). *----------------------------------------------------------------- * The last 18 bytes in file are reseved for future use (LRECL=80) *----------------------------------------------------------------- 05 FILLER PIC X(18). * #0001N FD REP-FILE. # 01 REP-FS. # 05 REP-FZ-PERS-NUMBER PIC 9(11). # 05 REP-FT-FIRST-NAME PIC X(15). # 05 REP-FT-LAST-NAME PIC X(15). # 05 REP-FT-GENDER PIC X. # 05 REP-FS-BIRTH-DATE. # 10 REP-FZ-BYEAR PIC 9(4). # 10 FILLER PIC X. # 10 REP-FZ-BMONTH PIC 9(2). # 10 FILLER PIC X. # 10 REP-FZ-BDAY PIC 9(2). # 05 REP-FS-DEATH-DATE. # 10 REP-FZ-DYEAR PIC 9(4). # 10 FILLER PIC X. # 10 REP-FZ-DMONTH PIC 9(2). # 10 FILLER PIC X. # 10 REP-FZ-DDAY PIC 9(2). # 05 REP-FE-AGE-IN-YEARS PIC ZZ9.9(2). # 05 REP-FE-AGE-IN-DAYS PIC Z(4)9. #0001N 05 FILLER PIC X(7). * $0002D*SD PPLS-FILE. $ *01 PPLS-FS. $ * 05 PPLS-FZ-PERS-NUMBER PIC 9(11). $ * 05 PPLS-FT-FIRST-NAME PIC X(15). $ * 05 PPLS-FT-LAST-NAME PIC X(15). $ * 05 PPLS-FT-GENDER PIC X. $ * 05 PPLS-FS-BIRTH-DATE. $ * 10 PPLS-FZ-BYEAR PIC 9(4). $ * 10 FILLER PIC X. $ * 10 PPLS-FZ-BMONTH PIC 9(2). $ * 10 FILLER PIC X. $ * 10 PPLS-FZ-BDAY PIC 9(2). $ * 05 PPLS-FS-DEATH-DATE. $ * 10 PPLS-FZ-DYEAR PIC 9(4). $ * 10 FILLER PIC X. $ * 10 PPLS-FZ-DMONTH PIC 9(2). $ * 10 FILLER PIC X. $ * 10 PPLS-FZ-DDAY PIC 9(2). $0002D* 05 FILLER PIC X(18). * WORKING-STORAGE SECTION. $0002D*----------------------------------------------------------------- $ * End of file indicator for PPLS sort file. $ *----------------------------------------------------------------- $0002D*77 PPLS-WZ-EOF PIC 9 VALUE 0. #0002N*----------------------------------------------------------------- # * End of file indicator for PPL sort file. # *----------------------------------------------------------------- #0002N 77 PPL-WZ-EOF PIC 9 VALUE 0. *----------------------------------------------------------------- * File status variable for PPL input file. *----------------------------------------------------------------- 77 PPL-WT-FS PIC X(2). #0001N*----------------------------------------------------------------- # * File status variable for REP output file. # *----------------------------------------------------------------- #0001N 77 REP-WT-FS PIC X(2). *----------------------------------------------------------------- * Variable for storing employee age in years. *----------------------------------------------------------------- 77 PPL-WZ-AGE-YEARS PIC 9(3)V9(2). $0001D*----------------------------------------------------------------- $ * DISPLAY version of PPL-WZ-AGE-YEARS. $ *----------------------------------------------------------------- $0001D*77 PPL-WE-AGE-YEARS PIC ZZ9.9(2). *----------------------------------------------------------------- * Variable for storing employee age in days. *----------------------------------------------------------------- 77 PPL-WZ-AGE-DAYS PIC 9(5). $0001D*----------------------------------------------------------------- $ * DISPLAY version of PPL-WZ-AGE-DAYS. $ *----------------------------------------------------------------- $0001D*77 PPL-WE-AGE-DAYS PIC Z(4)9. *----------------------------------------------------------------- * Two variables storing BIRTH-DATE and either DEATH-DATE or * current date in INT format. Used in calculation only. *----------------------------------------------------------------- 77 WB-INT-DATE-START PIC 9(9) COMP. 77 WB-INT-DATE-END PIC 9(9) COMP. *----------------------------------------------------------------- * Temporary variable used during conversion from 'YYYY-MM-DD' * format to INT date format. *----------------------------------------------------------------- 77 WZ-TEMP-DATE PIC 9(8). * PROCEDURE DIVISION. * DECLARATIVES. *----------------------------------------------------------------- * File handling rountine for PPL-FILE. * In this execution path Z100-CLEANUP is not executed so be sure * to also add here cleanup istructions if needed. *----------------------------------------------------------------- FILE-ERRORS SECTION. $0001U* USE AFTER ERROR PROCEDURE ON PPL-FILE. #0001N USE AFTER ERROR PROCEDURE ON PPL-FILE REP-FILE. * FILE-ERROR. * DISPLAY "FILE ERROR OCCUREED:". * DISPLAY "'PPLFILE' STATUS: " PPL-WT-FS. * #0001N DISPLAY "'REPFILE' STATUS: " REP-WT-FS. * DISPLAY "PROGRAM TERMINATES.". * *----------------------------------------------------------------- * Loop prevention. '42' means that program attemted to close the * file which is already closed. *----------------------------------------------------------------- IF PPL-WT-FS NOT = "42" CLOSE PPL-FILE. * #0001N IF REP-WT-FS NOT = "42" #0001N CLOSE REP-FILE. * MOVE 12 TO RETURN-CODE. * STOP RUN. * END DECLARATIVES. * *----------------------------------------------------------------- * 0000-MAIN * Main program routine. *----------------------------------------------------------------- 0000-MAIN. * PERFORM 1000-INIT. * $0001D* PERFORM 2000-DISPLAY-HEADER. * $0002D* PERFORM 3000-SORT-AND-DISPLAY. #0002N PERFORM 3100-DISPLAY-FILE. * PERFORM Z100-CLEANUP. * *----------------------------------------------------------------- * 1000-INIT * Initialization routine. *----------------------------------------------------------------- 1000-INIT. * MOVE "SORTMSG" TO SORT-MESSAGE. * #0001N OPEN OUTPUT REP-FILE. * #0002N OPEN INPUT PPL-FILE. * $0001D*----------------------------------------------------------------- $ * 2000-DISPLAY-HEADER $ * Displays the header for easier column identification. $ *----------------------------------------------------------------- $ *2000-DISPLAY-HEADER. $ * DISPLAY "-----------|---------------|---------------|" $ * "-|----------|----------|------|-----". $ * DISPLAY "PERS NUMBER|FIRST NAME |LAST NAME |" $ * "G|BIRTH DATE|DEATH DATE|YEARS |DAYS ". $ * DISPLAY "-----------|---------------|---------------|" $0001D* "-|----------|----------|------|-----". * $0002D*----------------------------------------------------------------- $ * 3000-SORT-AND-DISPLAY $ * Displays the header for easier column identification. $ *----------------------------------------------------------------- $ *3000-SORT-AND-DISPLAY. $ * $ * SORT PPLS-FILE $ * ASCENDING $ * KEY PPLS-FS-BIRTH-DATE $ * USING PPL-FILE $ * OUTPUT PROCEDURE 3100-DISPLAY-FILE. $ * $ * IF SORT-RETURN NOT = 0 $ * $ * DISPLAY "SORT UNSUCCESSFUL" $ * $ * MOVE SORT-RETURN TO RETURN-CODE $ * $ * PERFORM Z100-CLEANUP $ * $0002D* END-IF. * *----------------------------------------------------------------- * 3100-DISPLAY-FILE * Sort output procedure. Gets sorted records one by one * and passes them for futher processing. *----------------------------------------------------------------- 3100-DISPLAY-FILE. * $0002U* RETURN PPLS-FILE $ * AT END $ * MOVE 1 TO PPLS-WZ-EOF. $ * $0002U* PERFORM UNTIL PPLS-WZ-EOF = 1 #0002N READ PPL-FILE # AT END # MOVE 1 TO PPL-WZ-EOF. # #0002N PERFORM UNTIL PPL-WZ-EOF = 1 * PERFORM 3110-CALCULATE-AGE * PERFORM 3120-DISPLAY-RECORD * $0002U* RETURN PPLS-FILE $ * AT END $ * MOVE 1 TO PPLS-WZ-EOF $0002U* END-RETURN #0002N READ PPL-FILE # AT END # MOVE 1 TO PPL-WZ-EOF #0002N END-READ * END-PERFORM. * *----------------------------------------------------------------- * 3110-CALCULATE-AGE * Computes employee age in years and days on the basis of the * BIRTH-DATE and DEATH-DATE variables. *----------------------------------------------------------------- 3110-CALCULATE-AGE. * PERFORM 3111-CONVERT-DATES-TO-INT. * *----------------------------------------------------------------- * Calculates number of days between from BIRTH-DATE * and DEATH-DATE or CURRENT-TIME *----------------------------------------------------------------- COMPUTE PPL-WZ-AGE-DAYS = WB-INT-DATE-END - WB-INT-DATE-START. * *----------------------------------------------------------------- * Calculating age in years on the basis of age value in days. *----------------------------------------------------------------- COMPUTE PPL-WZ-AGE-YEARS = PPL-WZ-AGE-DAYS / 365.25. * *----------------------------------------------------------------- * Initializes output record so it doesn't contain nulls. *----------------------------------------------------------------- #0001N MOVE SPACES TO REP-FS. * *----------------------------------------------------------------- * Moves numbers in ZD format to EDITED variables. *----------------------------------------------------------------- $0001U* MOVE PPL-WZ-AGE-DAYS TO PPL-WE-AGE-DAYS. #0001N MOVE PPL-WZ-AGE-DAYS TO REP-FE-AGE-IN-DAYS. * $0001U* MOVE PPL-WZ-AGE-YEARS TO PPL-WE-AGE-YEARS. #0001N MOVE PPL-WZ-AGE-YEARS TO REP-FE-AGE-IN-YEARS. * *----------------------------------------------------------------- * 3111-CONVERT-DATES-TO-INT * Converts BIRTH-DATE and DEATH-DATE/CURRENT-DATE from * 'YYYY-MM-DD' to INT format. *----------------------------------------------------------------- 3111-CONVERT-DATES-TO-INT. * *----------------------------------------------------------------- * Converts birth date to INT format (YYYYMMDD). *----------------------------------------------------------------- $0002U* COMPUTE WZ-TEMP-DATE = PPLS-FZ-BYEAR * 10000 $ * + PPLS-FZ-BMONTH * 100 $0002U* + PPLS-FZ-BDAY. #0002N COMPUTE WZ-TEMP-DATE = PPL-FZ-BYEAR * 10000 # + PPL-FZ-BMONTH * 100 #0002N + PPL-FZ-BDAY. * *----------------------------------------------------------------- * Converts INT (YYYYMMDD) format into COBOL INT date * representation. *----------------------------------------------------------------- COMPUTE WB-INT-DATE-START = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). * *----------------------------------------------------------------- * IF checks if person is still alive and on this basis decides * if DEATH-DATE or CURRENT-DATE is used for age calculation. *----------------------------------------------------------------- * $0002U* IF PPLS-FZ-DYEAR = 9999 #0002N IF PPL-FZ-DYEAR = 9999 * MOVE FUNCTION CURRENT-DATE(1 : 8) TO WZ-TEMP-DATE * ELSE * $0002U* COMPUTE WZ-TEMP-DATE = PPLS-FZ-DYEAR * 10000 $ * + PPLS-FZ-DMONTH * 100 $0002U* + PPLS-FZ-DDAY #0002N COMPUTE WZ-TEMP-DATE = PPL-FZ-DYEAR * 10000 # + PPL-FZ-DMONTH * 100 #0002N + PPL-FZ-DDAY END-COMPUTE * END-IF. * *----------------------------------------------------------------- * Converts DEATH-DATE / CURRENT-DATE into COBOL INT date * representation. *----------------------------------------------------------------- COMPUTE WB-INT-DATE-END = FUNCTION INTEGER-OF-DATE(WZ-TEMP-DATE). * *----------------------------------------------------------------- * 3120-DISPLAY-RECORD * Display a single employee record with calculated age. *----------------------------------------------------------------- 3120-DISPLAY-RECORD. * $0001U* DISPLAY PPLS-FZ-PERS-NUMBER " " PPLS-FT-FIRST-NAME $ * " " PPLS-FT-LAST-NAME " " PPLS-FT-GENDER $ * " " PPLS-FS-BIRTH-DATE " " PPLS-FS-DEATH-DATE $0001U* " " PPL-WE-AGE-YEARS " " PPL-WE-AGE-DAYS. $0002U* MOVE PPLS-FZ-PERS-NUMBER TO REP-FZ-PERS-NUMBER. $ * $ * MOVE PPLS-FT-FIRST-NAME TO REP-FT-FIRST-NAME. $ * $ * MOVE PPLS-FT-LAST-NAME TO REP-FT-LAST-NAME. $ * $ * MOVE PPLS-FT-GENDER TO REP-FT-GENDER. $ * $ * MOVE PPLS-FS-BIRTH-DATE TO REP-FS-BIRTH-DATE. $ * $ * MOVE PPLS-FS-DEATH-DATE TO REP-FS-DEATH-DATE. $ * $0002U* WRITE REP-FS. #0002N MOVE PPL-FZ-PERS-NUMBER TO REP-FZ-PERS-NUMBER. # * # MOVE PPL-FT-FIRST-NAME TO REP-FT-FIRST-NAME. # * # MOVE PPL-FT-LAST-NAME TO REP-FT-LAST-NAME. # * # MOVE PPL-FT-GENDER TO REP-FT-GENDER. # * # MOVE PPL-FS-BIRTH-DATE TO REP-FS-BIRTH-DATE. # * # MOVE PPL-FS-DEATH-DATE TO REP-FS-DEATH-DATE. # * #0002N WRITE REP-FS. * *----------------------------------------------------------------- * Z100-CLEANUP * Standard cleaup routine, use it to define actions which needs * to be done before program ends (either normally or abnormally). *----------------------------------------------------------------- Z100-CLEANUP. * #0001N CLOSE REP-FILE. #0002N CLOSE PPL-FILE. * STOP RUN.
Comments: - The "Pay attention to the environment in which the program will run" rule, generally states that if you can outsource some processing to JCL or other functions provided by the environment (also CLE) you should seriously consider it. - Doing pre-sort in the step which precedes program execution is a common practice. It is done mainly for performance reasons. Standalone DFSORT is usually faster than the one invoked via COBOL. - Another reason why doing DFSORT in JCL is a good idea is that it simplifies the source code. So you remove yet another place where an error can appear. - To sum it up, during the design phase of the program you should always consider if needed processing cannot be done before the data is passed to your program. This can save you a lot of time, both in the coding and testing phase. Comments regarding code structure: - As you can see, the code became very messy at this point, even paragraph numeration got broken a little bit. - The most damaging practice when it comes to code readability is keeping the old code lines in the source. As mentioned earlier, nowadays this is rarely a problem since code versioning is managed by external software such as ChangeMan. - Now the only way to comfortably read the code is to use EXCLUDE command. "EX '$' 1 ALL" will exclude lines that were updated or removed, while "EX '*' 7 ALL" will exclude all comments.
Solution 8
KISS (Keep It Simple, Stupid) is the iron rule of programming. It ensures the following benefits: - Fewer errors during coding. - The decreased probability that any error passes the testing phase unnoticed. - Easier code maintenance. - Easier code analysis and therefore faster response for program-related incidents. - Saving in programmer time. - Saving in company money. ________________________________________ - Is it better to use complex algorithms to save processor power or spread the code across more instructions but keep it more easily readable? It's always better to keep the code simple and clear, even if it may be slower than the more complicated version. The main reason for that is that the time spent on program optimization, maintenance, and error handling in complex programs usually cost much more than some additional processing power. This is true even on Mainframes where customers actually pay for processor power, not to mention other systems where they only pay for hardware. Also, a very small percentage of programs is actually so resource consuming that optimization should be done at all. If a program runs for 0.005s a few times per day, decreasing it to 0.003s is not worth the effort. Only if the program runs for many minutes or executes thousands of times each day it should become the focus for optimization. ________________________________________ - Is it better to reuse some variables such as subscripts or computational items or to define a separate variable for each instruction? It's better to define different variables for each use, even if some variables are used only in one place in a program. This makes program analysis easier, especially to someone unfamiliar with the code. Loop iterators and temporary variables are exceptions here. But even in such cases, you should clearly indicate in comments what is the purpose of those variables. ________________________________________ - Should you always optimize your code for performance? The simple answer is no. There are basically three exceptions to that: - Large DB2 queries. - Loops executed thousands of times. - CICS transactions that are supposed to run thousands of times each day. In those three cases, you should pay special attention to program/query performance and spend some time ensuring it is well-optimized. In all other cases, programmer's time is usually much more expensive than processor power and even a few hours spend on optimization may cost more than processor power saved in such a way in years. ________________________________________ - Is it better to outsource some of the program functionality to a sub-program if you suspect this functionality could be needed by other programs? It really depends on the team you're working in. Sometimes, such decisions are made by software architects, and the only thing you should do is to pass the idea to them. In other teams, programmers can make such decisions, and it may be indeed a good idea, unless you don't unnecessarily complicate the software this way. ________________________________________ - Should you ensure your programs handles all possible errors? No again. Actually this rule should be followed but only after taking into account another rule "Know your data". What that all means? It means that first and foremost, you need to know the program input data. If there is a possibility that records in some column are duplicated, or if they can be empty. What are the possible values and what values may indicate an error condition? You should also be aware of possible technical errors such as missing file and protect your program from them. But generally testing your program for all possibilities makes coding many times longer, and code harder to maintain. So you should test your code for all possible errors, but only within the boundaries defined by the data on which program is supposed to work and the environment in which it will run. For example, if the program runs via batch, you don't need to check if the file exists because it will be checked by the JES2 and the initiator. If you know that DB2 column is defined with UNIQUE NOT NULL, don't test if there is some data in there, you know it is. (NOT NULL in case of text fields only ensure that field won't be empty, but it may be filled with spaces, so you must test for spaces but not for nulls). ________________________________________ - Is it better to reuse and customize your older code for a new program or rewrite it from scratch? Usually, it's better to reuse you're older code. Over the years you'll notice which fragments of code tend to reoccur often. Be sure to copy them as templates for future uses. Using a tested paragraph and adapting it to a new program is simply faster than rewriting it from the beginning. It also decreases the probability of making errors.
Solution 9
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1609. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 TIM-WS-TIMESTAMP. 05 TIM-WS-DATE. 10 TIM-WZ-YEAR PIC 9(4). 10 TIM-WZ-MONTH PIC 9(2). 10 TIM-WZ-DAY PIC 9(2). 05 TIM-WS-TIME. 10 TIM-WZ-HOUR PIC 9(2). 10 TIM-WZ-MINUTE PIC 9(2). 10 TIM-WZ-SECOND PIC 9(2). 05 TIMR-WS-TIME REDEFINES TIM-WS-TIME. 10 TIMR-WZ-SHORT-TIME PIC 9(4). 10 TIMR-WZ-SECOND PIC 9(2). 05 TIM-WZ-HMILI PIC 9(2). 05 TIM-WT-ZONE-MARK PIC X. 05 TIM-WZ-ZONE-HOUR PIC 9(2). 05 TIM-WZ-ZONE-MINUTE PIC 9(2). 66 WT-SHORT-TIME RENAMES TIM-WZ-HOUR THRU TIM-WZ-MINUTE. PROCEDURE DIVISION. 0000-MAIN-LOGIC. MOVE FUNCTION CURRENT-DATE TO TIM-WS-TIMESTAMP. PERFORM 1000-DISPLAY-TIMESTAMP. PERFORM 2000-DISPLAY-RENAMES. PERFORM 3000-DISPLAY-REDEFINES. STOP RUN. 1000-DISPLAY-TIMESTAMP. DISPLAY TIM-WS-TIMESTAMP. 2000-DISPLAY-RENAMES. DISPLAY WT-SHORT-TIME. * ERROR: CALCULATION ON ALPHANUMERIC ITEM. * ADD 10 TO WT-SHORT-TIME. 3000-DISPLAY-REDEFINES. DISPLAY TIMR-WZ-SHORT-TIME. ADD 10 TO TIMR-WZ-SHORT-TIME. DISPLAY TIMR-WZ-SHORT-TIME.
Comments: - REDEFINES clause is used for the creation of an alternative PIC definition for an existing variable. The REFER variable points to the same storage as the referred one but it makes the data interpreted in a different way. For example, you can refer to zone-decimal number as if it was a text and the other way around. - RENAMES clause cannot do that. It can only rename a variable or a set of variables as in this example. So its main purpose is to regroup a set of variables. - The reason why you shouldn't use 66 items is simply that they're not needed. Everything that's done through RENAMES clause can be also realized with REDEFINES, which also has some additional functionality. Of course, if you don't have to use REDEFINES, it's best to avoid it as well. - 77 items are also not needed. Defining variables under 77 level only limits what you can do with a variable and leads to errors when you want to change 77 items to a structure or REDEFINE it. Basically, using 77 items have no benefits, only create problems, small problems but always.
Solution 10
Thanks to the fact that the program runs via JCL the initiator checks if the input file exists and ensures that the output file doesn't. If those conditions aren't met the job will end in JCL error. To test whether the file is empty or not, we can add a new step to the JCL:
//IFEMPTY EXEC PGM=IEBPTPCH //SYSPRINT DD SYSOUT=* //SYSUT1 DD DISP=SHR,DSN=&&TEMPFILE //SYSUT2 DD DUMMY //SYSIN DD * PUNCH MAXFLDS=1 RECORD FIELD=(72)
This step will end with RC=4 if the printed file does not contain any records and with RC=0 if the records are present. To check if BIRTH-DATE and DEATH-DATE are present in the file we can simply test for empty string and nulls. You can also make a little bit more detailed test:
*----------------------------------------------------------------- * 3110-VERIFY-THE-DATES * Checks if the dates are present and are numerics *----------------------------------------------------------------- 3110-VERIFY-THE-DATES. IF PPL-FZ-BYEAR < 1900 OR PPL-FZ-BYEAR > 2300 OR PPL-FZ-BMONTH < 1 OR PPL-FZ-BMONTH > 12 OR PPL-FZ-BDAY < 1 OR PPL-FZ-BDAY > 31 OR ( PPL-FZ-DYEAR NOT = 9999 AND ( PPL-FZ-BYEAR < 1900 OR PPL-FZ-BYEAR > 2400 ) ) OR PPL-FZ-DMONTH < 1 OR PPL-FZ-DMONTH > 12 OR PPL-FZ-DDAY < 1 OR PPL-FZ-DDAY > 31 DISPLAY "Invalid date" DISPLAY "Birth date: " PPL-FS-BIRTH-DATE DISPLAY "Death date: " PPL-FS-DEATH-DATE MOVE 8 TO RETURN-CODE PERFORM Z100-CLEANUP END-IF.
This routine is far from perfect. It doesn't even take into consideration a different amount of days each month but sometimes, that's all you need in the program. Here we only ensure that the date is made out of numeric data and fits given time frame. An often misunderstood programming rule states that you should test for all possible error conditions. Following it, some programmers test for error conditions which will never happen, for example, because the input data is already tested for them. Let's assume that in this case, the date is saved in the input file is taken from DB2 column storing DATE data type. In such case, we don't need to test if the data is exactly correct, we know it is since DB2 checks if the date is in a correct format. If the column allows NULL values, we should only test if the field is empty. In this example, we use INTEGER-OF-DATE function. In COBOL Language Reference you can read: "YYYY represents the year in the Gregorian calendar. It must be an integer greater than 1600, but not greater than 9999." This means that the function will fail if the year is below 1600. DB2 doesn't ensure that, therefore the verification paragraph presented above is better than simply testing for empty string. Important: Notice that with the above test, we'll also catch the false data. For example, if an employee entered false birth-date (some date before 1900). Catching such incorrect data is not always desirable. Now a single employee who mistyped his birth date will abend our program, which may be an undesired behavior. Answers to the question "Should you also test the program for following conditions": ________________________________________ - The input data set is locked by another job. No. JES2, Initiator, and GRS will make our job wait until the data set is freed. ________________________________________ - The input data set is not sorted. No. The program is designed to work in batch with DFSORT pre-sort. If this step fails, the program won't even start. You're not responsible for incorrect job restarts and cannot test for every case of "misuse" of your programs. All you should do is to clearly document that pre-sort is a requirement for the program run. ________________________________________ - The birth date or death date is in incorrect format. It depends. In this case, the assumption is that the data came from DB2, therefore, we don't have to check the format. But in other cases, for example, if testing data entered directly by a user, you should make a detailed test. This is a very common test so there should be some ready-to-use module in your environment which will test the date format for you. ________________________________________ - The death date is earlier than the birth date. As mentioned earlier, testing for the correctness of user input depends on the program. The program which accepted the data into DB2, for example, some CICS transaction, should make this test and point that out in its documentation. Thanks to that, the programmers who use this data will know that this test was already performed in another program and will avoid wasting time on making the same test in their modules. If you're writing the program that accepts this data then yes, you should definitely test this condition and act appropriately. If your program is a CICS transaction, it can simply abend. If it creates some kind of a report, a warning may be a better choice. Is such case, one invalid record won't abend the entire program run. ________________________________________ - The birth date is older than 1600-01-01. Yes, the program uses function (INTEGER-TO-DATE) which works only if the data is between 1600 and 9999 year, so you must check that before running this function. ________________________________________ - The personal number is missing. The answer is the same as for "The death date is earlier than birth date". This should be checked by the program which accepted the data into DB2, not by our program which only creates the report. But this doesn't mean you can assume it was. It means you should check that. It's a typical example of "Know your data" principle. ________________________________________ - The is an error during age calculation. Generally, you should always consider errors in calculations. Incompatible data types, overflows, if any value can make the calculation go wild and so on. You should also test your calculation for all "special" values. So if you know that the variable value can vary from -1000 to 1000. You should test if the calculation is correct in at least 5 cases: -1000, -1, 0, 1, 1000. ________________________________________ - There is an I/O error during record read or write. Yes. You should always test for I/O errors. Missing files, empty files, invalid record key in case of VSAM files and so on. Fortunately, this is very easy since you can write a universal error handling procedure in "USE AFTER ERROR" clause in DECLARATIVES. ________________________________________ To sum it up, you must always test all possible execution paths of your program. You should also make all the needed tests for the input data, but not the ones that are unnecessary – this contradicts KISS principle and wastes a lot of programmer's time. So if you know that a particular test was done in another program, don't repeat it. If you know that the data has a correct format because it comes from DB2, don't test it. If you know that only specific values are possible here because, for example, web-form allows only such values, don't test for that as well. That's the basic rule, but remember that a lot depends on your program. If the program is very complex, you may want to perform some additional tests simply to check if the program logic works fine or that its calculations are correct. It's also a good habit to always code routine for abend handling which displays as much diagnostic information about the program as possible.
Solution 11
Rule 1: Always use the relatively new version of the COBOL compiler. "Relatively" because in mainframes many customers prefer to wait a few months to ensure there are no bugs in a new version and that it can be safely implemented in their site. But except that practice, you should make sure new compilers are used. COBOL language is being improved all the time and each new version brings some new functionalities as well as improvements in the old ones. You can also save some processing power. For example, recent improvements in Enterprise COBOL V6 speed up addition operation for PIC 9(18) item with TRUNC(STD) compiler option 45 times! ________________________________________ Rule 2: Always use the same name for PROGRAM-ID and member name. This is actually a requirement in some cases (sub-programs) but even if it's not, it's best to use the same name in both places. ________________________________________ Rule 3: Code INIT and CLEANUP paragraphs. Of course, the naming here doesn't matter, the purpose of those paragraphs do. In INIT you should make all the operations needed to be done at the beginning of the program. For example, open files, open cursors, update some special variables/register like SORT-MESSAGE etc. Also, remember to initialize all variable in sub-program using INIT paragraph instead of VALUE keyword. Unless, of course, you want to retain data values in between sub-program executions. Also, you can use the LOCAL-STORAGE section to make sure variables are reinitialized at each program execution. The purpose of CLEANUP is to release all resources used by the program, both in case of normal and abnormal termination. In case of abnormal, you should also display RC and some additional diagnostic information. ________________________________________ Rule 4: Use DECLARATIVES for file error handling. "USE AFTER ERROR" clause is the easiest way in which you can ensure your program handles file errors appropriately. ________________________________________ Rule 5: Always code condition handler. You should have a template for a universal abend handler and use it in all programs which do not require specific actions. Registering and unregistering abend handler is very easy and it can provide important diagnostic information regarding the error. More importantly, abend handler enables you to perform various cleanup activities even in case of a program abend. ________________________________________ Rule 6: Display DB2 statistics. This isn't important when it comes to program functionality, but can be helpful in error investigation. Such data is also very valuable for DBA searching for possible areas of improvement in DB2 performance. Such statistics should include the number of used cursors, number of SELECT/INSERT/DELETE statements, number of rows fetched and so on. ________________________________________ Rule 7: In case of error, display as much information as possible. Assuming that the data is not sensitive, it's a good habit to display as much data as possible when the program ends. For example, values of all variables that were used in the paragraph which ended in error. Values of special variables like SQLCODE. The number of loop iterations alongside data used in this iteration and so on. ________________________________________ Rule 8: Use templates for specific program types. Another time-saving habit is to have and maintain a set of templates for various program types, for example: - Batch + file processing. - Batch + DB2 - DB2 + CICS - IMS - Batch + DB2 + file processing. And also smaller templates which contain reusable code for more complex instruction. For example, for sorting with INPUT and OUTPUT PROCEDURE, using condition handler, multi-row fetch and so on. This way you'll have a tested and ready to use code which only needs to be copied and updated as needed. You'll save a lot of time and avoid a lot of errors. Also, be sure to keep in the template a standard comment section so you don't have to create it from the scratch as well. It's recommended that such templates and other copybooks are maintained on the team level and shared by all developers in the team. ________________________________________ Rule 9: Use DCLGENs and file definition copybooks. This is a programming standard everywhere. If your program creates a new file which may be used in other programs, you're responsible for creating and using copybook with the record definition for this file and keeping it in the appropriate library so others can use it as well. The same stands true for DCLGENs. In some shops, it's actually a requirement. Even if a file is used only in a single program, it must be defined in a copybook. ________________________________________ Rule 10: When using multiple IF/ELSE clauses test for the most probable condition first. This is especially important if you code IFs in loops. When you test for the most probable condition first, you lower the number of condition tests the program must do, which in turn, positively impacts program performance. ________________________________________ Rule 11: Use BINARY and PACKED-DECIMAL keywords. A quick reminder: - Integer number (2, 4, or 8 bytes depending on PIC) - BINARY = COMP = COMP-4 = COMP-5 - Zoned decimal number (as many bytes as defined in a PIC clause, excluding sign) – blank = DISPLAY - Packed decimal number (=CEELING(characters/2) bytes) – COMP-3 = PACKED-DECIMAL - Floating point number (4 bytes) – COMP-1 - Long floating point number (8 bytes) – COMP-2 To avoid unnecessary confusion with all COMPx variations, it's a good habit to use more meaningful names, so: - Integer – BINARY - Zoned decimal – blank - Packed decimal – PACKED-DECIMAL - Floating point – COMP-1 - Long floating point – COMP-2 ________________________________________ Rule 12: Always use ON SIZE ERROR. Whenever you do some calculation it's a good idea to code ON SIZE ERROR. Usually, it's better to abend the program than to let it work on incorrect data as it may happen in case of overflow during computation. ON SIZE ERROR clause will protect you from that. ________________________________________ Rule 13: Use conceptual data & time representation in your own programs. COBOL doesn't have the date or time variable types. Therefore, the date is always represented as either string or a number. Still, COBOL uses a few "conceptual types" so recommended date formats. Those types are used in date related intrinsic functions therefore if you have doubts about how to define date variable it's best to use one of those representations. Integer date format (INT): PIC 9(7) COMP. The date here is counted since 1601-01-01. So 1601-01-01 is represented as 1, 1601-02-01 as 32 and so on. Standard format (DATE): YYMMDD - PIC 9(6) YYYYMMDD - PIC 9(8) Julian format (DAY): YYDDD - PIC 9(5) YYYYDDD - PIC 9(7) DAY-OF-WEEK – PIC 9(1) 1 - Monday 2 - Tuesday 3 - Wednesday 4 - Thursday 5 - Friday 6 - Saturday 7 - Sunday TIME – HHMMSSXX – PIC 9(8) Where XX mean hundreds of a second. The exception to this rule is DB2 formats, YYYY-MM-DD" by default. If you're working on DB2 data and don't do any operations on a date it's best to use the format used in DB2. ________________________________________ In this Assignment, you've learned all kinds of good programming practices. Some of them are crucial such as KISS principle or the need for maintaining program documentation. Other depends on the site standards such as naming convention or the recommendation for input data verification. There are also those who depend more on personal preference, such as the way you indent code. At last, there are tons of recommendations not covered in this Assignment. We didn't cover COBOL performance, SQL performance, CICS, DB2, MQ and also more detailed recommendations regarding error-handling. So keep that in mind as well.
Working with DB2 – Part III – Transactional Processing
Introduction
Unlike most other database systems (including DB2 for LUW), DB2 on z/OS uses transactional processing implicitly. This means that whether you like it or not, all interactions with DB2 databases are transactions. Even SELECTs are COMMITted or ROLLBACKed, which, of course, doesn't influence the query in any way but illustrates this point nicely. Therefore, all SQL embedded in COBOL program is transactional. Transaction start when the first SQL is performed and ends after COMMIT or ROLLBACK which can be specified explicitly or issued automatically be DB2 at the end of UOW (Unit of Work). If SQL ends without error COMMIT is automatically issued, otherwise, UOW is rolled back. So the name of this Assignment is a little bit misleading. What we'll really learn here is how to think about your program as a transaction and how to manage multiple interdependent queries inside your program. We'll use the employee database created in "Loading a test database into DB2" to be able to work on more real-world scenarios. Also, programs in this Assignment use some of the good coding practices presented in the previous Assignment. So if you're wondering about naming convention or code formatting, feel free to check there.
Tasks
![]() 1. Write a program that read a sequential file which contains changes in employee job title and payment and on its basis updates DB2 records of an employee.
- The goal is to write a program which updates EMTBSLRY and EMTBTITL tables on the basis of such file.
- The file format is as follows: EMP NO, CHANGE DATE, PAYRISE VALUE (optional), NEW TITLE (optional).
- NEW TITLE and PAYRISE are optional. So it's possible that only the salary or only the job title changes. Of course, it also possible that both values change at the same time.
- In this Task, assume that the file always has a single record. So the program is supposed to be executed for each employee separately.
Test your program in at least the following cases:
- EMP_NO is not found.
- An employee is not hired at the moment.
- Payrise is actually a pay cut, so the earnings go down.
- New title matches the old one.
- Any field in the file has an incorrect format: INT for EMP NO, DATE for CHANGE DATE, INT for PAYRISE VALUE, and VARCHAR for NEW TITLE.
- There is a salary value below 10000 or above INT type boundary.
- PAYRISE VALUE is empty (In such case, update only EMTBTITL).
- NEW TITLE is empty (In such case, update only EMTBSLARY).
- Both of the above fields are empty (In such case, end the program in error).
- EMP NO or CHANGE DATE is empty.
- The program tries to update the record locked by another process.
- Another process tries to delete the record which was added by the program before COMMIT.
- Another process tries to update the record which was updated but not yet COMMITted by the program.
- Another process updates the EMTBTITL record when the processing of corresponding EMTBSLRY record already began but processing of EMTBTITL record hasn't started yet.
1. Write a program that read a sequential file which contains changes in employee job title and payment and on its basis updates DB2 records of an employee.
- The goal is to write a program which updates EMTBSLRY and EMTBTITL tables on the basis of such file.
- The file format is as follows: EMP NO, CHANGE DATE, PAYRISE VALUE (optional), NEW TITLE (optional).
- NEW TITLE and PAYRISE are optional. So it's possible that only the salary or only the job title changes. Of course, it also possible that both values change at the same time.
- In this Task, assume that the file always has a single record. So the program is supposed to be executed for each employee separately.
Test your program in at least the following cases:
- EMP_NO is not found.
- An employee is not hired at the moment.
- Payrise is actually a pay cut, so the earnings go down.
- New title matches the old one.
- Any field in the file has an incorrect format: INT for EMP NO, DATE for CHANGE DATE, INT for PAYRISE VALUE, and VARCHAR for NEW TITLE.
- There is a salary value below 10000 or above INT type boundary.
- PAYRISE VALUE is empty (In such case, update only EMTBTITL).
- NEW TITLE is empty (In such case, update only EMTBSLARY).
- Both of the above fields are empty (In such case, end the program in error).
- EMP NO or CHANGE DATE is empty.
- The program tries to update the record locked by another process.
- Another process tries to delete the record which was added by the program before COMMIT.
- Another process tries to update the record which was updated but not yet COMMITted by the program.
- Another process updates the EMTBTITL record when the processing of corresponding EMTBSLRY record already began but processing of EMTBTITL record hasn't started yet.
![]() 2. Modify the program from Task#1.
- This time assume that the file can store hundreds of records and the program updates all employees from the file at once.
- If any record contains any error, simply skip it, indicate the error in output and continue processing.
- Implement condition handler to ensure the program doesn't abend because of a corrupted record.
- Repeat the same tests as in Task#1.
2. Modify the program from Task#1.
- This time assume that the file can store hundreds of records and the program updates all employees from the file at once.
- If any record contains any error, simply skip it, indicate the error in output and continue processing.
- Implement condition handler to ensure the program doesn't abend because of a corrupted record.
- Repeat the same tests as in Task#1.
![]() 3. Write a program that checks the age of all employees in the 'Research' department.
- If an employee is older than 65 years and marked as still employed, change that. In other words, if an employee is older than 65 years and TO_DATE field in EMTBSLRY, EMTBTITL, or EMTBDPEM is equal to '9999-01-01' change those dates to date of his 66th birthday.
- Display all employees above 65 and indicate which of them needed to be updated. Also, display records which you are updating in EMTBSLRY, EMTBTITL, and EMTBDPEM tables.
- Use single-row fetch.
- Compare the performance of standard SELECT and SELECT FOR UPDATE statements.
3. Write a program that checks the age of all employees in the 'Research' department.
- If an employee is older than 65 years and marked as still employed, change that. In other words, if an employee is older than 65 years and TO_DATE field in EMTBSLRY, EMTBTITL, or EMTBDPEM is equal to '9999-01-01' change those dates to date of his 66th birthday.
- Display all employees above 65 and indicate which of them needed to be updated. Also, display records which you are updating in EMTBSLRY, EMTBTITL, and EMTBDPEM tables.
- Use single-row fetch.
- Compare the performance of standard SELECT and SELECT FOR UPDATE statements.
![]() 4. Write a program that anonymizes the data of all employees hired in 1988 (changes their names to 'XXX XXX' for example).
- Display EMP_NO and the name of each updated employee.
- Use Multi-row fetch.
- Compare the performance of standard SELECT and SELECT FOR UPDATE statements.
4. Write a program that anonymizes the data of all employees hired in 1988 (changes their names to 'XXX XXX' for example).
- Display EMP_NO and the name of each updated employee.
- Use Multi-row fetch.
- Compare the performance of standard SELECT and SELECT FOR UPDATE statements.
Solution 1
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1701. AUTHOR. JSADEK (MAINFRAMEPLAYGROUND@GMAL.COM) DATE-WRITTEN. 2018-10-12 *----------------------------------------------------------------- ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT PUP-FILE ASSIGN TO PUPFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS PUP-WT-FS. *----------------------------------------------------------------- DATA DIVISION. FILE SECTION. FD PUP-FILE. 01 PUP-FS. 05 PUP-FS-EMP-NO. 10 PUP-FZ-EMP-NO PIC S9(10). 05 FILLER PIC X. 05 PUP-FS-CHANGE-DATE. 10 PUP-FZ-CHANGE-DATE-YEAR PIC 9(4). 10 PUP-FT-CHANGE-DATE-SEP1 PIC X. 10 PUP-FZ-CHANGE-DATE-MONTH PIC 9(2). 10 PUP-FT-CHANGE-DATE-SEP2 PIC X. 10 PUP-FZ-CHANGE-DATE-DAY PIC 9(2). 05 FILLER PIC X. 05 PUP-FS-NEW-SALARY. 10 PUP-FZ-NEW-SALARY PIC S9(10). 05 FILLER PIC X. 05 PUP-FT-NEW-TITLE PIC X(50). *----------------------------------------------------------------- WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBSLRY END-EXEC. EXEC SQL INCLUDE EMTBTITL END-EXEC. 01 PUP-WT-FS PIC X(2). 01 PUP-WB-EOF PIC 9 VALUE 0. 01 PUP-WE-EMP-NO PIC Z(9)9. 01 PUP-WE-NEW-SALARY PIC Z(9)9. 01 PUP-WS-CHK-TITLE. 05 PUP-WB-CHK-TITLE PIC S9(4) COMP. 05 PUP-WT-CHK-TITLE PIC X(50). 01 WE-SQL-DISPLAY PIC -(8)9. 01 WT-ERROR-MSG PIC X(50) VALUE "X". 01 WT-UPDATE-MODE PIC X(4). 01 WT-TO-DATE-MARKER PIC X(10) VALUE '9999-01-01'. *----------------------------------------------------------------- PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON PUP-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'PUPFILE' STATUS: " PUP-WT-FS. DISPLAY "PROGRAM TERMINATES.". IF PUP-WT-FS NOT = "42" CLOSE PUP-FILE. STOP RUN. END DECLARATIVES. *----------------------------------------------------------------- MAIN-LOGIC. PERFORM INIT. PERFORM READ-PUP-FILE. PERFORM VERIFY-PUP-FILE. PERFORM DISPLAY-PUP-FILE. PERFORM UPDATE-DB2-RECORDS. PERFORM CLEANUP. *----------------------------------------------------------------- INIT. OPEN INPUT PUP-FILE. *----------------------------------------------------------------- READ-PUP-FILE. READ PUP-FILE AT END MOVE "FILE IS EMPTY" TO WT-ERROR-MSG PERFORM CLEANUP. READ PUP-FILE AT END MOVE 1 TO PUP-WB-EOF. IF PUP-WB-EOF = 1 MOVE "NO EMPLOYEE RECORD FOUND IN PUPFILE." TO WT-ERROR-MSG PERFORM CLEANUP END-IF. *----------------------------------------------------------------- VERIFY-PUP-FILE. COMPUTE PUP-FZ-EMP-NO = FUNCTION NUMVAL(PUP-FS-EMP-NO). IF PUP-FZ-EMP-NO < 1 OR PUP-FZ-EMP-NO > 2147483647 MOVE "INCORRECT EMP NO FORMAT" TO WT-ERROR-MSG PERFORM CLEANUP END-IF. IF PUP-FZ-CHANGE-DATE-YEAR < 1900 OR PUP-FZ-CHANGE-DATE-YEAR > 2400 OR PUP-FZ-CHANGE-DATE-MONTH < 1 OR PUP-FZ-CHANGE-DATE-MONTH > 12 OR PUP-FZ-CHANGE-DATE-DAY < 1 OR PUP-FZ-CHANGE-DATE-DAY > 31 OR PUP-FT-CHANGE-DATE-SEP1 NOT = "-" OR PUP-FT-CHANGE-DATE-SEP2 NOT = "-" MOVE "INCORRECT CHANGE DATE FORMAT" TO WT-ERROR-MSG PERFORM CLEANUP END-IF. IF PUP-FS-NEW-SALARY NOT = SPACES OR PUP-FT-NEW-TITLE NOT = SPACES IF PUP-FS-NEW-SALARY = SPACES MOVE "TITL" TO WT-UPDATE-MODE ELSE IF PUP-FT-NEW-TITLE = SPACES MOVE "SLRY" TO WT-UPDATE-MODE ELSE MOVE "BOTH" TO WT-UPDATE-MODE END-IF ELSE MOVE "MISSING SALARY AND TITLE VALUE" TO WT-ERROR-MSG PERFORM CLEANUP END-IF. IF WT-UPDATE-MODE = "BOTH" OR WT-UPDATE-MODE = "SLRY" COMPUTE PUP-FZ-NEW-SALARY = FUNCTION NUMVAL(PUP-FS-NEW-SALARY) IF PUP-FZ-NEW-SALARY < 10000 OR PUP-FZ-NEW-SALARY > 500000 MOVE "INCORRECT SALARY VALUE" TO WT-ERROR-MSG PERFORM CLEANUP END-IF END-IF. *----------------------------------------------------------------- DISPLAY-PUP-FILE. MOVE PUP-FZ-EMP-NO TO PUP-WE-EMP-NO. DISPLAY "EMP NO: " PUP-WE-EMP-NO. DISPLAY "CHANGE DATE: " PUP-FS-CHANGE-DATE. DISPLAY "UPDATE MODE: " WT-UPDATE-MODE. IF WT-UPDATE-MODE = 'BOTH' OR WT-UPDATE-MODE = 'TITL' DISPLAY "NEW TITLE: " PUP-FT-NEW-TITLE END-IF. IF WT-UPDATE-MODE = 'BOTH' OR WT-UPDATE-MODE = 'SLRY' MOVE PUP-FZ-NEW-SALARY TO PUP-WE-NEW-SALARY DISPLAY "NEW SALARY: " PUP-WE-NEW-SALARY END-IF. *----------------------------------------------------------------- UPDATE-DB2-RECORDS. MOVE PUP-FS-CHANGE-DATE TO SLRY-DT-TO-DATE TITL-DT-TO-DATE. IF WT-UPDATE-MODE = "BOTH" OR WT-UPDATE-MODE = "SLRY" COMPUTE SLRY-DB-EMP-NO = PUP-FZ-EMP-NO COMPUTE SLRY-DB-SALARY = PUP-FZ-NEW-SALARY PERFORM UPDATE-SLRY-TABLE END-IF. IF WT-UPDATE-MODE = "BOTH" OR WT-UPDATE-MODE = "TITL" COMPUTE TITL-DB-EMP-NO = PUP-FZ-EMP-NO MOVE PUP-FT-NEW-TITLE TO TITL-DT-TITLE MOVE 0 TO TITL-DB-TITLE INSPECT FUNCTION REVERSE(PUP-FT-NEW-TITLE) TALLYING TITL-DB-TITLE FOR LEADING SPACES COMPUTE TITL-DB-TITLE = LENGTH OF PUP-FT-NEW-TITLE - TITL-DB-TITLE PERFORM UPDATE-TITL-TABLE END-IF. *----------------------------------------------------------------- UPDATE-SLRY-TABLE. EXEC SQL UPDATE EMTBSLRY SET TO_DATE = :SLRY-DT-TO-DATE WHERE EMP_NO = :SLRY-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER END-EXEC IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE UPDATING AN OLD EMTBSLRY REC" PERFORM CHECK-SQL END-IF. EXEC SQL INSERT INTO EMTBSLRY VALUES ( :SLRY-DB-EMP-NO, :SLRY-DB-SALARY, :SLRY-DT-TO-DATE, :WT-TO-DATE-MARKER ) END-EXEC IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE INSERTING A NEW EMTBSLRY REC" PERFORM CHECK-SQL END-IF. *----------------------------------------------------------------- UPDATE-TITL-TABLE. EXEC SQL SELECT TITLE INTO :PUP-WT-CHK-TITLE FROM EMTBTITL WHERE EMP_NO = :TITL-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER END-EXEC IF SQLCODE NOT = 0 DISPLAY "SQL ERROR WHILE UPDATING AN OLD EMTBTITL REC" PERFORM CHECK-SQL END-IF. IF FUNCTION UPPER-CASE(PUP-WT-CHK-TITLE) = FUNCTION UPPER-CASE(PUP-FT-NEW-TITLE) MOVE "OLD AND NEW POSITION NAME ARE THE SAME" TO WT-ERROR-MSG PERFORM CLEANUP END-IF. EXEC SQL UPDATE EMTBTITL SET TO_DATE = :TITL-DT-TO-DATE WHERE EMP_NO = :TITL-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER END-EXEC IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE UPDATING AN OLD EMTBTITL REC" PERFORM CHECK-SQL END-IF. EXEC SQL INSERT INTO EMTBTITL VALUES ( :TITL-DB-EMP-NO, :TITL-DS-TITLE, :TITL-DT-TO-DATE, :WT-TO-DATE-MARKER ) END-EXEC IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE INSERTING A NEW EMTBTITL REC" PERFORM CHECK-SQL END-IF. *----------------------------------------------------------------- CHECK-SQL. MOVE SQLCODE TO WE-SQL-DISPLAY. DISPLAY "SQLCODE: " WE-SQL-DISPLAY. DISPLAY "SQLSTATE " SQLSTATE. MOVE SQLERRD(1) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(1): " WE-SQL-DISPLAY. MOVE SQLERRD(2) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(2): " WE-SQL-DISPLAY. MOVE SQLERRD(3) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(3): " WE-SQL-DISPLAY. MOVE SQLERRD(6) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(6): " WE-SQL-DISPLAY. EVALUATE TRUE WHEN SQLCODE = -911 OR SQLCODE = -913 MOVE "DEADLOCK OR TIMEOUT." TO WT-ERROR-MSG WHEN SQLCODE = -811 MOVE "MORE THAN 1 MATCHING ROW FOUND IN TITL TABLE." TO WT-ERROR-MSG WHEN SQLERRD(3) > 1 MOVE "MORE THAN 1 MATCHING ROW FOUND IN SLRY TABLE." TO WT-ERROR-MSG WHEN SQLCODE = 100 MOVE PUP-FZ-EMP-NO TO PUP-WE-EMP-NO STRING "EMPLOYEE: " PUP-WE-EMP-NO " NOT FOUND OR NOT HIRED." DELIMITED BY SIZE INTO WT-ERROR-MSG END-STRING WHEN OTHER MOVE "SQL ERROR." TO WT-ERROR-MSG END-EVALUATE. PERFORM CLEANUP. *----------------------------------------------------------------- CLEANUP. IF WT-ERROR-MSG NOT = "X" EXEC SQL ROLLBACK END-EXEC IF RETURN-CODE = 0 MOVE 16 TO RETURN-CODE END-IF DISPLAY "PROGRAM TERMINATES DUE TO AN ERROR." DISPLAY "RETURN CODE: " RETURN-CODE DISPLAY "ERROR MESSAGE: " WT-ERROR-MSG DISPLAY "INPUT FILE STATUS: " PUP-WT-FS ELSE DISPLAY "EMPLOYEE " PUP-WE-EMP-NO " UPDATED SUCCESSFULLY." EXEC SQL COMMIT END-EXEC END-IF. CLOSE PUP-FILE. STOP RUN. *-----------------------------------------------------------------
Comments: - To be able to reference EMP NO and NEW SALARY variables both as text and the zoned-decimal number we've used a known trick with using a structure instead of REDEFINING item. Thanks to that we could use the same variable as both an argument and the receiving item of NUMVAL function. - NUMVAL function abends when receiving data which cannot be converted to a numeric. This is usually a serious error and abends are often acceptable in such cases. In other cases, you must code condition handler to either execute some cleanup activities or to simply skip the problematic record and continue further processing. - Notice that we check employee records with TO_DATE = '9999-01-01' this will extract only currently hired employee. That's ok, but now one condition "no record found" indicates two types of errors "no employee in the database" and "employee is no longer hired". This is ok, it's better to have such ambiguous error than to unnecessarily code an additional subquery which checks that and slows down the program. Below you can see various test cases. As a programmer, your responsibility is to check all execution paths of your program. Sure, later the code will be checked by testing teams but basic execution flow tests as the one listed below are done by the programmer. File related tests: - EMP NO = -100 - ERROR MESSAGE: INCORRECT EMP NO FORMAT - EMP NO = 0 - ERROR MESSAGE: INCORRECT EMP NO FORMAT - EMP NO contains a letter - Abend - EMP NO is missing - Abend - CHANGE DATE is missing - ERROR MESSAGE: INCORRECT CHANGE DATE FORMAT - CHANGE DATE month is 13 - ERROR MESSAGE: INCORRECT CHANGE DATE FORMAT - CHANGE DATE contains a letter - ERROR MESSAGE: INCORRECT CHANGE DATE FORMAT - CHANGE DATE '-' separator is missing - ERROR MESSAGE: INCORRECT CHANGE DATE FORMAT - NEW SALARY is missing - UPDATE MODE: TITL - NEW SALARY contain a letter - Abend - NEW SALARY value = -1 - ERROR MESSAGE: INCORRECT SALARY VALUE - NEW SALARY and NEW TITLE is missing - ERROR MESSAGE: MISSING SALARY AND TITLE VALUE - NEW TITLE is missing - UPDATE MODE: SLRY - The file is empty - ERROR MESSAGE: FILE IS EMPTY - No employee record found in the file - ERROR MESSAGE: NO EMPLOYEE RECORD FOUND IN PUPFILE. DB2 related tests: - EMP-NO does not exist - ERROR MESSAGE: EMPLOYEE: 300 NOT FOUND OR NOT HIRED. - EMP-NO is not currently hired (EMTBSLRY.TO_DATE is different than '9999-01-01') - ERROR MESSAGE: EMPLOYEE: 110000 NOT FOUND OR NOT HIRED. - EMP-NO is not currently hired (EMTBTITL.TO_DATE is different than '9999-01-01') - ERROR MESSAGE: EMPLOYEE: 110000 NOT FOUND OR NOT HIRED. - There is more than 1 row with '9999-01-01' TO_DATE in EMTBSLRY table - ERROR MESSAGE: MORE THAN 1 MATCHING ROW FOUND IN SLRY TABLE. - There is more than 1 row with '9999-01-01' TO_DATE in EMTBTITL table - ERROR MESSAGE: MORE THAN 1 MATCHING ROW FOUND IN TITL TABLE. - Payrise is actually a paycut, so the earnings go down - Correct program execution. - Old and new compensation is the same - Correct program execution. - New title matches the old one - ERROR MESSAGE: OLD AND NEW POSITION NAME ARE THE SAME - The program tries to update the record blocked by another process – ERROR MESSAGE: DEADLOCK OR TIMEOUT. - Another process tries to delete the record which was added to the program before COMMIT – Timeout of the conflicting process. - Another process tries to update the record which was updated but not yet COMMITed by the program – Timeout of the conflicting process. - Another process updates the EMTBTITL record when the processing of corresponding EMTBSLRY record already began but processing of EMTBTITL record hasn't started yet – Changes to both tables are COMMITted at the same time. If any other transaction updates EMTBTITL in the moment between EMTBSLRY and EMTBTITL processing, the second query will end in some error. For example, a record not found or more than 1 record match the update criteria and the entire transaction will be rolled back.
Solution 2
Main program:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1702. AUTHOR. JSADEK (MAINFRAMEPLAYGROUND@GMAL.COM) DATE-WRITTEN. 2018-10-12 *----------------------------------------------------------------- ENVIRONMENT DIVISION. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT PUP-FILE ASSIGN TO PUPFILE ORGANIZATION IS SEQUENTIAL FILE STATUS IS PUP-WT-FS. *----------------------------------------------------------------- DATA DIVISION. FILE SECTION. FD PUP-FILE. 01 PUP-FS. 05 PUP-FS-EMP-NO. 10 PUP-FZ-EMP-NO PIC S9(10). 05 FILLER PIC X. 05 PUP-FS-CHANGE-DATE. 10 PUP-FZ-CHANGE-DATE-YEAR PIC 9(4). 10 PUP-FT-CHANGE-DATE-SEP1 PIC X. 10 PUP-FZ-CHANGE-DATE-MONTH PIC 9(2). 10 PUP-FT-CHANGE-DATE-SEP2 PIC X. 10 PUP-FZ-CHANGE-DATE-DAY PIC 9(2). 05 FILLER PIC X. 05 PUP-FS-NEW-SALARY. 10 PUP-FZ-NEW-SALARY PIC S9(10). 05 FILLER PIC X. 05 PUP-FT-NEW-TITLE PIC X(50). *----------------------------------------------------------------- WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBSLRY END-EXEC. EXEC SQL INCLUDE EMTBTITL END-EXEC. 01 PUP-WT-FS PIC X(2). 01 PUP-WB-EOF PIC 9 VALUE 0. 01 PUP-WE-EMP-NO PIC -(9)9. 01 PUP-WE-NEW-SALARY PIC Z(9)9. 01 PUP-WS-CHK-TITLE. 05 PUP-WB-CHK-TITLE PIC S9(4) COMP. 05 PUP-WT-CHK-TITLE PIC X(50). 01 WE-SQL-DISPLAY PIC -(8)9. 01 WT-ERROR-MSG PIC X(50) VALUE "X". 01 WT-UPDATE-MODE PIC X(4). 01 WT-TO-DATE-MARKER PIC X(10) VALUE '9999-01-01'. 01 WB-SKIP-REC PIC 9 COMP. 01 WZ-REC-NUM PIC 9(6). 01 CEEHDLR PIC X(8) VALUE "CEEHDLR". 01 CEEHDLU PIC X(8) VALUE "CEEHDLU". 01 CEE3SRP PIC X(8) VALUE "CEE3SRP". 01 ABN-WP-ROUTINE PROCEDURE-POINTER. 01 ABN-WP-TOKEN POINTER. 01 ABN-WS-FEEDBACK. 05 ABN-WS-COND-TOKEN. 10 ABN-WS-CASE1. 15 ABN-WB-SEV PIC S9(4) COMP. 15 ABN-WB-MSGNO PIC S9(4) COMP. 10 ABN-WS-CASE2 REDEFINES ABN-WS-CASE1. 15 ABN-WB-CLASS-CODE PIC S9(4) COMP. 15 ABN-WB-CAUSE-CODE PIC S9(4) COMP. 10 ABN-WT-FLGS PIC X(1). 10 ABN-WT-FACID PIC X(3). 05 ABN-WT-ISI PIC X(4). 01 ABN-WS-COMM-AREA. 05 ABN-WP-RESUME-POINT POINTER. 05 ABN-WZ-INVREC-FLAG PIC 9. 01 XX PIC X. *----------------------------------------------------------------- PROCEDURE DIVISION. DECLARATIVES. FILE-ERRORS SECTION. USE AFTER ERROR PROCEDURE ON PUP-FILE. FILE-ERROR. DISPLAY "FILE ERROR OCCUREED:". DISPLAY "'PUPFILE' STATUS: " PUP-WT-FS. DISPLAY "PROGRAM TERMINATES.". IF PUP-WT-FS NOT = "42" CLOSE PUP-FILE. STOP RUN. END DECLARATIVES. *----------------------------------------------------------------- MAIN-LOGIC. PERFORM INIT. PERFORM READ-PUP-FILE. PERFORM CLEANUP. *----------------------------------------------------------------- INIT. OPEN INPUT PUP-FILE. SET ABN-WP-ROUTINE TO ENTRY "MP1702AB". SET ABN-WP-TOKEN TO ADDRESS OF ABN-WS-COMM-AREA. CALL CEEHDLR USING ABN-WP-ROUTINE ABN-WP-TOKEN ABN-WS-FEEDBACK. IF ABN-WS-FEEDBACK NOT = LOW-VALUES DISPLAY "CEEHDLR FAILED." DISPLAY "MSG NO: " ABN-WT-FACID ABN-WB-MSGNO STOP RUN END-IF. *----------------------------------------------------------------- READ-PUP-FILE. READ PUP-FILE AT END MOVE "FILE IS EMPTY" TO WT-ERROR-MSG PERFORM CLEANUP. READ PUP-FILE AT END MOVE 1 TO PUP-WB-EOF. IF PUP-WB-EOF = 1 MOVE "NO EMPLOYEE RECORD FOUND IN PUPFILE." TO WT-ERROR-MSG PERFORM CLEANUP END-IF. PERFORM VARYING WZ-REC-NUM FROM 1 BY 1 UNTIL PUP-WB-EOF = 1 DISPLAY "PROCESSING RECORD " WZ-REC-NUM PERFORM RESET-VARIABLES PERFORM VERIFY-RECORD IF WB-SKIP-REC = 0 PERFORM UPDATE-DB2-RECORD END-IF CALL CEE3SRP USING ABN-WP-RESUME-POINT ABN-WS-FEEDBACK SERVICE LABEL PERFORM VERIFY-RESUME-POINT READ PUP-FILE AT END MOVE 1 TO PUP-WB-EOF END-READ END-PERFORM. *----------------------------------------------------------------- RESET-VARIABLES. MOVE 0 TO ABN-WZ-INVREC-FLAG. MOVE 0 TO WB-SKIP-REC. INITIALIZE TITL-DS. INITIALIZE SLRY-DS. INITIALIZE WT-UPDATE-MODE. MOVE "X" TO WT-ERROR-MSG. *----------------------------------------------------------------- VERIFY-RESUME-POINT. IF ABN-WZ-INVREC-FLAG = 1 IF ABN-WS-FEEDBACK NOT = LOW-VALUES DISPLAY "FAILED TO SET RESUME POINT" DISPLAY "ERROR: " ABN-WT-FACID ABN-WB-MSGNO STOP RUN END-IF DISPLAY "RECORD THAT CAUSED ABEND: " PUP-FS DISPLAY "-------------------------------------------------" DISPLAY "." DISPLAY "." END-IF. *----------------------------------------------------------------- VERIFY-RECORD. PERFORM VERIFY-EMP-NO. IF WB-SKIP-REC = 0 PERFORM VERIFY-CHANGE-DATE. IF WB-SKIP-REC = 0 PERFORM VERIFY-UPDATE-1. IF WB-SKIP-REC = 0 PERFORM VERIFY-UPDATE-2. *----------------------------------------------------------------- VERIFY-EMP-NO. COMPUTE PUP-FZ-EMP-NO = FUNCTION NUMVAL(PUP-FS-EMP-NO). IF PUP-FZ-EMP-NO < 1 OR PUP-FZ-EMP-NO > 2147483647 MOVE "INCORRECT EMP NO FORMAT" TO WT-ERROR-MSG PERFORM SKIP-RECORD END-IF. MOVE PUP-FZ-EMP-NO TO PUP-WE-EMP-NO. *----------------------------------------------------------------- VERIFY-CHANGE-DATE. IF PUP-FZ-CHANGE-DATE-YEAR < 1900 OR PUP-FZ-CHANGE-DATE-YEAR > 2400 OR PUP-FZ-CHANGE-DATE-MONTH < 1 OR PUP-FZ-CHANGE-DATE-MONTH > 12 OR PUP-FZ-CHANGE-DATE-DAY < 1 OR PUP-FZ-CHANGE-DATE-DAY > 31 OR PUP-FT-CHANGE-DATE-SEP1 NOT = "-" OR PUP-FT-CHANGE-DATE-SEP2 NOT = "-" MOVE "INCORRECT CHANGE DATE FORMAT" TO WT-ERROR-MSG PERFORM SKIP-RECORD END-IF. *----------------------------------------------------------------- VERIFY-UPDATE-1. IF PUP-FS-NEW-SALARY NOT = SPACES OR PUP-FT-NEW-TITLE NOT = SPACES IF PUP-FS-NEW-SALARY = SPACES MOVE "TITL" TO WT-UPDATE-MODE ELSE IF PUP-FT-NEW-TITLE = SPACES MOVE "SLRY" TO WT-UPDATE-MODE ELSE MOVE "BOTH" TO WT-UPDATE-MODE END-IF ELSE MOVE "MISSING SALARY AND TITLE VALUE" TO WT-ERROR-MSG PERFORM SKIP-RECORD END-IF. *----------------------------------------------------------------- VERIFY-UPDATE-2. IF WT-UPDATE-MODE = "BOTH" OR WT-UPDATE-MODE = "SLRY" COMPUTE PUP-FZ-NEW-SALARY = FUNCTION NUMVAL(PUP-FS-NEW-SALARY) IF PUP-FZ-NEW-SALARY < 10000 OR PUP-FZ-NEW-SALARY > 500000 MOVE "INCORRECT SALARY VALUE" TO WT-ERROR-MSG PERFORM SKIP-RECORD END-IF END-IF. *----------------------------------------------------------------- UPDATE-DB2-RECORD. MOVE PUP-FS-CHANGE-DATE TO SLRY-DT-TO-DATE TITL-DT-TO-DATE. IF WT-UPDATE-MODE = "BOTH" OR WT-UPDATE-MODE = "SLRY" COMPUTE SLRY-DB-EMP-NO = PUP-FZ-EMP-NO COMPUTE SLRY-DB-SALARY = PUP-FZ-NEW-SALARY PERFORM UPDATE-SLRY-TABLE END-IF. IF WT-UPDATE-MODE = "BOTH" OR WT-UPDATE-MODE = "TITL" COMPUTE TITL-DB-EMP-NO = PUP-FZ-EMP-NO MOVE PUP-FT-NEW-TITLE TO TITL-DT-TITLE MOVE 0 TO TITL-DB-TITLE INSPECT FUNCTION REVERSE(PUP-FT-NEW-TITLE) TALLYING TITL-DB-TITLE FOR LEADING SPACES COMPUTE TITL-DB-TITLE = LENGTH OF PUP-FT-NEW-TITLE - TITL-DB-TITLE PERFORM UPDATE-TITL-TABLE END-IF. IF WB-SKIP-REC = 0 EXEC SQL ROLLBACK END-EXEC DISPLAY "-------------------------------------------------" DISPLAY "EMPLOYEE: " PUP-WE-EMP-NO " UDPATED SUCCESSFULLY" DISPLAY "-------------------------------------------------" DISPLAY "." DISPLAY "." END-IF. *----------------------------------------------------------------- UPDATE-SLRY-TABLE. EXEC SQL UPDATE EMTBSLRY SET TO_DATE = :SLRY-DT-TO-DATE WHERE EMP_NO = :SLRY-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER END-EXEC. IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE UPDATING AN OLD EMTBSLRY REC" PERFORM SQL-ERROR END-IF. IF WB-SKIP-REC = 0 EXEC SQL INSERT INTO EMTBSLRY VALUES ( :SLRY-DB-EMP-NO, :SLRY-DB-SALARY, :SLRY-DT-TO-DATE, :WT-TO-DATE-MARKER ) END-EXEC IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE INSERTING A NEW EMTBSLRY REC" PERFORM SQL-ERROR END-IF END-IF. *----------------------------------------------------------------- UPDATE-TITL-TABLE. IF WB-SKIP-REC = 0 EXEC SQL SELECT TITLE INTO :PUP-WT-CHK-TITLE FROM EMTBTITL WHERE EMP_NO = :TITL-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER END-EXEC IF SQLCODE NOT = 0 DISPLAY "SQL ERROR WHILE UPDATING AN OLD EMTBTITL REC" PERFORM SQL-ERROR END-IF END-IF IF FUNCTION UPPER-CASE(PUP-WT-CHK-TITLE) = FUNCTION UPPER-CASE(PUP-FT-NEW-TITLE) AND WB-SKIP-REC = 0 MOVE "OLD AND NEW POSITION NAME ARE THE SAME" TO WT-ERROR-MSG PERFORM SKIP-RECORD END-IF. IF WB-SKIP-REC = 0 EXEC SQL UPDATE EMTBTITL SET TO_DATE = :TITL-DT-TO-DATE WHERE EMP_NO = :TITL-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER END-EXEC IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE UPDATING AN OLD EMTBTITL REC" PERFORM SQL-ERROR END-IF END-IF. IF WB-SKIP-REC = 0 EXEC SQL INSERT INTO EMTBTITL VALUES ( :TITL-DB-EMP-NO, :TITL-DS-TITLE, :TITL-DT-TO-DATE, :WT-TO-DATE-MARKER ) END-EXEC IF SQLCODE NOT = 0 OR SQLERRD(3) NOT = 1 DISPLAY "SQL ERROR WHILE INSERTING A NEW EMTBTITL REC" PERFORM SQL-ERROR END-IF END-IF. *----------------------------------------------------------------- SQL-ERROR. DISPLAY "-------------------------------------------------". MOVE SQLCODE TO WE-SQL-DISPLAY. DISPLAY "SQLCODE: " WE-SQL-DISPLAY. DISPLAY "SQLSTATE " SQLSTATE. MOVE SQLERRD(1) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(1): " WE-SQL-DISPLAY. MOVE SQLERRD(2) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(2): " WE-SQL-DISPLAY. MOVE SQLERRD(3) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(3): " WE-SQL-DISPLAY. MOVE SQLERRD(6) TO WE-SQL-DISPLAY. DISPLAY "SQLERRD(6): " WE-SQL-DISPLAY. EVALUATE TRUE WHEN SQLCODE = -911 OR SQLCODE = -913 MOVE "DEADLOCK OR TIMEOUT." TO WT-ERROR-MSG WHEN SQLCODE = -811 MOVE "MORE THAN 1 MATCHING ROW FOUND IN TITL TABLE." TO WT-ERROR-MSG WHEN SQLERRD(3) > 1 AND SQLCODE = 0 MOVE "MORE THAN 1 MATCHING ROW FOUND IN SLRY TABLE." TO WT-ERROR-MSG WHEN SQLCODE = 100 MOVE PUP-FZ-EMP-NO TO PUP-WE-EMP-NO STRING "EMPLOYEE: " PUP-WE-EMP-NO " NOT FOUND OR NOT HIRED." DELIMITED BY SIZE INTO WT-ERROR-MSG END-STRING WHEN OTHER MOVE "SQL ERROR." TO WT-ERROR-MSG END-EVALUATE. PERFORM SKIP-RECORD. *----------------------------------------------------------------- SKIP-RECORD. EXEC SQL ROLLBACK END-EXEC DISPLAY "-------------------------------------------------". DISPLAY "ERROR WHILE PROCESSING EMPLOYEE WITH NO: " PUP-WE-EMP-NO. DISPLAY "ERROR MESSAGE: " WT-ERROR-MSG. DISPLAY "UPDATE MODE: " WT-UPDATE-MODE. DISPLAY "FULL RECORD: " PUP-FS. DISPLAY "-------------------------------------------------". DISPLAY ".". DISPLAY ".". MOVE 1 TO WB-SKIP-REC. MOVE "X" TO WT-ERROR-MSG. *----------------------------------------------------------------- CLEANUP. IF WT-ERROR-MSG NOT = "X" IF RETURN-CODE = 0 MOVE 16 TO RETURN-CODE END-IF DISPLAY "PROGRAM TERMINATES DUE TO AN ERROR." DISPLAY "RETURN CODE: " RETURN-CODE DISPLAY "ERROR MESSAGE: " WT-ERROR-MSG DISPLAY "INPUT FILE STATUS: " PUP-WT-FS ELSE DISPLAY "PROCESSING COMPLETED." END-IF. CLOSE PUP-FILE. CALL CEEHDLU USING ABN-WP-ROUTINE ABN-WP-TOKEN ABN-WS-FEEDBACK. IF ABN-WS-FEEDBACK NOT = LOW-VALUES DISPLAY "CEEHDLR FAILED." DISPLAY "MSG NO: " ABN-WT-FACID ABN-WB-MSGNO STOP RUN END-IF. STOP RUN. *-----------------------------------------------------------------
Condition handler:
//JSADEK01 JOB NOTIFY=&SYSUID,REGION=0M,LINES=(10,CANCEL),COND=(0,NE) //RUNCOBOL EXEC IGYWCL //COBOL.STEPLIB DD DISP=SHR,DSN=IGY410.SIGYCOMP //LKED.SYSLMOD DD DISP=SHR,DSN=&SYSUID..MY.COBOL.LINKLIB(MP1702AB) //COBOL.SYSIN DD * IDENTIFICATION DIVISION. PROGRAM-ID. MP1702AB. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. 01 CEEMRCE PIC X(8) VALUE "CEEMRCE ". 01 ABN-WT-FEEDBACK PIC X(12). LINKAGE SECTION. 01 ABN-LP-TOKEN POINTER. 01 ABN-LB-RESULT PIC S9(9) COMP. 88 ABN-LC-RESUME VALUE 10. 88 ABN-LC-PERCOLATE VALUE 20. 88 ABN-LC-PERCOLATE-SF VALUE 21. 88 ABN-LC-PROMOTE VALUE 30. 88 ABN-LC-PROMOTE-SF VALUE 31. 01 ABN-LS-FEEDBACK. 05 ABN-LS-COND-TOKEN. 10 ABN-LS-CASE1. 15 ABN-LB-SEV PIC S9(4) COMP. 15 ABN-LB-MSGNO PIC S9(4) COMP. 10 ABN-LS-CASE2 REDEFINES ABN-LS-CASE1. 15 ABN-LB-CLASS-CODE PIC S9(4) COMP. 15 ABN-LB-CAUSE-CODE PIC S9(4) COMP. 10 ABN-LT-FLGS PIC X(1). 10 ABN-LT-FACID PIC X(3). 05 ABN-LT-ISI PIC X(4). 01 ABN-LS-COMM-AREA. 05 ABN-LP-RESUME-POINT POINTER. 05 ABN-LZ-INVREC-FLAG PIC 9. PROCEDURE DIVISION USING ABN-LS-FEEDBACK ABN-LP-TOKEN ABN-LB-RESULT. MAIN-LOGIC. SET ADDRESS OF ABN-LS-COMM-AREA TO ABN-LP-TOKEN. MOVE 1 TO ABN-LZ-INVREC-FLAG. DISPLAY "-------------------------------------------------". DISPLAY "COND HANDLER: " ABN-LT-FACID ABN-LB-MSGNO " ABEND CAUGHT. TRYING TO RESUME.". CALL CEEMRCE USING ABN-LP-RESUME-POINT ABN-WT-FEEDBACK. IF ABN-WT-FEEDBACK = LOW-VALUES DISPLAY "COND HANDLER: PROGRAM RESUMED TO: " ABN-LP-RESUME-POINT " BLOCK." SET ABN-LC-RESUME TO TRUE GOBACK ELSE DISPLAY "COND HANDLER: PROGRAM RESUME UNSUCCESSFUL." STOP RUN END-IF.
Output & Tests:
PROCESSING RECORD 000001 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: ERROR MESSAGE: INCORRECT EMP NO FORMAT UPDATE MODE: FULL RECORD: 000000010};2018-11-30; 60000;Engineer ------------------------------------------------- . . PROCESSING RECORD 000002 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: -100 ERROR MESSAGE: INCORRECT EMP NO FORMAT UPDATE MODE: FULL RECORD: 000000000{;2018-09-02; 60000;Engineer ------------------------------------------------- . . PROCESSING RECORD 000003 ------------------------------------------------- COND HANDLER: IGZ0097 ABEND CAUGHT. TRYING TO RESUME. COND HANDLER: PROGRAM RESUMED TO: 0509638944 BLOCK. RECORD THAT CAUSED ABEND: XYZ;2018-09-02; 60000;Engineer ------------------------------------------------- . . PROCESSING RECORD 000004 ------------------------------------------------- COND HANDLER: IGZ0097 ABEND CAUGHT. TRYING TO RESUME. COND HANDLER: PROGRAM RESUMED TO: 0509638944 BLOCK. RECORD THAT CAUSED ABEND: ;2018-09-02; 60000;Engineer ------------------------------------------------- . . PROCESSING RECORD 000005 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: INCORRECT CHANGE DATE FORMAT UPDATE MODE: FULL RECORD: 000011000{; ; 60000;Engineer ------------------------------------------------- . . PROCESSING RECORD 000006 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: INCORRECT CHANGE DATE FORMAT UPDATE MODE: FULL RECORD: 000011000{;2018-13-33; 60000;Engineer ------------------------------------------------- . . PROCESSING RECORD 000007 SQL ERROR WHILE UPDATING AN OLD EMTBSLRY REC ------------------------------------------------- SQLCODE: -180 SQLSTATE 22007 SQLERRD(1): -6805 SQLERRD(2): 0 SQLERRD(3): 0 SQLERRD(6): 0 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: SQL ERROR. UPDATE MODE: BOTH FULL RECORD: 000011000{;20D8-12-30;000006000{;Engineer ------------------------------------------------- . . PROCESSING RECORD 000008 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: INCORRECT CHANGE DATE FORMAT UPDATE MODE: FULL RECORD: 000011000{;20D8312-30; 60000;Engineer ------------------------------------------------- . . PROCESSING RECORD 000009 SQL ERROR WHILE UPDATING AN OLD EMTBTITL REC ------------------------------------------------- SQLCODE: -811 SQLSTATE 21000 SQLERRD(1): -140 SQLERRD(2): 0 SQLERRD(3): 0 SQLERRD(6): 0 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: MORE THAN 1 MATCHING ROW FOUND IN TITL TABLE. UPDATE MODE: TITL FULL RECORD: 000011000{;2018-12-30; ;Engineer ------------------------------------------------- . . PROCESSING RECORD 000010 ------------------------------------------------- COND HANDLER: IGZ0097 ABEND CAUGHT. TRYING TO RESUME. COND HANDLER: PROGRAM RESUMED TO: 0509641728 BLOCK. RECORD THAT CAUSED ABEND: 000011000{;2018-12-30; o_O ;Engineer ------------------------------------------------- . . PROCESSING RECORD 000011 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: INCORRECT SALARY VALUE UPDATE MODE: BOTH FULL RECORD: 000011000{;2018-12-30;000000000J;Engineer ------------------------------------------------- . . PROCESSING RECORD 000012 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: MISSING SALARY AND TITLE VALUE UPDATE MODE: FULL RECORD: 000011000{;2018-12-30; ; ------------------------------------------------- . . PROCESSING RECORD 000013 SQL ERROR WHILE UPDATING AN OLD EMTBSLRY REC ------------------------------------------------- SQLCODE: 0 SQLSTATE 00000 SQLERRD(1): 0 SQLERRD(2): 0 SQLERRD(3): 2 SQLERRD(6): 0 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 110000 ERROR MESSAGE: MORE THAN 1 MATCHING ROW FOUND IN SLRY TABLE. UPDATE MODE: SLRY FULL RECORD: 000011000{;2018-12-30;000006000{; ------------------------------------------------- . . PROCESSING RECORD 000014 SQL ERROR WHILE UPDATING AN OLD EMTBSLRY REC ------------------------------------------------- SQLCODE: 100 SQLSTATE 02000 SQLERRD(1): -110 SQLERRD(2): 0 SQLERRD(3): 0 SQLERRD(6): 0 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 321 ERROR MESSAGE: EMPLOYEE: 321 NOT FOUND OR NOT HIRED. UPDATE MODE: BOTH FULL RECORD: 000000032A;2018-09-30;000006000{;Engineer ------------------------------------------------- . . PROCESSING RECORD 000015 SQL ERROR WHILE UPDATING AN OLD EMTBTITL REC ------------------------------------------------- SQLCODE: 100 SQLSTATE 02000 SQLERRD(1): -110 SQLERRD(2): 0 SQLERRD(3): 0 SQLERRD(6): 0 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 10008 ERROR MESSAGE: EMPLOYEE: 10008 NOT FOUND OR NOT HIRED. UPDATE MODE: TITL FULL RECORD: 000001000H;2018-10-05; ;Engineer ------------------------------------------------- . . PROCESSING RECORD 000016 ------------------------------------------------- COND HANDLER: IGZ0097 ABEND CAUGHT. TRYING TO RESUME. COND HANDLER: PROGRAM RESUMED TO: 0509644328 BLOCK. RECORD THAT CAUSED ABEND: ;E ------------------------------------------------- . . PROCESSING RECORD 000017 SQL ERROR WHILE UPDATING AN OLD EMTBSLRY REC ------------------------------------------------- SQLCODE: 100 SQLSTATE 02000 SQLERRD(1): -110 SQLERRD(2): 0 SQLERRD(3): 0 SQLERRD(6): 0 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 10008 ERROR MESSAGE: EMPLOYEE: 10008 NOT FOUND OR NOT HIRED. UPDATE MODE: SLRY FULL RECORD: 000001000H;2018-10-05;000004200{; ------------------------------------------------- . . PROCESSING RECORD 000018 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 10007 ERROR MESSAGE: OLD AND NEW POSITION NAME ARE THE SAME UPDATE MODE: TITL FULL RECORD: 000001000G;2018-10-11; ;Senior Staff ------------------------------------------------- . . PROCESSING RECORD 000019 ------------------------------------------------- EMPLOYEE: 10007 UDPATED SUCCESSFULLY ------------------------------------------------- . . PROCESSING RECORD 000020 ------------------------------------------------- EMPLOYEE: 10007 UDPATED SUCCESSFULLY ------------------------------------------------- . . PROCESSING RECORD 000021 SQL ERROR WHILE UPDATING AN OLD EMTBSLRY REC ------------------------------------------------- SQLCODE: -911 SQLSTATE 40001 SQLERRD(1): -190 SQLERRD(2): 13172746 SQLERRD(3): 13172878 SQLERRD(6): 36870912 ------------------------------------------------- ERROR WHILE PROCESSING EMPLOYEE WITH NO: 200000 ERROR MESSAGE: DEADLOCK OR TIMEOUT. UPDATE MODE: BOTH FULL RECORD: 000020000{;2018-10-08;000022222B;Whatever ------------------------------------------------- . . PROCESSING COMPLETED.
DB2 related comments: - This is a good example of how big code modifications troublesome can be. They can be nearly as time consuming as writing a new program. This is just another reason why you should always focus on the design phase, and be sure you gather all the details regarding program functionality before starting coding. - The important thing in this program is where you issue COMMIT and ROLLBACK. Each input record is a separate transaction, therefore, it shouldn't influence in any way processing of other records. The only correct way to code such a program is to issue COMMIT/ROLLBACK at the end of processing of a single record. This way even if a subsequent record is corrupted the previous changes will be applied. - Also, issuing COMMIT for each record minimizes the time program keeps locks on the updated records. - In SQL-ERROR paragraph you can see how to easily code EVALUATE statement which tests for error conditions in all SQL statements used in your program. Condition handler related comments: You can also see here the simplest Condition Handler that catches all types of abends. No matter what's the abend the program will skip the record and resume processing from the next record. The basic condition handler requires only two CLE (Common Language Environment) services: CEEHDLR & CEEHDLU. In such case, the program flow goes like that: MAIN PROGRAM ---> ROUTINE & TOKEN & FEEDBACK variables ---> CLE ---> FEEDBACK ; TOKEN ; RESULT variables ---> CONDITION HANDLER Where: - ROUTINE - Name of the load module which serves as a condition handler. - TOKEN - Integer variable which can be used in any way you want. You can use it as a POINTER to any structure in the main program and by that define an additional set of variables shared by the main program and the condition handler. - FEEDBACK - a structure containing the response from CLE service. - RESULT - This is a flag shared between CLE and condition handler which indicates which action CLE should take in response to the abend. In here, we use it to indicate that the main program should be resumed. When you want your program to resume from a specific point, you also need to use CEE3SRP & CEEMRCE. The pointer to the resume point must be passed directly to the handler: MAIN PROGRAM ---> RESUME POINT (set by CEE3SRP) ---> CONDITION HANDLER ---> RESUME POINT ---> CEEMRCE service In the Task#5 of "Error Handling" Assignment, you can see that the structure containing RESUME POINT and additional user variable is passed between programs with the use of the EXTERNAL keyword. Here you can see a more elegant way to do the same thing: In the main program you define TOKEN as POINTER and set it to address of a structure you want to share with condition handler: "SET ABN-WB-TOKEN TO ADDRESS OF ABN-WS-COMM-AREA." In condition handler you define the same structure in the LINKAGE SECTION and then set its address to the one passed via TOKEN: "SET ADDRESS OF ABN-LS-COMM-AREA TO ABN-LB-TOKEN." Now both programs use the same structure which you can use as the communication area. In here we only pass RESUME POINT and a flag which indicates that an abend has occurred during record processing, but using this method you can easily share any type of and nearly any number of variables between condition handler and you programs.
Solution 3
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1703. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBEMPL END-EXEC. EXEC SQL INCLUDE EMTBSLRY END-EXEC. EXEC SQL INCLUDE EMTBTITL END-EXEC. EXEC SQL INCLUDE EMTBDPEM END-EXEC. 01 STA-WS-TIME. 05 STA-WZ-HOUR PIC 9(2). 05 STA-WZ-MINUTES PIC 9(2). 05 STA-WZ-SECONDS PIC 9(2). 05 STA-WZ-MILI PIC 9(2). 01 END-WS-TIME. 05 END-WZ-HOUR PIC 9(2). 05 END-WZ-MINUTES PIC 9(2). 05 END-WZ-SECONDS PIC 9(2). 05 END-WZ-MILI PIC 9(2). 01 STA-WB-COMP-TIME PIC S9(18) BINARY. 01 END-WB-COMP-TIME PIC S9(18) BINARY. 01 CUR-WS-DATE. 05 CUR-WZ-YEAR PIC 9(4). 05 CUR-WZ-MONTH PIC 9(2). 05 CUR-WZ-DAY PIC 9(2). 01 WE-SQLCODE PIC Z(3)9. 01 WT-ERROR-MSG PIC X(60) VALUE "X". 01 WT-DEPT-NO PIC X(4) VALUE "d008". 01 WB-READ-COUNTER PIC 9(9) BINARY. 01 WB-UPDATE-COUNTER PIC 9(9) BINARY VALUE 0. 01 WB-EMPL-SLRY-COUNTER PIC 9(4) BINARY. 01 WB-EMPL-TITL-COUNTER PIC 9(4) BINARY. 01 WB-EMPL-DPEM-COUNTER PIC 9(4) BINARY. 01 WT-TO-DATE-MARKER PIC X(10) VALUE "9999-01-01". 01 WZ-EMP-NO PIC 9(9). PROCEDURE DIVISION. MAIN-LOGIC. PERFORM INIT. PERFORM GET-RETIREE-FROM-DB2. PERFORM DISP-END-WS-TIME. PERFORM CLEANUP. STOP RUN. *----------------------------------------------------------------- INIT. ACCEPT STA-WS-TIME FROM TIME. EXEC SQL DECLARE C-EMPL CURSOR FOR SELECT EMTBEMPL.EMP_NO, BIRTH_DATE, FIRST_NAME, LAST_NAME FROM EMTBEMPL, EMTBDPEM WHERE EMTBEMPL.EMP_NO = EMTBDPEM.EMP_NO AND EMTBDPEM.DEPT_NO = :WT-DEPT-NO AND BIRTH_DATE < (CURRENT DATE - 66 YEARS) END-EXEC. EXEC SQL OPEN C-EMPL END-EXEC. EXEC SQL DECLARE C-SLRY CURSOR FOR SELECT SALARY FROM EMTBSLRY WHERE EMP_NO = :EMPL-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER FOR UPDATE OF TO_DATE WITH RS USE AND KEEP UPDATE LOCKS END-EXEC. EXEC SQL DECLARE C-TITL CURSOR FOR SELECT TITLE FROM EMTBTITL WHERE EMP_NO = :EMPL-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER FOR UPDATE OF TO_DATE WITH RS USE AND KEEP UPDATE LOCKS END-EXEC. EXEC SQL DECLARE C-DPEM CURSOR FOR SELECT DEPT_NO FROM EMTBDPEM WHERE EMP_NO = :EMPL-DB-EMP-NO AND TO_DATE = :WT-TO-DATE-MARKER FOR UPDATE OF TO_DATE WITH RS USE AND KEEP UPDATE LOCKS END-EXEC. *----------------------------------------------------------------- GET-RETIREE-FROM-DB2. INITIALIZE EMPL-DS. EXEC SQL FETCH NEXT FROM C-EMPL INTO :EMPL-DB-EMP-NO, :EMPL-DT-BIRTH-DATE, :EMPL-DS-FIRST-NAME, :EMPL-DS-LAST-NAME END-EXEC. PERFORM PROCESS-RETIREE-REC VARYING WB-READ-COUNTER FROM 1 BY 1 UNTIL SQLCODE NOT = 0. PERFORM CHECK-SQL. SUBTRACT 2 FROM WB-READ-COUNTER. DISPLAY "PROCESSING COMPLETED SUCCESSFULLY." DISPLAY WB-READ-COUNTER " EMPLOYEES CHECKED.". DISPLAY WB-UPDATE-COUNTER " RECORDS UPDATED.". *----------------------------------------------------------------- PROCESS-RETIREE-REC. EXEC SQL OPEN C-SLRY END-EXEC. EXEC SQL OPEN C-TITL END-EXEC. EXEC SQL OPEN C-DPEM END-EXEC. PERFORM UPDATE-EMPL-RECORDS. PERFORM DISPLAY-EMPLOYEE. EXEC SQL CLOSE C-SLRY END-EXEC. EXEC SQL CLOSE C-TITL END-EXEC. EXEC SQL CLOSE C-DPEM END-EXEC. EXEC SQL COMMIT END-EXEC. INITIALIZE EMPL-DS. EXEC SQL FETCH NEXT FROM C-EMPL INTO :EMPL-DB-EMP-NO, :EMPL-DT-BIRTH-DATE, :EMPL-DS-FIRST-NAME, :EMPL-DS-LAST-NAME END-EXEC. *----------------------------------------------------------------- UPDATE-EMPL-RECORDS. MOVE 0 TO WB-EMPL-SLRY-COUNTER. MOVE 0 TO WB-EMPL-TITL-COUNTER. MOVE 0 TO WB-EMPL-DPEM-COUNTER. INITIALIZE SLRY-DS. INITIALIZE TITL-DS. INITIALIZE DPEM-DS. EXEC SQL FETCH NEXT FROM C-SLRY INTO :SLRY-DB-SALARY END-EXEC. IF SQLCODE = 0 EXEC SQL UPDATE EMTBSLRY SET TO_DATE = DATE(:EMPL-DT-BIRTH-DATE) + 66 YEARS WHERE CURRENT OF C-SLRY END-EXEC PERFORM CHECK-SQL MOVE 1 TO WB-EMPL-SLRY-COUNTER END-IF. EXEC SQL FETCH NEXT FROM C-TITL INTO :TITL-DS-TITLE END-EXEC. IF SQLCODE = 0 EXEC SQL UPDATE EMTBTITL SET TO_DATE = DATE(:EMPL-DT-BIRTH-DATE) + 66 YEARS WHERE CURRENT OF C-TITL END-EXEC PERFORM CHECK-SQL MOVE 1 TO WB-EMPL-TITL-COUNTER END-IF. EXEC SQL FETCH NEXT FROM C-DPEM INTO :DPEM-DT-DEPT-NO END-EXEC. IF SQLCODE = 0 EXEC SQL UPDATE EMTBDPEM SET TO_DATE = DATE(:EMPL-DT-BIRTH-DATE) + 66 YEARS WHERE CURRENT OF C-DPEM END-EXEC PERFORM CHECK-SQL MOVE 1 TO WB-EMPL-DPEM-COUNTER END-IF. ADD WB-EMPL-SLRY-COUNTER TO WB-UPDATE-COUNTER. ADD WB-EMPL-TITL-COUNTER TO WB-UPDATE-COUNTER. ADD WB-EMPL-DPEM-COUNTER TO WB-UPDATE-COUNTER. *----------------------------------------------------------------- DISPLAY-EMPLOYEE. MOVE EMPL-DB-EMP-NO TO WZ-EMP-NO. DISPLAY "***********************************************". DISPLAY "PROCESSING EMPLOYEE RECORD NO: " WB-READ-COUNTER. DISPLAY "EMP ID: " WZ-EMP-NO ", EMP FNAME: " EMPL-DT-FIRST-NAME ", EMP LNAME: " EMPL-DT-LAST-NAME ", BIRTH DATE: " EMPL-DT-BIRTH-DATE. IF WB-EMPL-SLRY-COUNTER = 1 DISPLAY "SLRY TABLE UPDATED. " "SALARY: " SLRY-DB-SALARY END-IF. IF WB-EMPL-TITL-COUNTER = 1 DISPLAY "TITL TABLE UPDATED. " "TITLE: " TITL-DT-TITLE END-IF. IF WB-EMPL-DPEM-COUNTER = 1 DISPLAY "DPEM TABLE UPDATED. " "DEPARTMENT: " DPEM-DT-DEPT-NO END-IF. IF WB-EMPL-SLRY-COUNTER = 0 AND WB-EMPL-TITL-COUNTER = 0 AND WB-EMPL-DPEM-COUNTER = 0 DISPLAY "NO UPDATES NEEEDED" END-IF. *----------------------------------------------------------------- DISP-END-WS-TIME. DISPLAY "--------------------------------------". ACCEPT END-WS-TIME FROM TIME. DISPLAY "SQL STA TIME: " STA-WZ-HOUR ":" STA-WZ-MINUTES ":" STA-WZ-SECONDS "." STA-WZ-MILI. DISPLAY "SQL END TIME: " END-WZ-HOUR ":" END-WZ-MINUTES ":" END-WZ-SECONDS "." END-WZ-MILI. COMPUTE STA-WB-COMP-TIME = STA-WZ-MILI + STA-WZ-SECONDS * 100 + STA-WZ-MINUTES * 6000 + STA-WZ-HOUR * 360000. COMPUTE END-WB-COMP-TIME = END-WZ-MILI + END-WZ-SECONDS * 100 + END-WZ-MINUTES * 6000 + END-WZ-HOUR * 360000. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - STA-WB-COMP-TIME. IF END-WB-COMP-TIME < 0 ADD 8640000 TO END-WB-COMP-TIME. COMPUTE END-WZ-HOUR = END-WB-COMP-TIME / 360000. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - END-WZ-HOUR * 360000. COMPUTE END-WZ-MINUTES = END-WB-COMP-TIME / 6000. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - END-WZ-MINUTES * 6000. COMPUTE END-WZ-SECONDS = END-WB-COMP-TIME / 100. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - END-WZ-SECONDS * 100. COMPUTE END-WZ-MILI = END-WB-COMP-TIME. DISPLAY "SQL RUN TIME: " END-WZ-HOUR ":" END-WZ-MINUTES ":" END-WZ-SECONDS "." END-WZ-MILI. DISPLAY "--------------------------------------". *----------------------------------------------------------------- CHECK-SQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO WE-SQLCODE MOVE EMPL-DB-EMP-NO TO WZ-EMP-NO STRING "SQL ERROR OCCURED. SQL CODE: " WE-SQLCODE ", SQL STATE: " SQLSTATE ", EMPL ID: " WZ-EMP-NO SPACES DELIMITED BY SIZE INTO WT-ERROR-MSG END-STRING PERFORM CLEANUP END-IF. *----------------------------------------------------------------- CLEANUP. IF WT-ERROR-MSG NOT = "X" IF RETURN-CODE = 0 MOVE 16 TO RETURN-CODE END-IF DISPLAY "ERROR OCCURED. RC: " RETURN-CODE DISPLAY "ERROR MESSAGE: " WT-ERROR-MSG EXEC SQL ROLLBACK END-EXEC END-IF. EXEC SQL CLOSE C-EMPL END-EXEC. STOP RUN.
Comments: - This example demonstrates how to use FOR UPDATE & WHERE CURRENT OF clauses for positioned updates. This is a SQL constuct which can greatly improve performance in all cases where you need to read and then update the same record. In such case, DB2 already knows where the record is and it doesn't have to search for it again to update it. - Notice that three cursors for table updates are closed and opened after every read. The entire point of cursors is to allow sequential read of a result set, so obviously, we cannot modify the query, since it would generate a new result set. In this example, EMP-NO changes each query and because of that we need to open and close cursors each time EMP-NO changes. In other words, we don't use cursors here to read a result set, only to have pointers to records which needs to be updated. - Also, notice that this program will work fine only is a single row match selection criteria in SLRY, TITL, and DPEM tables. This is ok since data logic defines there is only one such record in the table, but in other cases, you may need to consider the situation where multiple rows are returned as a result of such queries. - COMMIT in such programs should be always issued after processing of a single EMP-ID, so after operation in all four tables for single ID are done. This way you minimize locks durations. - When using FOR UPDATE clause you should ensure proper record locking. "WITH RS USE AND KEEP UPDATE LOCKS" options can be used to retain RS lock between SELECT and UPDATE statements of the same record. Performance: Below you can see results from three versions of the same program. The first versions issues only UPDATE statements and doesn't SELECTs any data from SLRY, TITL, or DPEM table. The second query runs the same 3xUPDATE statements and additionally fetches the data about updated records with separate SELECT statements. The third version does the same thing as the second one but with the use of FOR UPDATE clause. - UPDATEs only: 01:45:22.45 - Separate SELECTs & UPDATEs: 03:10:13.05 - SELECT with FOR UPDATE: 01:01:31.63 As you can see using SELECT with FOR UPDATE is even faster than running UPDATEs only, without fetching any data from tables. The reason for that is, most likely, that UPDATE statement cannot use indexes or cannot utilize them as effectively as a SELECT statement. When you use SELECT with FOR UPDATE, you utilize SELECT speed for finding rows and have a ready to use cursor for an UPDATE statement.
Solution 4
COBOL code:
IDENTIFICATION DIVISION. PROGRAM-ID. MP1704. ENVIRONMENT DIVISION. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMTBEMP2 END-EXEC. 01 STA-WS-TIME. 05 STA-WZ-HOUR PIC 9(2). 05 STA-WZ-MINUTES PIC 9(2). 05 STA-WZ-SECONDS PIC 9(2). 05 STA-WZ-MILI PIC 9(2). 01 END-WS-TIME. 05 END-WZ-HOUR PIC 9(2). 05 END-WZ-MINUTES PIC 9(2). 05 END-WZ-SECONDS PIC 9(2). 05 END-WZ-MILI PIC 9(2). 01 STA-WB-COMP-TIME PIC S9(18) BINARY. 01 END-WB-COMP-TIME PIC S9(18) BINARY. 01 WE-SQLCODE PIC Z(4)9. 01 WT-ERROR-MSG PIC X(60) VALUE "X". 01 WT-1988-STA PIC X(10) VALUE '1988-01-01'. 01 WT-1988-END PIC X(10) VALUE '1988-12-31'. 01 WT-XXX-NAME PIC X(3) VALUE 'XXX'. 01 WB-K1 PIC 9(9) BINARY. 01 WB-EMPL-COUNT PIC 9(9) BINARY. 01 WB-ROWS-IN-SET PIC 9(9) BINARY. 01 WB-FETCH-END PIC S9(9) BINARY. PROCEDURE DIVISION. MAIN-LOGIC. PERFORM INIT. PERFORM ANONYMIZE-NONACTIVE-EMPLOYEES. PERFORM DISP-END-WS-TIME. PERFORM CLEANUP. STOP RUN. *----------------------------------------------------------------- INIT. ACCEPT STA-WS-TIME FROM TIME. EXEC SQL DECLARE CSR1 CURSOR WITH ROWSET POSITIONING FOR SELECT EMP_NO, FIRST_NAME, LAST_NAME, HIRE_DATE FROM EMTBEMPL WHERE HIRE_DATE BETWEEN :WT-1988-STA AND :WT-1988-END FOR UPDATE OF FIRST_NAME, LAST_NAME WITH RS USE AND KEEP UPDATE LOCKS END-EXEC. EXEC SQL OPEN CSR1 END-EXEC. *----------------------------------------------------------------- ANONYMIZE-NONACTIVE-EMPLOYEES. MOVE 0 TO WB-EMPL-COUNT. PERFORM PROCESS-ROWSET UNTIL WB-FETCH-END = 100. DISPLAY 'PROCESSING COMPLETE.'. DISPLAY 'RECORDS UPDATED: ' WB-EMPL-COUNT. EXEC SQL COMMIT END-EXEC. *----------------------------------------------------------------- PROCESS-ROWSET. INITIALIZE EMPL-DS. EXEC SQL FETCH NEXT ROWSET FROM CSR1 FOR 200 ROWS INTO :EMPL-DB-EMP-NO, :EMPL-DS-FIRST-NAME, :EMPL-DS-LAST-NAME, :EMPL-DT-HIRE-DATE END-EXEC. MOVE SQLCODE TO WB-FETCH-END. PERFORM CHECK-SQL. MOVE SQLERRD(3) TO WB-ROWS-IN-SET. EXEC SQL UPDATE EMTBEMPL SET FIRST_NAME = :WT-XXX-NAME, LAST_NAME = :WT-XXX-NAME WHERE CURRENT OF CSR1 END-EXEC. PERFORM CHECK-SQL. PERFORM VARYING WB-K1 FROM 1 BY 1 UNTIL WB-K1 > WB-ROWS-IN-SET ADD 1 TO WB-EMPL-COUNT DISPLAY 'RECORD: ' WB-EMPL-COUNT ' UPDATED' ', EMP_NO: ' EMPL-DB-EMP-NO(WB-K1) ', F_NAME: ' EMPL-DS-FIRST-NAME(WB-K1) ', L_NAME: ' EMPL-DS-LAST-NAME(WB-K1) ', HIRED: ' EMPL-DT-HIRE-DATE(WB-K1) END-PERFORM. *----------------------------------------------------------------- DISP-END-WS-TIME. DISPLAY "--------------------------------------". ACCEPT END-WS-TIME FROM TIME. DISPLAY "SQL STA TIME: " STA-WZ-HOUR ":" STA-WZ-MINUTES ":" STA-WZ-SECONDS "." STA-WZ-MILI. DISPLAY "SQL END TIME: " END-WZ-HOUR ":" END-WZ-MINUTES ":" END-WZ-SECONDS "." END-WZ-MILI. COMPUTE STA-WB-COMP-TIME = STA-WZ-MILI + STA-WZ-SECONDS * 100 + STA-WZ-MINUTES * 6000 + STA-WZ-HOUR * 360000. COMPUTE END-WB-COMP-TIME = END-WZ-MILI + END-WZ-SECONDS * 100 + END-WZ-MINUTES * 6000 + END-WZ-HOUR * 360000. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - STA-WB-COMP-TIME. IF END-WB-COMP-TIME < 0 ADD 8640000 TO END-WB-COMP-TIME. COMPUTE END-WZ-HOUR = END-WB-COMP-TIME / 360000. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - END-WZ-HOUR * 360000. COMPUTE END-WZ-MINUTES = END-WB-COMP-TIME / 6000. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - END-WZ-MINUTES * 6000. COMPUTE END-WZ-SECONDS = END-WB-COMP-TIME / 100. COMPUTE END-WB-COMP-TIME = END-WB-COMP-TIME - END-WZ-SECONDS * 100. COMPUTE END-WZ-MILI = END-WB-COMP-TIME. DISPLAY "SQL RUN TIME: " END-WZ-HOUR ":" END-WZ-MINUTES ":" END-WZ-SECONDS "." END-WZ-MILI. DISPLAY "--------------------------------------". *----------------------------------------------------------------- CHECK-SQL. IF SQLCODE NOT = 0 AND SQLCODE NOT = 100 MOVE SQLCODE TO WE-SQLCODE STRING "SQL ERROR OCCURED. SQL CODE: " WE-SQLCODE ", SQL STATE: " SQLSTATE SPACES DELIMITED BY SIZE INTO WT-ERROR-MSG END-STRING PERFORM CLEANUP END-IF. *----------------------------------------------------------------- CLEANUP. IF WT-ERROR-MSG NOT = "X" IF RETURN-CODE = 0 MOVE 16 TO RETURN-CODE END-IF DISPLAY "ERROR OCCURED. RC: " RETURN-CODE DISPLAY "ERROR MESSAGE: " WT-ERROR-MSG EXEC SQL ROLLBACK END-EXEC END-IF. EXEC SQL CLOSE CSR1 END-EXEC. STOP RUN.
Comments: - In this example, you can see how you can use FOR UPDATE clause for speeding up UPDATE operation of rows earlier read with multi-row fetch. In this particular case, it enabled us to speed up program processing by 44%. - Still, using FOR UPDATE with multi-row fetch can be problematic. First of all, all rows must be updated with the same value. Also, you cannot this method if SELECT statement queries multiple tables. Performance: - Separate SELECT & UPDATE: 00:00:34.73 - SELECT with FOR UPDATE: 00:00:19.69